I dette kapitel vil vi diskutere cache-kohærensprotokoller til håndtering af multicache-inkonsistensproblemer.
Cache-kohærensproblemet
I et multiprocessorsystem kan der forekomme datainkonsistens mellem tilstødende niveauer eller inden for det samme niveau i hukommelseshierarkiet. F.eks. kan cachen og hovedhukommelsen have inkonsekvente kopier af det samme objekt.
Da flere processorer arbejder parallelt og uafhængigt af hinanden flere caches kan have forskellige kopier af den samme hukommelsesblok, skaber dette cache-kohærensproblem. Cache-kohærensordninger hjælper med at undgå dette problem ved at opretholde en ensartet tilstand for hver cacheblok af data.
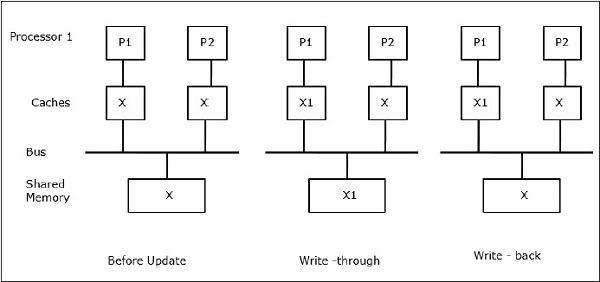
Lad X være et element af delte data, som er blevet refereret af to processorer, P1 og P2. I begyndelsen er tre kopier af X konsistente. Hvis processoren P1 skriver en ny data X1 ind i cachen ved hjælp af write-through-politikken, vil den samme kopi straks blive skrevet ind i den delte hukommelse. I dette tilfælde opstår der uoverensstemmelse mellem cachehukommelsen og hovedhukommelsen. Når der anvendes en write-back-politik, vil hovedhukommelsen blive opdateret, når de ændrede data i cachen erstattes eller ugyldiggøres.
Generelt er der tre kilder til inkonsistensproblemer –
- Deling af skrivbare data
- Procesmigration
- I/O-aktivitet
Snoopy-busprotokoller
Snoopy-protokoller opnår datakonsistens mellem cachehukommelsen og den delte hukommelse gennem et busbaseret hukommelsessystem. Write-invalidate- og write-update-politikker anvendes til at opretholde cache-konsistens.
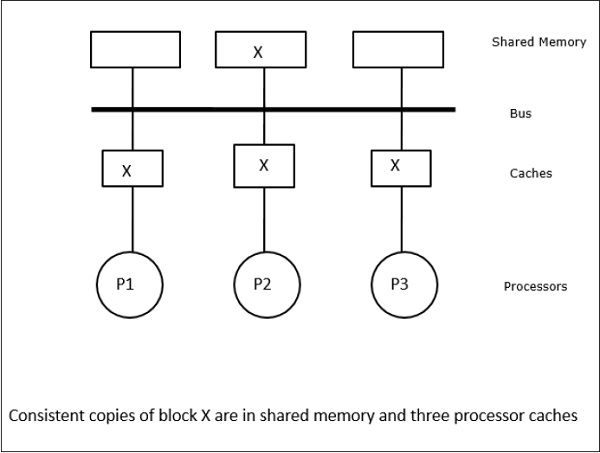
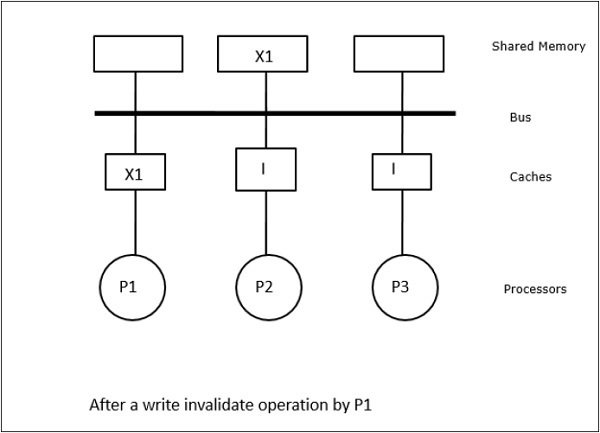
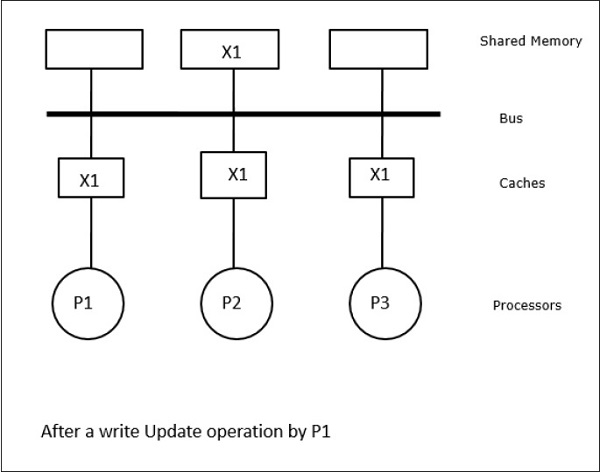
I dette tilfælde har vi tre processorer P1, P2 og P3, som har en konsistent kopi af dataelementet “X” i deres lokale cache-hukommelse og i den delte hukommelse (figur-a). Processor P1 skriver X1 i sin cachehukommelse ved hjælp af en skriveinvalideringsprotokol. Så alle andre kopier bliver ugyldiggjort via bussen. Det betegnes med “I” (figur b). Invaliderede blokke er også kendt som “beskidte”, dvs. de bør ikke bruges. Write-update-protokollen opdaterer alle cache-kopier via bussen. Ved at bruge write back cache opdateres hukommelseskopien også (figur-c).
Cache Events and Actions
Følgende hændelser og handlinger opstår ved udførelsen af memory-access- og invalideringskommandoer –
-
Read-miss – Når en processor ønsker at læse en blok, og den ikke er i cachen, opstår der en read-miss. Dette igangsætter en bus-læseoperation. Hvis der ikke findes nogen beskidt kopi, leverer hovedhukommelsen, der har en konsistent kopi, en kopi til den anmodende cachehukommelse. Hvis der findes en beskidt kopi i en fjerntliggende cache-hukommelse, vil denne cache-hukommelse tilbageholde hovedhukommelsen og sende en kopi til den anmodende cache-hukommelse. I begge tilfælde vil cachekopien gå ind i den gyldige tilstand efter en read miss.
-
Write-hit – Hvis kopien er i dirty eller reserveret tilstand, skrives der lokalt, og den nye tilstand er dirty. Hvis den nye tilstand er gyldig, udsendes write-invalidate-kommandoen til alle caches, hvorved deres kopier bliver ugyldige. Når den delte hukommelse skrives igennem, er den resulterende tilstand reserveret efter denne første skrivning.
-
Write-miss – Hvis en processor undlader at skrive i den lokale cachehukommelse, skal kopien enten komme fra hovedhukommelsen eller fra en fjerncachemememememory med en dirty block. Dette gøres ved at sende en read-invalidate-kommando, som ugyldiggør alle cachekopier. Derefter opdateres den lokale kopi med beskidt tilstand.
-
Read-hit – Read-hit udføres altid i den lokale cachehukommelse uden at forårsage en tilstandsovergang eller bruge snoopy-bussen til invalidering.
-
Block replacement – Når en kopi er beskidt, skal den skrives tilbage til hovedhukommelsen ved hjælp af block replacement-metoden. Men når kopien enten er i enten gyldig eller reserveret eller ugyldig tilstand, finder der ingen udskiftning sted.
Directory-Based Protocols
Ved brug af et flertrinsnetværk til opbygning af en stor multiprocessor med hundredvis af processorer skal snoopy cache-protokollerne ændres, så de passer til netværkets muligheder. Da Broadcasting er meget dyrt at udføre i et flertrinsnetværk, sendes konsistenskommandoerne kun til de caches, der har en kopi af blokken. Dette er grunden til udviklingen af mappebaserede protokoller til netværksforbundne multiprocessorer.
I et system med mappebaserede protokoller placeres de data, der skal deles, i en fælles mappe, som opretholder sammenhængen mellem cachesystemerne. Her fungerer mappen som et filter, hvor processorerne beder om tilladelse til at indlæse en post fra den primære hukommelse til deres cache-hukommelse. Hvis en post ændres, opdaterer kataloget den enten eller ugyldiggør de andre caches med den pågældende post.
Hardwaresynkroniseringsmekanismer
Synkronisering er en særlig form for kommunikation, hvor der i stedet for datakontrol udveksles oplysninger mellem kommunikerende processer, der befinder sig i de samme eller forskellige processorer.
Multiprocessorsystemer anvender hardwaremekanismer til at gennemføre synkroniseringsoperationer på lavt niveau. De fleste multiprocessorer har hardwaremekanismer til at pålægge atomare operationer som f.eks. hukommelseslæsning, -skrivning eller læse-ændre-skrive-operationer for at implementere nogle synkroniseringspræmier. Ud over atomiske hukommelsesoperationer anvendes også nogle interprocessorinterrupts til synkroniseringsformål.
Cache-kohærens i maskiner med delt hukommelse
Holdelse af cache-kohærens er et problem i multiprocessorsystemer, når processorerne indeholder lokal cache-hukommelse. Der opstår let uoverensstemmelse mellem data mellem forskellige caches i dette system.
De vigtigste problemområder er –
- Deling af skrivbare data
- Procesmigration
- I/O-aktivitet
Deling af skrivbare data
Når to processorer (P1 og P2) har samme dataelement (X) i deres lokale caches, og den ene proces (P1) skriver til dataelementet (X), da cachen er en lokal cache, der skrives gennem P1’s lokale cache, opdateres hovedhukommelsen også. Når P2 nu forsøger at læse dataelementet (X), finder den ikke X, fordi dataelementet i P2’s cache er blevet forældet.
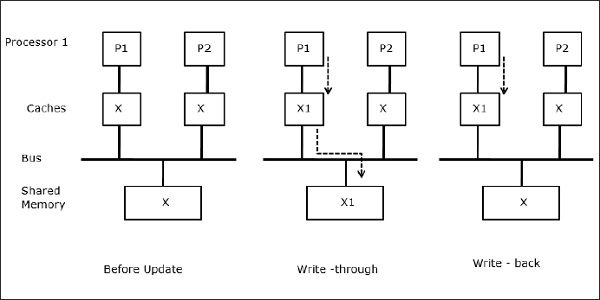
Procesmigration
I den første fase har P1’s cache dataelement X, mens P2 ikke har noget. En proces på P2 skriver først på X og migrerer derefter til P1. Nu begynder processen at læse dataelement X, men da processoren P1 har forældede data, kan processen ikke læse dem. Så en proces på P1 skriver til dataelementet X og flytter derefter til P2. Efter migrationen begynder en proces på P2 at læse dataelementet X, men den finder en forældet version af X i hovedhukommelsen.
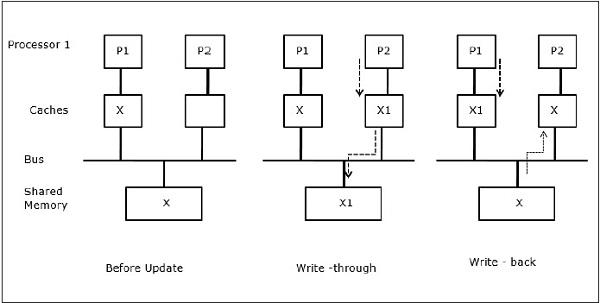
I/O-aktivitet
Som illustreret i figuren tilføjes en I/O-enhed til bussen i en to-processor-multiprocessorarkitektur. I begyndelsen indeholder begge cacher’er dataelementet X. Når I/O-enheden modtager et nyt element X, lagrer den det nye element direkte i hovedhukommelsen. Når enten P1 eller P2 (antaget P1) nu forsøger at læse element X, får den en forældet kopi. Så P1 skriver til element X. Hvis I/O-enheden nu forsøger at sende X, får den en forældet kopi.
Uniform Memory Access (UMA)
Uniform Memory Access (UMA)
Arkitekturen betyder, at den fælles hukommelse er den samme for alle processorer i systemet. Populære klasser af UMA-maskiner, som almindeligvis anvendes til (fil-)servere, er de såkaldte symmetriske multiprocessorer (SMP’er). I en SMP er alle systemressourcer som hukommelse, diske, andre I/O-enheder osv. tilgængelige for processorerne på en ensartet måde.
Non-Uniform Memory Access (NUMA)
I en NUMA-arkitektur er der flere SMP-klynger, der har et internt indirekte/delte netværk, som er forbundet i et skalerbart message-passing-netværk. NUMA-arkitekturen er således en logisk delt fysisk distribueret hukommelsesarkitektur.
I en NUMA-maskine bestemmer en processors cache-controller, om en hukommelsesreference er lokal i SMP’ens hukommelse eller ekstern. For at reducere antallet af fjernhukommelsestilgange anvender NUMA-arkitekturer normalt caching-processorer, der kan cache de eksterne data. Men når der er tale om caches, skal cache-kohærensen opretholdes. Disse systemer er derfor også kendt som CC-NUMA (Cache Coherent NUMA).
Cache Only Memory Architecture (COMA)
COMA-maskiner ligner NUMA-maskiner, med den eneste forskel, at hovedhukommelserne i COMA-maskiner fungerer som direkte tilknyttede eller sæt-associerende caches. Datablokkene hashedes til en placering i DRAM-cachen i overensstemmelse med deres adresser. Data, der hentes eksternt, er faktisk gemt i den lokale hovedhukommelse. Desuden har datablokke ikke en fast hjemsted, de kan frit bevæge sig rundt i systemet.
COMA-arkitekturer har for det meste et hierarkisk message-passing-netværk. En switch i et sådant træ indeholder en mappe med dataelementer som sit undertræ. Da data ikke har nogen hjemsted, skal der eksplicit søges efter dem. Det betyder, at en fjernadgang kræver, at der skal foretages en gennemkørsel langs centralerne i træet for at søge i deres kataloger efter de ønskede data. Så hvis en switch i nettet modtager flere anmodninger fra sit undertræ om de samme data, kombinerer den dem til en enkelt anmodning, som sendes til switchens overordnede. Når de ønskede data vender tilbage, sender switchen flere kopier af dem ned i sit undertræ.
COMA versus CC-NUMA
Nedenstående er forskellene mellem COMA og CC-NUMA.
-
COMA har tendens til at være mere fleksibel end CC-NUMA, fordi COMA på gennemsigtig vis understøtter migration og replikering af data uden brug af operativsystemet.
-
COMA-maskiner er dyre og komplekse at bygge, fordi de kræver ikke-standardiseret hukommelseshåndteringshardware, og fordi kohærensprotokollen er sværere at implementere.
-
Fjerntilgangene i COMA er ofte langsommere end i CC-NUMA, da trænetværket skal gennemkøres for at finde dataene.