I henhold til definitionen i Wikipedia består Anscombes kvartet af fire datasæt, der har næsten identiske simple statistiske egenskaber, men som alligevel ser meget forskellige ud, når de vises i grafer. Hvert datasæt består af elleve (x,y)-punkter. De blev konstrueret i 1973 af statistikeren Francis Anscombe for at demonstrere både vigtigheden af at tegne grafer over data, før man analyserer dem, og effekten af outliers på statistiske egenskaber.
En simpel forståelse:
Engang fandt Francis John “Frank” Anscombe, der var en højt anset statistiker, 4 sæt af 11 datapunkter i sin drøm og bad rådet som sit sidste ønske om at plotte disse punkter. Disse 4 sæt af 11 datapunkter er angivet nedenfor.
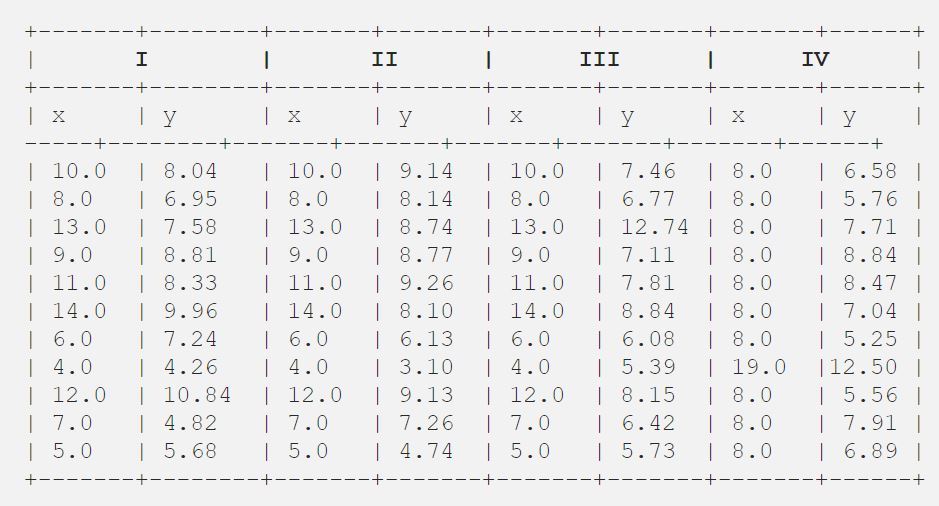
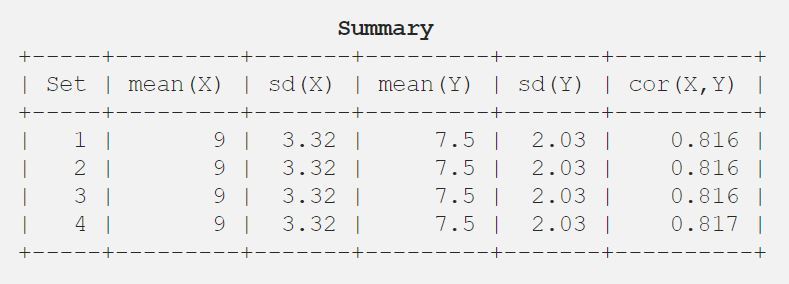
Derpå analyserede rådet dem udelukkende ved hjælp af beskrivende statistik og fandt middelværdien, standardafvigelsen og korrelationen mellem x og y.
Download venligst csv-filen her.
Kode:
Kode: Python-program til at finde middelværdi, standardafvigelse, og korrelationen mellem x og y
import pandas as pd import statistics from scipy.stats import pearsonr df = pd.read_csv("anscombe.csv") list1 = df list2 = df print('%.1f' % statistics.mean(list1)) print('%.2f' % statistics.stdev(list1)) print('%.1f' % statistics.mean(list2)) print('%.2f' % statistics.stdev(list2)) corr, _ = pearsonr(list1, list2) print('%.3f' % corr) Output:
9.03.327.52.030.816
Så lad mig vise dig resultatet i en tabel for bedre at forstå det.
Code: Python program to plot scatter plot
from matplotlib import pyplot as plt import pandas as pd df = pd.read_csv("anscombe.csv") list1 = df list2 = df plt.scatter(list1, list2) plt.show() For regression line refer this.
Output:
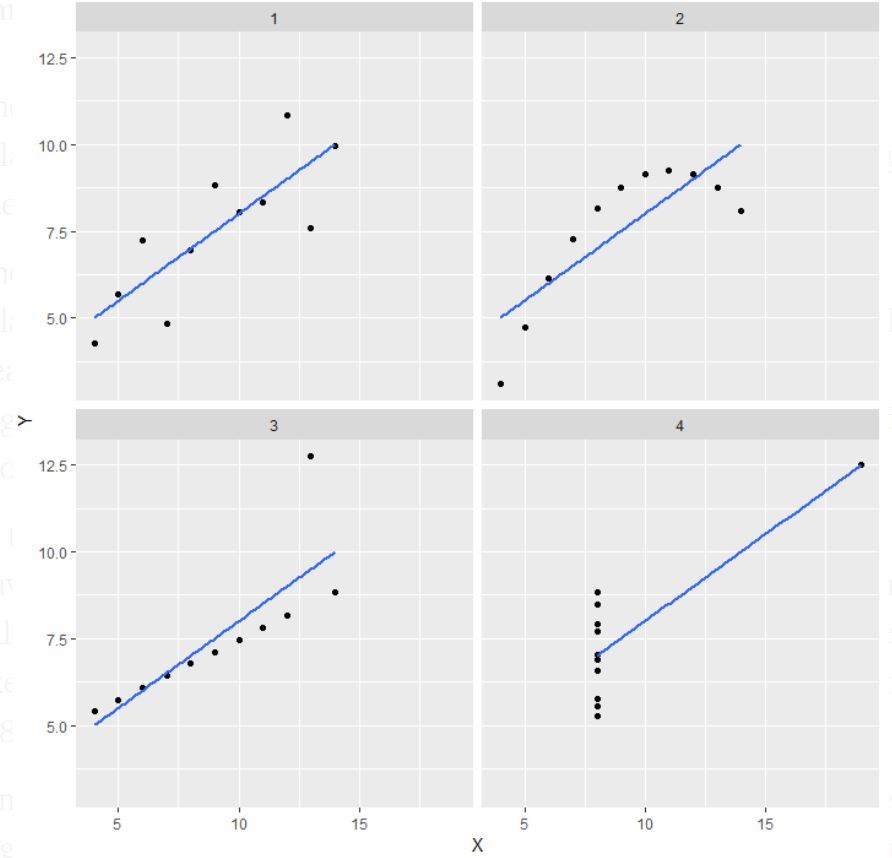
Note: Det nævnes i definitionen, at Anscombes kvartet omfatter fire datasæt, der har næsten identiske simple statistiske egenskaber, men som alligevel fremstår meget forskellige, når de vises i grafer.
Forklaring af dette output:
- I det første(øverst til venstre), hvis man ser på spredningsdiagrammet, vil man se, at der tilsyneladende er en lineær sammenhæng mellem x og y.
- I det andet(øverst til højre), hvis man ser på denne figur, kan man konkludere, at der er en ikke-lineær sammenhæng mellem x og y.
- I den tredje(nederst til venstre) kan man sige, når der er en perfekt lineær sammenhæng for alle datapunkterne undtagen et, som ser ud til at være en outlier, som er angivet være langt væk fra denne linje.
- Slutteligt viser den fjerde(nederst til højre) et eksempel, hvor et enkelt punkt med høj løftestangseffekt er nok til at give en høj korrelationskoefficient.
Anvendelse:
Kvartetten bruges stadig ofte til at illustrere vigtigheden af at se på et datasæt grafisk, før man begynder at analysere efter en bestemt type sammenhæng, og det utilstrækkelige i grundlæggende statistiske egenskaber til beskrivelse af realistiske datasæt.