Beim Schreiben von Single-Page-Anwendungen ist es einfach und natürlich, sich in dem Versuch zu verfangen, die ideale Erfahrung für die häufigste Art von Benutzern zu schaffen – andere Menschen wie wir selbst. Diese aggressive Konzentration auf eine bestimmte Art von Besuchern unserer Website lässt oft eine andere wichtige Gruppe außen vor – die Crawler und Bots, die von Suchmaschinen wie Google verwendet werden. Dieser Leitfaden zeigt, wie einige einfach zu implementierende Best Practices und eine Umstellung auf serverseitiges Rendering Ihrer Anwendung das Beste aus beiden Welten geben können, wenn es um SPA-Benutzererfahrung und SEO geht.
Voraussetzungen
Eine funktionierende Kenntnis von Angular 5+ wird vorausgesetzt. Einige Teile des Leitfadens befassen sich mit Angular 6, aber das Wissen darüber ist nicht unbedingt erforderlich.
Viele der unbeabsichtigten SEO-Fehler, die wir machen, kommen von der Denkweise, dass wir Webanwendungen und nicht Websites bauen. Worin besteht der Unterschied? Es ist eine subjektive Unterscheidung, aber ich würde sagen, dass der Schwerpunkt der Bemühungen folgendermaßen aussieht:
- Webanwendungen konzentrieren sich auf natürliche und intuitive Interaktionen für die Benutzer
- Websites konzentrieren sich darauf, Informationen allgemein zugänglich zu machen
Aber diese beiden Konzepte müssen sich nicht gegenseitig ausschließen! Indem wir uns einfach auf die Regeln der Website-Entwicklung besinnen, können wir das elegante Erscheinungsbild von SPAs beibehalten und die Informationen an den richtigen Stellen platzieren, um eine ideale Website für Crawler zu erstellen.
Verstecken Sie den Inhalt nicht hinter Interaktionen
Ein Grundsatz, den Sie bei der Gestaltung von Komponenten berücksichtigen sollten, ist, dass Crawler ziemlich dumm sind. Sie werden auf Ihre Anker klicken, aber sie werden nicht wahllos über Elemente streichen oder auf ein div klicken, nur weil auf dessen Inhalt „Read More“ steht. Dies steht im Widerspruch zu Angular, wo eine gängige Praxis zum Ausblenden von Informationen darin besteht, sie „auszublenden“. Und oft macht das auch Sinn! Wir verwenden diese Praxis, um die Anwendungsleistung zu verbessern, indem wir potenziell schwergewichtige Komponenten nicht in einem nicht sichtbaren Teil der Seite unterbringen.
Das bedeutet jedoch, dass, wenn Sie Inhalte auf Ihrer Seite durch clevere Interaktionen verstecken, die Chancen hoch sind, dass ein Crawler diese Inhalte nie zu Gesicht bekommt. Sie können dies abmildern, indem Sie einfach CSS und nicht *ngif verwenden, um diese Art von Inhalten zu verbergen. Natürlich werden intelligente Crawler bemerken, dass der Text versteckt ist, und er wird wahrscheinlich als weniger wichtig eingestuft als sichtbarer Text. Dies ist jedoch besser, als wenn der Text im DOM überhaupt nicht zugänglich wäre. Ein Beispiel für diesen Ansatz sieht so aus:
Erstelle keine „virtuellen Anker“
Die folgende Komponente zeigt ein Anti-Muster, das ich häufig in Angular-Anwendungen sehe und das ich „virtuelle Anker“ nenne:
Grundsätzlich ist es so, dass ein Klick-Handler an etwas wie einen <Button> oder <div>-Tag angehängt ist und dieser Handler eine gewisse Logik ausführt und dann den importierten Angular-Router verwendet, um zu einer anderen Seite zu navigieren. Dies ist aus zwei Gründen problematisch:
- Crawler werden wahrscheinlich nicht auf diese Art von Elementen klicken, und selbst wenn sie es tun, werden sie keine Verbindung zwischen der Quell- und Zielseite herstellen.
- Dies verhindert die sehr bequeme Funktion „In einem neuen Tab öffnen“, die Browser nativ für tatsächliche Anker-Tags bereitstellen.
Anstatt virtuelle Anker zu verwenden, verwenden Sie einen tatsächlichen <a>-Tag mit der Routerlink-Direktive. Wenn Sie vor der Navigation eine zusätzliche Logik ausführen müssen, können Sie immer noch einen Click-Handler zum Anker-Tag hinzufügen.
Vergessen Sie nicht die Überschriften
Eines der Prinzipien einer guten Suchmaschinenoptimierung ist die Festlegung der relativen Wichtigkeit verschiedener Texte auf einer Seite. Ein wichtiges Hilfsmittel im Werkzeugkasten des Webentwicklers sind Überschriften. Häufig werden Überschriften beim Entwurf der Komponentenhierarchie einer Angular-Anwendung völlig vergessen; ob sie enthalten sind oder nicht, macht im Endprodukt keinen visuellen Unterschied. Aber das ist etwas, das Sie berücksichtigen müssen, um sicherzustellen, dass Crawler sich auf die richtigen Teile Ihrer Informationen konzentrieren. Ziehen Sie also die Verwendung von Überschriften-Tags in Betracht, wenn dies sinnvoll ist. Achten Sie jedoch darauf, dass Komponenten, die Überschriften-Tags enthalten, nicht so angeordnet werden können, dass ein <h1> innerhalb eines <h2> erscheint.
Machen Sie „Suchergebnisseiten“ verlinkbar
Um noch einmal auf das Prinzip zurückzukommen, wie Crawler dumm sind – betrachten Sie eine Suchseite für eine Widget-Firma. Ein Crawler wird keine Texteingabe in einem Formular sehen und etwas wie „Toronto Widgets“ eingeben. Um Crawlern Suchergebnisse zur Verfügung zu stellen, muss Folgendes getan werden:
- Eine Suchseite muss so eingerichtet werden, dass Suchparameter über den Pfad und/oder die Abfrage akzeptiert werden.
- Links zu spezifischen Suchanfragen, von denen Sie glauben, dass sie für den Crawler interessant sein könnten, müssen der Sitemap oder als Ankerlinks auf anderen Seiten der Website hinzugefügt werden.
Die Strategie rund um Punkt #2 liegt außerhalb des Rahmens dieses Artikels (einige hilfreiche Ressourcen sind https://yoast.com/internal-linking-for-seo-why-and-how/ und https://moz.com/learn/seo/internal-link). Wichtig ist, dass die Suchkomponenten und -seiten unter Berücksichtigung von Punkt 1 entworfen werden, so dass Sie die Flexibilität haben, einen Link zu jeder möglichen Art von Suche zu erstellen, so dass er überall eingefügt werden kann. Das bedeutet, dass Sie ActivatedRoute importieren und auf Änderungen des Pfades und der Abfrageparameter reagieren müssen, um die Suchergebnisse auf Ihrer Seite zu steuern, anstatt sich nur auf Ihre Abfrage- und Filterkomponenten auf der Seite zu verlassen.
Machen Sie die Paginierung verlinkbar
Während wir gerade beim Thema Suchseiten sind, ist es wichtig, sicherzustellen, dass die Paginierung korrekt gehandhabt wird, so dass Crawler auf jede einzelne Seite Ihrer Suchergebnisse zugreifen können, wenn sie dies wünschen. Es gibt einige bewährte Verfahren, die Sie befolgen können, um dies zu gewährleisten.
Um frühere Punkte zu wiederholen: Verwenden Sie keine „virtuellen Anker“ für Ihre „nächsten“, „vorherigen“ und „Seitenzahl“-Links. Wenn ein Crawler diese nicht als Anker erkennen kann, wird er sich möglicherweise nie etwas anderes als Ihre erste Seite ansehen. Verwenden Sie für diese Links echte <a>-Tags mit RouterLink. Fügen Sie außerdem die Paginierung als optionalen Teil Ihrer verlinkbaren Such-URLs ein – dies geschieht oft in Form eines page=-Abfrageparameters.
Sie können Crawlern zusätzliche Hinweise auf die Paginierung Ihrer Website geben, indem Sie relative „prev“/“next“ <link>-Tags hinzufügen. Eine Erklärung, warum diese nützlich sein können, finden Sie unter: https://webmasters.googleblog.com/2011/09/pagination-with-relnext-and-relprev.html. Hier ist ein Beispiel für einen Dienst, der diese <link>-Tags auf Angular-freundliche Weise automatisch verwalten kann:
Dynamische Metadaten einbinden
Eines der ersten Dinge, die wir bei einer neuen Angular-Anwendung tun, ist die Anpassung der index.html-Datei vor – das Setzen des Favicons, das Hinzufügen von responsiven Meta-Tags und höchstwahrscheinlich das Einstellen des Inhalts der Tags <title> und <meta name=“description“> auf sinnvolle Standardwerte für Ihre Anwendung. Aber wenn Sie sich dafür interessieren, wie Ihre Seiten in den Suchergebnissen erscheinen, können Sie es nicht dabei belassen. Auf jeder Route Ihrer Anwendung sollten Sie die Tags title und description dynamisch so einstellen, dass sie zum Seiteninhalt passen. Dies hilft nicht nur den Crawlern, sondern auch den Nutzern, da sie informative Browser-Tab-Titel, Lesezeichen und Vorschaudaten sehen können, wenn sie einen Link in sozialen Medien teilen. Das folgende Snippet zeigt, wie Sie diese auf Angular-freundliche Weise mithilfe der Meta- und Title-Klassen aktualisieren können:
Testen Sie, ob Crawler Ihren Code beschädigen
Einige Bibliotheken oder SDKs von Drittanbietern werden entweder heruntergefahren oder können nicht von ihrem Hosting-Provider geladen werden, wenn User-Agents, die zu Suchmaschinen-Crawlern gehören, erkannt werden. Wenn ein Teil Ihrer Funktionalität von diesen Abhängigkeiten abhängt, sollten Sie einen Fallback für Abhängigkeiten bereitstellen, die Crawler nicht zulassen. Zumindest sollte Ihre Anwendung in diesen Fällen nicht den Rendering-Prozess des Clients zum Absturz bringen, sondern sich sanft zurückentwickeln. Ein hervorragendes Tool zum Testen der Interaktion Ihres Codes mit Crawlern ist die Google Mobile Friendly-Testseite: https://search.google.com/test/mobile-friendly. Achten Sie auf Ausgaben wie diese, die darauf hinweisen, dass dem Crawler der Zugriff auf ein SDK verwehrt wird:

Reduzierung der Bundle-Größe mit Angular 6
Die Bundle-Größe in Angular-Anwendungen ist ein bekanntes Problem, aber es gibt viele Optimierungen, die ein Entwickler vornehmen kann, um es abzumildern, einschließlich der Verwendung von AOT-Builds und einer konservativen Einbindung von Drittanbieter-Bibliotheken. Um jedoch die kleinstmöglichen Angular-Bundles zu erhalten, ist heute ein Upgrade auf Angular 6 erforderlich. Der Grund dafür ist das erforderliche parallele Upgrade auf RXJS 6, das erhebliche Verbesserungen bei der Fähigkeit zum Schütteln des Baums bietet. Um diese Verbesserung tatsächlich zu erhalten, gibt es einige harte Anforderungen für Ihre Anwendung:
- Entfernen Sie die rxjs-compat-Bibliothek (die standardmäßig im Angular 6-Upgrade-Prozess hinzugefügt wird) – diese Bibliothek macht Ihren Code abwärtskompatibel mit RXJS 5, aber vereitelt die Tree-Shaking-Verbesserungen.
- Stellen Sie sicher, dass alle Abhängigkeiten auf Angular 6 verweisen und nicht die rxjs-compat-Bibliothek verwenden.
- Importieren Sie die RXJS-Operatoren einzeln und nicht im Ganzen, um sicherzustellen, dass Tree-Shaking seine Arbeit tun kann. Siehe https://github.com/ReactiveX/rxjs/blob/master/docs_app/content/guide/v6/migration.md für eine vollständige Anleitung zur Migration.
Server Rendering
Auch wenn Sie alle oben genannten Best Practices befolgt haben, kann es sein, dass Ihre Angular-Website nicht so gut gerankt ist, wie Sie es gerne hätten. Ein möglicher Grund dafür ist einer der grundlegenden Fehler von SPA-Frameworks im Zusammenhang mit SEO – sie sind auf Javascript angewiesen, um die Seite zu rendern. Dieses Problem kann sich auf zwei Arten manifestieren:
- Während Googlebot Javascript ausführen kann, tut dies nicht jeder Crawler. Für diejenigen, die dies nicht tun, sehen alle Ihre Seiten im Wesentlichen leer aus.
- Damit eine Seite nützliche Inhalte zeigt, muss der Crawler warten, bis die Javascript-Bündel heruntergeladen sind, die Engine sie analysiert hat, der Code ausgeführt wurde und alle externen XHRs zurückgegeben wurden – erst dann gibt es Inhalte im DOM. Im Vergleich zu traditionelleren Server-Rendering-Sprachen, bei denen die Informationen im DOM verfügbar sind, sobald das Dokument den Browser erreicht, wird eine SPA hier wahrscheinlich etwas benachteiligt.
Glücklicherweise hat Angular eine Lösung für dieses Problem, die es ermöglicht, eine Anwendung in einer Server-Rendering-Form zu bedienen: Angular Universal (https://github.com/angular/universal). Eine typische Implementierung mit dieser Lösung sieht so aus:
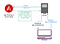
- Ein Client stellt eine Anfrage für eine bestimmte URL an Ihren Anwendungsserver.
- Der Server leitet die Anfrage an einen Rendering-Dienst weiter, der Ihre Angular-Anwendung ist, die in einem Node.js-Container läuft. Dieser Dienst kann (muss aber nicht) auf demselben Rechner wie der Anwendungsserver laufen.
- Die Serverversion der Anwendung rendert vollständiges HTML und CSS für den angeforderten Pfad und die Abfrage, einschließlich <script>-Tags, um die Client-Anwendung von Angular herunterzuladen.
- Der Browser empfängt die Seite und kann den Inhalt sofort anzeigen. Die Client-Anwendung wird asynchron geladen und sobald sie fertig ist, wird die aktuelle Seite neu gerendert und ersetzt das statische HTML, das der Server gerendert hat. Nun verhält sich die Website bei jeder weiteren Interaktion wie eine SPA. Dieser Prozess sollte für einen Benutzer, der die Website besucht, nahtlos sein.
Diese Magie ist jedoch nicht kostenlos. In diesem Leitfaden habe ich ein paar Mal erwähnt, wie man Dinge auf eine „Angular-freundliche“ Weise erledigen kann. Was ich wirklich meinte, war „Angular-server-rendering-freundlich“. Alle Best Practices, die Sie über Angular gelesen haben, wie z. B. das DOM nicht direkt zu berühren oder die Verwendung von setTimeout einzuschränken, werden sich rächen, wenn Sie sie nicht befolgt haben – in Form von langsamen Ladevorgängen oder sogar völlig fehlerhaften Seiten. Eine ausführliche Liste der Universal ‚gotchas‘ findet sich unter: https://github.com/angular/universal/blob/master/docs/gotchas.md
Hallo Server
Es gibt verschiedene Möglichkeiten, ein Projekt mit Universal zum Laufen zu bringen:
- Für Angular 5 Projekte kann man den folgenden Befehl in einem bestehenden Projekt ausführen:
ng generate universal server - Für Angular 6 Projekte gibt es noch keinen offiziellen CLI-Befehl, um ein funktionierendes Universal Projekt mit einem Client und Server zu erstellen. Sie können den folgenden Befehl eines Drittanbieters in einem bestehenden Projekt ausführen:
ng add @ng-toolkit/universal - Sie können dieses Repository auch klonen, um es als Startpunkt für Ihr Projekt zu verwenden oder in ein bestehendes Projekt einzubinden: https://github.com/angular/universal-starter
Dependency Injection is your (server’s) friend
In einem typischen Angular Universal-Setup gibt es drei verschiedene Anwendungsmodule – ein reines Browsermodul, ein reines Servermodul und ein gemeinsames Modul. Wir können dies zu unserem Vorteil nutzen, indem wir abstrakte Dienste erstellen, die unsere Komponenten injizieren, und in jedem Modul client- und serverspezifische Implementierungen bereitstellen. Betrachten wir dieses Beispiel eines Dienstes, der den Fokus auf ein Element setzen kann: Wir definieren einen abstrakten Dienst, Client- und Server-Implementierungen, stellen sie in ihren jeweiligen Modulen bereit und importieren den abstrakten Dienst in Komponenten.
Fixing server-hostile dependencies
Jede Komponente eines Drittanbieters, die nicht den Best Practices von Angular folgt (d.h. Dokument oder Fenster verwendet), wird das Server-Rendering jeder Seite zum Absturz bringen, die diese Komponente verwendet. Die beste Option ist, eine Universal-kompatible Alternative zur Bibliothek zu finden. Manchmal ist dies nicht möglich, oder Zeitbeschränkungen verhindern das Ersetzen der Abhängigkeit. In diesen Fällen gibt es zwei Hauptoptionen, um zu verhindern, dass die Bibliothek stört.
Sie können die störenden Komponenten auf dem Server *ngIf out. Ein einfacher Weg, dies zu tun, ist das Erstellen einer Direktive, die entscheiden kann, ob ein Element abhängig von der aktuellen Plattform gerendert wird:
Einige Bibliotheken sind problematischer; der bloße Akt des Importierens des Codes kann durchaus versuchen, Browser-only-Abhängigkeiten zu verwenden, die das Server-Rendering zum Absturz bringen. Ein Beispiel ist jede Bibliothek, die jquery als npm-Abhängigkeit importiert, anstatt zu erwarten, dass der Verbraucher jquery im globalen Bereich zur Verfügung hat. Um sicherzustellen, dass diese Bibliotheken den Server nicht zum Absturz bringen, müssen wir sowohl *ngIf aus der anstößigen Komponente herausnehmen, als auch die abhängige Bibliothek aus Webpack entfernen. Angenommen, die Bibliothek, die jquery importiert, heißt ‚jquery-funpicker‘, dann können wir eine Webpack-Regel wie die folgende schreiben, um sie aus dem Server-Build zu entfernen:
Dazu muss auch eine Datei mit dem Inhalt {} unter webpack/empty.json in der Projektstruktur abgelegt werden. Das Ergebnis wird sein, dass die Bibliothek eine leere Implementierung für ihre ‚jquery-funpicker‘-Importanweisung erhält, aber das macht nichts, weil wir diese Komponente überall in der Serveranwendung mit unserer neuen Richtlinie entfernt haben.
Verbessern Sie die Leistung des Browsers – wiederholen Sie Ihre XHRs nicht
Teil des Designs von Universal ist, dass die Client-Version der Anwendung die gesamte Logik, die auf dem Server ausgeführt wurde, um die Client-Ansicht zu erstellen, erneut ausführt – einschließlich der gleichen XHR-Aufrufe an Ihr Backend, die das Server-Rendering bereits gemacht hat! Dadurch wird Ihr Backend zusätzlich belastet, und Crawler erhalten den Eindruck, dass die Seite immer noch Inhalte lädt, obwohl sie nach der Rückkehr dieser XHRs wahrscheinlich dieselben Informationen anzeigt. Sofern nicht die Sorge besteht, dass die Daten veralten, sollten Sie verhindern, dass die Client-Anwendung XHRs dupliziert, die der Server bereits ausgeführt hat. Das TransferHttpCacheModule von Angular ist ein praktisches Modul, das dabei helfen kann: https://github.com/angular/universal/blob/master/docs/transfer-http.md
Unter der Haube verwendet das TransferHttpCacheModule die Klasse TransferState, die für jede allgemeine Statusübertragung vom Server zum Client verwendet werden kann:
Vorrendern, um die Zeit bis zum ersten Byte auf Null zu bringen
Eine Sache, die man bei der Verwendung von Universal (oder sogar einem Rendering-Dienst eines Drittanbieters wie https://prerender.io/) beachten muss, ist, dass eine vom Server gerenderte Seite eine längere Zeit hat, bevor das erste Byte den Browser erreicht, als eine vom Client gerenderte Seite. Dies macht Sinn, wenn man bedenkt, dass ein Server, der eine vom Client gerenderte Seite ausliefert, im Grunde nur eine statische index.html-Seite ausliefern muss. Universal wird das Rendering erst dann abschließen, wenn die Anwendung als „stabil“ angesehen wird. Stabilität im Kontext von Angular ist kompliziert, aber die beiden größten Faktoren, die zur Verzögerung der Stabilität beitragen, sind wahrscheinlich:
- Ausstehende XHRs
- Ausstehende setTimeout-Aufrufe
Wenn Sie keine Möglichkeit haben, die oben genannten Punkte weiter zu optimieren, besteht eine Möglichkeit, die Zeit bis zum ersten Byte zu verkürzen, darin, einfach einige oder alle Seiten Ihrer Anwendung vorzurechnen und sie aus einem Cache zu liefern. Das Angular Universal Starter Repo, das weiter oben in diesem Leitfaden verlinkt ist, enthält eine Implementierung für Pre-Rendering. Sobald Sie Ihre vorgerenderten Seiten haben, können Sie je nach Ihrer Architektur eine Caching-Lösung wie Varnish, Redis, ein CDN oder eine Kombination von Technologien verwenden. Indem Sie die Rendering-Zeit aus dem Server-zu-Client-Antwortpfad entfernen, können Sie Crawlern und den menschlichen Benutzern Ihrer Anwendung extrem schnelle anfängliche Seitenladungen bieten.
Schlussfolgerung
Viele der Techniken in diesem Artikel sind nicht nur gut für Suchmaschinen-Crawler, sie schaffen auch ein vertrauteres Website-Erlebnis für Ihre Benutzer. Etwas so Einfaches wie aussagekräftige Tab-Titel für verschiedene Seiten macht einen großen Unterschied bei relativ geringen Implementierungskosten. Wenn Sie das serverseitige Rendering einsetzen, werden Sie nicht mit unerwarteten Produktionslücken konfrontiert, wie z. B. mit Leuten, die versuchen, Ihre Website in sozialen Medien zu teilen und ein leeres Vorschaubild erhalten.
Wenn sich das Web weiterentwickelt, hoffe ich, dass wir den Tag erleben werden, an dem Crawler und Screen-Capture-Server mit Websites auf eine Art und Weise interagieren, die mehr mit der Interaktion der Benutzer auf ihren Geräten übereinstimmt – was Webanwendungen von den alten Websites unterscheidet, die sie nachahmen müssen. Bis dahin müssen wir als Entwickler jedoch weiterhin die alte Welt unterstützen.
