En este capítulo, discutiremos los protocolos de coherencia de la caché para hacer frente a los problemas de inconsistencia de la multicaché.
El problema de la coherencia de la caché
En un sistema multiprocesador, la inconsistencia de datos puede ocurrir entre niveles adyacentes o dentro del mismo nivel de la jerarquía de memoria. Por ejemplo, la caché y la memoria principal pueden tener copias inconsistentes del mismo objeto.
Como múltiples procesadores operan en paralelo, e independientemente múltiples cachés pueden poseer diferentes copias del mismo bloque de memoria, esto crea el problema de coherencia de caché. Los esquemas de coherencia de caché ayudan a evitar este problema manteniendo un estado uniforme para cada bloque de datos en caché.
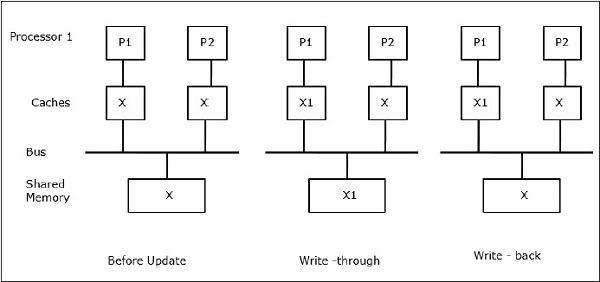
Sea X un elemento de datos compartidos que ha sido referenciado por dos procesadores, P1 y P2. Al principio, tres copias de X son consistentes. Si el procesador P1 escribe un nuevo dato X1 en la caché, utilizando la política de escritura, la misma copia se escribirá inmediatamente en la memoria compartida. En este caso, se produce una incoherencia entre la memoria caché y la memoria principal. Cuando se utiliza una política de escritura hacia atrás, la memoria principal se actualizará cuando los datos modificados en la caché sean reemplazados o invalidados.
En general, hay tres fuentes de problemas de inconsistencia –
- Compartición de datos escribibles
- Migración de procesos
- Actividad de E/S
Protocolos de bus Snoopy
Los protocolos Snoopy consiguen la consistencia de los datos entre la memoria caché y la memoria compartida mediante un sistema de memoria basado en el bus. Las políticas de escritura-invalidación y escritura-actualización se utilizan para mantener la consistencia de la caché.
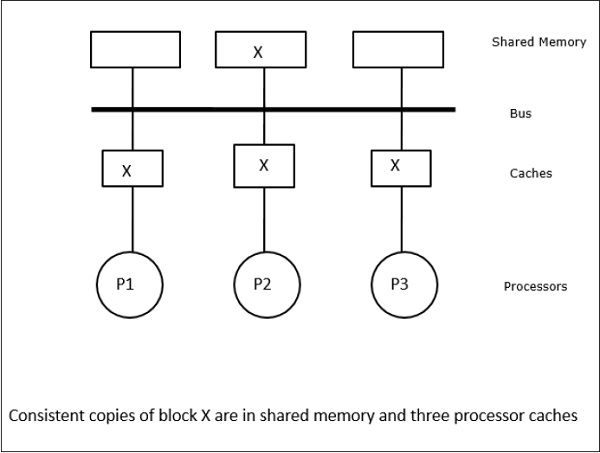
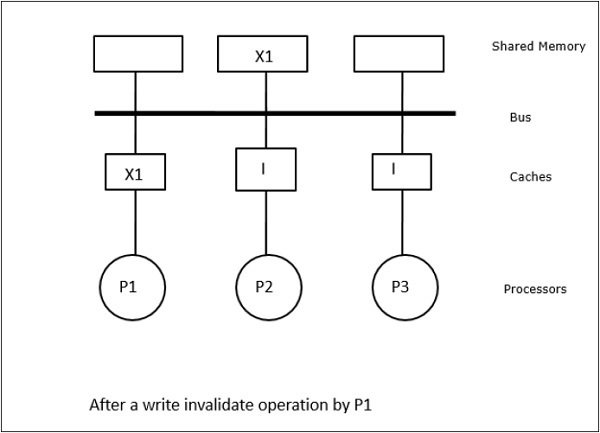
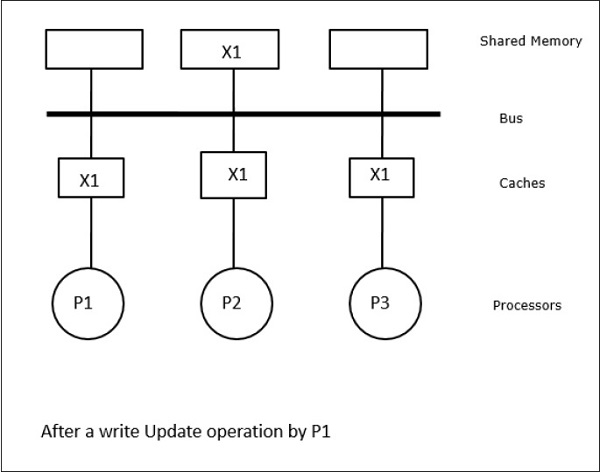
En este caso, tenemos tres procesadores P1, P2 y P3 que tienen una copia consistente del elemento de datos ‘X’ en su memoria caché local y en la memoria compartida (Figura-a). El procesador P1 escribe X1 en su memoria caché utilizando el protocolo de escritura-invalidación. Así, todas las demás copias se invalidan a través del bus. Se denota con «I» (Figura-b). Los bloques invalidados también se conocen como sucios, es decir, no deben utilizarse. El protocolo de actualización de escritura actualiza todas las copias de la caché a través del bus. Al utilizar la caché de escritura, la copia de memoria también se actualiza (Figura-c).
Eventos y acciones de la caché
Los siguientes eventos y acciones ocurren en la ejecución de los comandos de acceso a la memoria y de invalidación –
-
Lectura perdida – Cuando un procesador quiere leer un bloque y éste no está en la caché, se produce una lectura perdida. Esto inicia una operación de lectura del bus. Si no existe una copia sucia, entonces la memoria principal que tiene una copia consistente, suministra una copia a la memoria caché solicitante. Si existe una copia sucia en una memoria caché remota, esa memoria caché restringirá la memoria principal y enviará una copia a la memoria caché solicitante. En ambos casos, la copia de caché entrará en el estado válido después de un fallo de lectura.
-
Write-hit – Si la copia está en estado sucio o reservado, la escritura se realiza localmente y el nuevo estado es sucio. Si el nuevo estado es válido, el comando write-invalidate se emite a todas las cachés, invalidando sus copias. Cuando se escribe a través de la memoria compartida, el estado resultante es reservado después de esta primera escritura.
-
Write-miss – Si un procesador falla al escribir en la memoria caché local, la copia debe venir de la memoria principal o de una memoria caché remota con un bloque sucio. Esto se hace enviando un comando read-invalidate, que invalidará todas las copias de la caché. Entonces la copia local se actualiza con el estado sucio.
-
Lectura-hit – La lectura-hit se realiza siempre en la memoria caché local sin provocar una transición de estado ni utilizar el bus snoopy para la invalidación.
-
Sustitución de bloques – Cuando una copia está sucia, debe escribirse de nuevo en la memoria principal mediante el método de sustitución de bloques. Sin embargo, cuando la copia está en estado válido o reservado o inválido, no se realizará ningún reemplazo.
Protocolos basados en directorios
Al utilizar una red multietapa para construir un gran multiprocesador con cientos de procesadores, los protocolos de caché snoopy necesitan ser modificados para adaptarse a las capacidades de la red. Siendo la difusión muy costosa de realizar en una red multietapa, los comandos de consistencia se envían sólo a aquellas cachés que mantienen una copia del bloque. Esta es la razón para el desarrollo de protocolos basados en directorios para multiprocesadores conectados a la red.
En un sistema de protocolos basados en directorios, los datos a compartir se colocan en un directorio común que mantiene la coherencia entre las cachés. Aquí, el directorio actúa como un filtro donde los procesadores piden permiso para cargar una entrada desde la memoria primaria a su memoria caché. Si se cambia una entrada, el directorio la actualiza o invalida las otras cachés con esa entrada.
Mecanismos de sincronización por hardware
La sincronización es una forma especial de comunicación en la que, en lugar de control de datos, se intercambia información entre los procesos que se comunican y que residen en el mismo o en diferentes procesadores.
Los sistemas multiprocesadores utilizan mecanismos de hardware para implementar operaciones de sincronización de bajo nivel. La mayoría de los multiprocesadores tienen mecanismos de hardware para imponer operaciones atómicas, como operaciones de lectura, escritura o lectura-modificación-escritura en memoria, para implementar algunas primitivas de sincronización. Además de las operaciones atómicas de memoria, también se utilizan algunas interrupciones entre procesadores con fines de sincronización.
Coherencia de caché en máquinas de memoria compartida
Mantener la coherencia de la caché es un problema en un sistema multiprocesador cuando los procesadores contienen memoria caché local. La inconsistencia de datos entre diferentes cachés ocurre fácilmente en este sistema.
Las principales áreas de preocupación son –
- Compartición de datos escribibles
- Migración de procesos
- Actividad de E/S
Compartición de datos escribibles
Cuando dos procesadores (P1 y P2) tienen el mismo elemento de datos (X) en sus cachés locales y un proceso (P1) escribe en el elemento de datos (X), como las cachés son de escritura a través de la caché local de P1, la memoria principal también se actualiza. Ahora, cuando P2 intenta leer el elemento de datos (X), no encuentra X porque el elemento de datos en la caché de P2 ha quedado obsoleto.
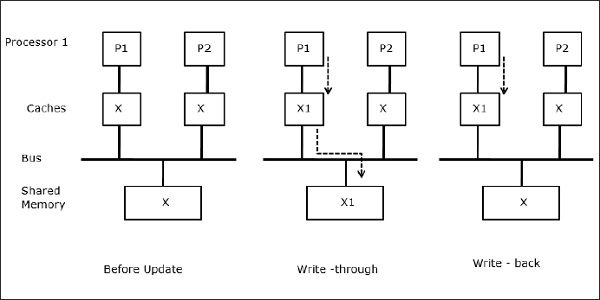
Migración de procesos
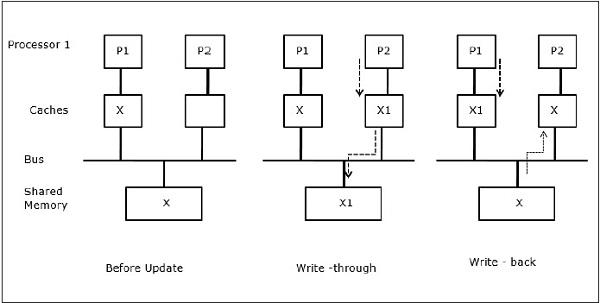
En la primera etapa, la caché de P1 tiene el elemento de datos X, mientras que P2 no tiene nada. Un proceso en P2 primero escribe en X y luego migra a P1. Ahora, el proceso comienza a leer el elemento de datos X, pero como el procesador P1 tiene datos obsoletos el proceso no puede leerlo. Entonces, un proceso en P1 escribe en el elemento de datos X y luego migra a P2. Después de la migración, un proceso en P2 comienza a leer el elemento de datos X pero encuentra una versión obsoleta de X en la memoria principal.
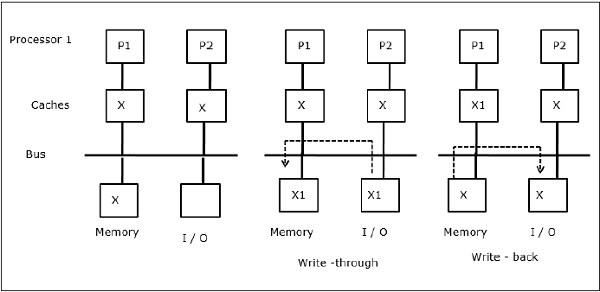
Actividad de E/S
Como se ilustra en la figura, se añade un dispositivo de E/S al bus en una arquitectura multiprocesador de dos procesadores. Al principio, ambas cachés contienen el elemento de datos X. Cuando el dispositivo de E/S recibe un nuevo elemento X, lo almacena directamente en la memoria principal. Ahora, cuando P1 o P2 (supongamos que P1) intenta leer el elemento X, obtiene una copia obsoleta. Entonces, P1 escribe en el elemento X. Ahora, si el dispositivo de E/S intenta transmitir X obtiene una copia desactualizada.
Acceso a memoria uniforme (UMA)
La arquitectura de acceso a memoria uniforme (UMA) significa que la memoria compartida es la misma para todos los procesadores del sistema. Las clases más populares de máquinas UMA, que se utilizan habitualmente para servidores (de archivos), son los llamados multiprocesadores simétricos (SMP). En un SMP, todos los recursos del sistema, como la memoria, los discos, otros dispositivos de E/S, etc., son accesibles para los procesadores de manera uniforme.
Acceso no uniforme a la memoria (NUMA)
En la arquitectura NUMA, hay múltiples clusters SMP que tienen una red interna indirecta/compartida, que están conectados en una red escalable de paso de mensajes. Así pues, la arquitectura NUMA es una arquitectura de memoria distribuida físicamente compartida.
En una máquina NUMA, el controlador de caché de un procesador determina si una referencia de memoria es local en la memoria del SMP o es remota. Para reducir el número de accesos remotos a la memoria, las arquitecturas NUMA suelen aplicar procesadores de caché que pueden almacenar los datos remotos. Pero cuando hay cachés, es necesario mantener la coherencia de la caché. Por ello, estos sistemas también se conocen como CC-NUMA (Cache Coherent NUMA).
Arquitectura de Memoria Sólo Caché (COMA)
Las máquinas COMA son similares a las máquinas NUMA, con la única diferencia de que las memorias principales de las máquinas COMA actúan como cachés de mapeo directo o conjunto asociativo. Los bloques de datos se asignan a una ubicación en la memoria caché DRAM de acuerdo con sus direcciones. Los datos que se obtienen de forma remota se almacenan realmente en la memoria principal local. Además, los bloques de datos no tienen una ubicación fija, sino que pueden moverse libremente por todo el sistema.
Las arquitecturas COMA suelen tener una red jerárquica de paso de mensajes. Un interruptor en tal árbol contiene un directorio con elementos de datos como su sub-árbol. Como los datos no tienen una ubicación de origen, deben ser buscados explícitamente. Esto significa que un acceso remoto requiere un recorrido a lo largo de los conmutadores del árbol para buscar los datos requeridos en sus directorios. Así, si un conmutador de la red recibe varias solicitudes de su subárbol para los mismos datos, las combina en una única solicitud que se envía al padre del conmutador. Cuando los datos solicitados regresan, el conmutador envía múltiples copias de los mismos por su subárbol.
COMA frente a CC-NUMA
Las siguientes son las diferencias entre COMA y CC-NUMA.
-
COMA tiende a ser más flexible que CC-NUMA porque COMA soporta de forma transparente la migración y replicación de datos sin necesidad del SO.
-
Las máquinas COMA son caras y complejas de construir porque necesitan hardware de gestión de memoria no estándar y el protocolo de coherencia es más difícil de implementar.
-
Los accesos remotos en COMA suelen ser más lentos que los de CC-NUMA ya que hay que atravesar la red de árboles para encontrar los datos.