Cuando se escriben aplicaciones de una sola página, es fácil y natural quedar atrapado en tratar de crear la experiencia ideal para el tipo más común de usuarios: otros humanos como nosotros. Este enfoque agresivo en un tipo de visitante a nuestro sitio a menudo puede dejar a otro grupo importante fuera en el frío – los rastreadores y bots utilizados por los motores de búsqueda como Google. Esta guía mostrará cómo algunas buenas prácticas fáciles de implementar y un movimiento hacia el renderizado del lado del servidor pueden dar a su aplicación lo mejor de ambos mundos cuando se trata de la experiencia del usuario de la SPA y el SEO.
Requisitos
Se asume un conocimiento práctico de Angular 5+. Algunas partes de la guía tratan sobre Angular 6 pero su conocimiento no es estrictamente necesario.
Muchos de los errores inadvertidos de SEO que cometemos provienen de la mentalidad de que estamos construyendo aplicaciones web y no sitios web. ¿Cuál es la diferencia? Es una distinción subjetiva, pero yo diría que desde el punto de vista del enfoque del esfuerzo:
- Las aplicaciones web se centran en interacciones naturales e intuitivas para los usuarios
- Los sitios web se centran en hacer que la información esté disponible de forma general
¡Pero estos dos conceptos no tienen por qué ser mutuamente excluyentes! Simplemente volviendo a las raíces de las reglas de desarrollo de los sitios web, podemos mantener el aspecto elegante de los SPA y poner la información en todos los lugares correctos para hacer un sitio web ideal para los rastreadores.
No ocultes el contenido detrás de las interacciones
Un principio en el que hay que pensar al diseñar los componentes es que los rastreadores son un poco tontos. Harán clic en tus anclas, pero no van a pasar por encima de los elementos al azar o hacer clic en un div sólo porque su contenido dice «Leer más». Esto entra en conflicto con Angular, donde una práctica común para ocultar la información es «*ngif it out». ¡Y muchas veces esto tiene sentido! Utilizamos esta práctica para mejorar el rendimiento de la aplicación al no tener componentes potencialmente pesados simplemente sentados en una parte no visible de la página.
Sin embargo, esto significa que si ocultas contenido en tu página a través de interacciones inteligentes, lo más probable es que un rastreador nunca va a ver ese contenido. Puede mitigar esto simplemente usando CSS en lugar de *ngif para ocultar este tipo de contenido. Por supuesto, los rastreadores inteligentes se darán cuenta de que el texto está oculto y probablemente lo considerarán menos importante que el texto visible. Pero este es un resultado mejor que el texto no sea accesible en el DOM en absoluto. Un ejemplo de este enfoque se parece a:
No crees «Anclas Virtuales»
El componente de abajo muestra un anti-patrón que veo mucho en las aplicaciones de Angular que yo llamo «ancla virtual»:
Básicamente lo que está sucediendo es que un manejador de clic se adjunta a algo como un <botón> o una etiqueta <div> y ese manejador realizará alguna lógica, luego usará el router importado de Angular para navegar a otra página. Esto es problemático por dos razones:
- Los rastreadores probablemente no harán clic en este tipo de elementos, e incluso si lo hacen, no establecerán un enlace entre la página de origen y la de destino.
- Esto impide la muy conveniente función ‘Abrir en una nueva pestaña’ que los navegadores proporcionan de forma nativa a las etiquetas de anclaje reales.
En lugar de utilizar Anclas Virtuales, utiliza una etiqueta real <a> con la directiva routerlink. Si necesitas realizar una lógica extra antes de navegar, puedes seguir añadiendo un manejador de clic a la etiqueta de anclaje.
No te olvides de los encabezados
Uno de los principios del buen SEO es establecer la importancia relativa de los diferentes textos de una página. Una herramienta importante para esto en el kit del desarrollador web son los encabezados. Es común olvidarse por completo de los encabezados cuando se diseña la jerarquía de componentes de una aplicación Angular; que se incluyan o no no supone ninguna diferencia visual en el producto final. Pero es algo que debes tener en cuenta para asegurarte de que los rastreadores se centran en las partes correctas de tu información. Así que considere el uso de etiquetas de encabezado donde tenga sentido. Sin embargo, asegúrese de que los componentes que incluyan etiquetas de encabezamiento no puedan organizarse de forma que un <h1> aparezca dentro de un <h2>.
Haga que las «páginas de resultados de búsqueda» sean enlazables
Volviendo al principio de cómo los rastreadores son tontos – considere una página de búsqueda para una empresa de widgets. Un rastreador no va a ver una entrada de texto en un formulario y escribir algo como «Toronto widgets». Conceptualmente, para que los resultados de la búsqueda estén disponibles para los rastreadores hay que hacer lo siguiente:
- Hay que configurar una página de búsqueda que acepte parámetros de búsqueda a través de la ruta y/o la consulta.
- Los enlaces a búsquedas específicas que usted cree que el rastreador podría encontrar interesantes deben ser añadidos al mapa del sitio o como enlaces de anclaje en otras páginas del sitio.
La estrategia en torno al punto #2 está fuera del alcance de este artículo (Algunos recursos útiles son https://yoast.com/internal-linking-for-seo-why-and-how/ y https://moz.com/learn/seo/internal-link). Lo importante es que los componentes de búsqueda y las páginas deben ser diseñadas con el punto #1 en mente para que tengas la flexibilidad de crear un enlace a cualquier tipo de búsqueda posible, permitiendo que se inyecte donde quieras. Esto significa importar el ActivatedRoute y reaccionar a sus cambios en la ruta y los parámetros de consulta para impulsar los resultados de búsqueda en su página, en lugar de confiar únicamente en sus componentes de consulta y filtrado en la página.
Haga que la paginación sea enlazable
Mientras que en el tema de las páginas de búsqueda, es importante asegurarse de que la paginación se maneja correctamente para que los rastreadores puedan acceder a cada página de sus resultados de búsqueda si así lo desean. Hay un par de buenas prácticas que puede seguir para asegurar esto.
Para reiterar los puntos anteriores: no utilice «Anclas Virtuales» para sus enlaces «siguiente», «anterior» y «número de página». Si un rastreador no puede verlos como anclas, puede que nunca mire nada más allá de su primera página. Utilice etiquetas <a> reales con RouterLink para estos enlaces. Además, incluya la paginación como una parte opcional de sus URLs de búsqueda enlazables – esto a menudo viene en forma de un parámetro de consulta page=.
Puede proporcionar pistas adicionales a los rastreadores sobre la paginación de su sitio mediante la adición de etiquetas relativas «prev»/»next» <link>. Puede encontrar una explicación de por qué pueden ser útiles en: https://webmasters.googleblog.com/2011/09/pagination-with-relnext-and-relprev.html. Aquí hay un ejemplo de un servicio que puede gestionar automáticamente estas etiquetas <link> de una manera amigable con Angular:
Incluir metadatos dinámicos
Una de las primeras cosas que hacemos en una nueva aplicación Angular es hacer ajustes en el archivo index.html – configurar el favicon, añadir etiquetas meta responsivas y, muy probablemente, configurar el contenido de las etiquetas <title> y <meta name=»description»> con algunos valores predeterminados sensatos para tu aplicación. Pero si te importa cómo aparecen tus páginas en los resultados de búsqueda, no puedes detenerte ahí. En cada ruta de su aplicación debe establecer dinámicamente las etiquetas title y description para que coincidan con el contenido de la página. Esto no sólo ayudará a los rastreadores, sino que también ayudará a los usuarios, ya que podrán ver los títulos informativos de las pestañas del navegador, los marcadores y la información de la vista previa cuando compartan un enlace en las redes sociales. El siguiente fragmento muestra cómo puedes actualizar esto de una manera amigable con Angular usando las clases Meta y Title:
Prueba para que los rastreadores rompan tu código
Algunas bibliotecas o SDKs de terceros se cierran o no pueden cargarse desde su proveedor de alojamiento cuando se detectan agentes de usuario que pertenecen a rastreadores de motores de búsqueda. Si alguna parte de su funcionalidad depende de estas dependencias, debe proporcionar un recurso para las dependencias que no permiten a los rastreadores. Como mínimo, su aplicación debería degradarse con gracia en estos casos, en lugar de bloquear el proceso de renderización del cliente. Una gran herramienta para probar la interacción de su código con los rastreadores es la página de prueba de Google Mobile Friendly: https://search.google.com/test/mobile-friendly. Busque una salida como esta que signifique que el rastreador tiene bloqueado el acceso a un SDK:

Reducir el tamaño del bundle con Angular 6
El tamaño del bundle en las aplicaciones de Angular es un problema bien conocido, pero hay muchas optimizaciones que un desarrollador puede hacer para mitigarlo, incluyendo el uso de compilaciones AOT y ser conservador con la inclusión de bibliotecas de terceros. Sin embargo, para obtener los paquetes de Angular más pequeños posibles hoy en día es necesario actualizar a Angular 6. La razón de esto es la actualización paralela requerida a RXJS 6, que ofrece mejoras significativas en su capacidad de sacudir el árbol. Para obtener realmente esta mejora, hay algunos requisitos duros para su aplicación:
- Eliminar la biblioteca rxjs-compat (que se añade por defecto en el proceso de actualización de Angular 6) – esta biblioteca hace que su código sea compatible con RXJS 5, pero anula las mejoras de agitación de árboles.
- Asegúrese de que todas las dependencias hacen referencia a Angular 6 y no utilizan la biblioteca rxjs-compat.
- Importe los operadores de RXJS de uno en uno en lugar de al por mayor para asegurar que la agitación del árbol pueda hacer su trabajo. Ver https://github.com/ReactiveX/rxjs/blob/master/docs_app/content/guide/v6/migration.md para una guía completa sobre la migración.
Renderización en el servidor
Incluso después de seguir todas las mejores prácticas anteriores puede encontrar que su sitio web Angular no está clasificado tan alto como le gustaría. Una posible razón para esto es uno de los defectos fundamentales con los frameworks SPA en el contexto del SEO – dependen de Javascript para renderizar la página. Este problema puede manifestarse de dos maneras:
- Aunque Googlebot puede ejecutar Javascript, no todos los rastreadores lo hacen. Para los que no lo hacen, todas sus páginas les parecerán esencialmente vacías.
- Para que una página muestre contenido útil, el rastreador tendrá que esperar a que se descarguen los paquetes de Javascript, a que el motor los analice, a que se ejecute el código y a que regrese cualquier XHR externo – entonces habrá contenido en el DOM. En comparación con los lenguajes de renderizado de servidor más tradicionales, en los que la información está disponible en el DOM tan pronto como el documento llega al navegador, es probable que una SPA se vea algo penalizada aquí.
Por suerte, Angular tiene una solución a este problema que permite servir una aplicación de forma renderizada en el servidor: Angular Universal (https://github.com/angular/universal). Una implementación típica que utiliza esta solución tiene el siguiente aspecto:
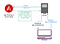
- Un cliente realiza una petición de una url concreta a su servidor de aplicaciones.
- El servidor proxy la petición a un servicio de renderizado que es su aplicación Angular ejecutada en un contenedor Node.js. Este servicio podría estar (pero no necesariamente) en la misma máquina que el servidor de aplicaciones.
- La versión del servidor de la aplicación renderiza el HTML y CSS completo para la ruta y la consulta solicitada, incluyendo las etiquetas <script> para descargar la aplicación Angular del cliente.
- El navegador recibe la página y puede mostrar el contenido inmediatamente. La aplicación cliente se carga de forma asíncrona y una vez que está lista, vuelve a renderizar la página actual y reemplaza el HTML estático que el servidor renderizó. Ahora el sitio web se comporta como un SPA para cualquier interacción en adelante. Este proceso debería ser perfecto para un usuario que navegue por el sitio.
Sin embargo, esta magia no es gratuita. Un par de veces en esta guía he mencionado cómo hacer las cosas de una manera ‘Angular-friendly’. Lo que realmente quería decir era ‘Angular server-rendering-friendly’. Todas las mejores prácticas que has leído sobre Angular, como no tocar el DOM directamente o limitar el uso de setTimeout, se volverán en tu contra si no las has seguido – en forma de carga lenta o incluso páginas totalmente rotas. Una extensa lista de los ‘gotchas’ de Universal se puede encontrar en: https://github.com/angular/universal/blob/master/docs/gotchas.md
Hello Server
Hay un par de opciones diferentes para conseguir que un proyecto funcione con Universal:
- Para los proyectos de Angular 5 puedes ejecutar el siguiente comando en un proyecto existente:
ng generate universal server - Para los proyectos de Angular 6 todavía no hay un comando CLI oficial para crear un proyecto Universal que funcione con un cliente y un servidor. Puedes ejecutar el siguiente comando de terceros en un proyecto existente:
ng add @ng-toolkit/universal - También puedes clonar este repositorio para usarlo como punto de partida de tu proyecto o para fusionarlo con uno existente: https://github.com/angular/universal-starter
La inyección de dependencias es tu amiga (del servidor)
En una configuración típica de Angular Universal tendrás tres módulos de aplicación diferentes: un módulo sólo para el navegador, un módulo sólo para el servidor y un módulo compartido. Podemos usar esto a nuestro favor creando servicios abstractos que nuestros componentes inyectan, y proporcionar implementaciones específicas para el cliente y el servidor en cada módulo. Consideremos este ejemplo de un servicio que puede establecer el foco en un elemento: definimos un servicio abstracto, implementaciones del cliente y del servidor, las proporcionamos en sus respectivos módulos, e importamos el servicio abstracto en los componentes.
Corrección de dependencias hostiles al servidor
Cualquier componente de terceros que no siga las mejores prácticas de Angular (es decir, que utilice documento o ventana) va a colapsar el renderizado del servidor de cualquier página que utilice ese componente. La mejor opción es encontrar una alternativa a la librería compatible con Universal. A veces esto no es posible, o las limitaciones de tiempo impiden sustituir la dependencia. En estos casos hay dos opciones principales para evitar que la biblioteca interfiera.
Puede *ngIf out off offending components on the server. Una forma fácil de hacer esto es crear una directiva que pueda decidir si un elemento será renderizado dependiendo de la plataforma actual:
Algunas librerías son más problemáticas; el mismo acto de importar el código puede intentar usar dependencias exclusivas del navegador que colapsarán el renderizado del servidor. Un ejemplo es cualquier biblioteca que importe jquery como una dependencia de npm, en lugar de esperar que el consumidor tenga jquery disponible en el ámbito global. Para asegurarnos de que estas librerías no rompen el servidor, debemos tanto *ngIf el componente infractor, como eliminar la librería dependiente de webpack. Asumiendo que la librería que importa jquery se llama ‘jquery-funpicker’, podemos escribir una regla de webpack como la siguiente para eliminarla de la construcción del servidor:
Esto también requiere colocar un archivo con el contenido {} en webpack/empty.json en la estructura de tu proyecto. El resultado será que la biblioteca obtendrá una implementación vacía para su declaración de importación ‘jquery-funpicker’, pero no importa porque hemos eliminado ese componente en todas partes de la aplicación del servidor con nuestra nueva directiva.
Mejorar el rendimiento del navegador – no repetir sus XHRs
Parte del diseño de Universal es que la versión cliente de la aplicación volverá a ejecutar toda la lógica que se ejecutó en el servidor para crear la vista del cliente – ¡incluyendo hacer las mismas llamadas XHR a su back-end que el renderizado del servidor ya hizo! Esto crea una carga extra en su back-end y una percepción para los rastreadores de que la página todavía está cargando contenido, aunque probablemente mostrará la misma información después de que esos XHRs regresen. A menos que exista una preocupación por el estancamiento de los datos, debería evitar que la aplicación cliente duplique los XHRs que el servidor ya ha realizado. El TransferHttpCacheModule de Angular es un módulo práctico que puede ayudar con esto: https://github.com/angular/universal/blob/master/docs/transfer-http.md
Debajo del capó, el TransferHttpCacheModule utiliza la clase TransferState que puede ser utilizada para cualquier transferencia de estado de propósito general del servidor al cliente:
Pre renderizar para mover el tiempo hasta el primer byte hacia cero
Una cosa a tener en cuenta cuando se utiliza Universal (o incluso un servicio de renderizado de terceros como https://prerender.io/) es que una página renderizada por el servidor tendrá un tiempo más largo antes de que el primer byte llegue al navegador que una página renderizada por el cliente. Esto debería tener sentido si se tiene en cuenta que para que un servidor entregue una página renderizada por el cliente, esencialmente sólo necesita entregar una página estática index.html. Universal no completará un renderizado hasta que la aplicación se considere «estable». La estabilidad en el contexto de Angular es complicada, pero los dos mayores contribuyentes al retraso de la estabilidad serán probablemente:
- XHRs pendientes
- Llamadas setTimeout pendientes
Si no tienes forma de optimizar más lo anterior, una opción para reducir el tiempo hasta el primer byte es simplemente pre-renderizar algunas o todas las páginas de tu aplicación y servirlas desde una caché. El repositorio de inicio de Angular Universal enlazado anteriormente en esta guía viene con una implementación para el pre-renderizado. Una vez que tengas tus páginas pre-renderizadas, dependiendo de tu arquitectura, una solución de caché podría ser algo como Varnish, Redis, un CDN, o una combinación de tecnologías. Al eliminar el tiempo de renderización de la ruta de respuesta del servidor al cliente, puede proporcionar cargas de páginas iniciales extremadamente rápidas a los rastreadores y a los usuarios humanos de su aplicación.
Conclusión
Muchas de las técnicas de este artículo no sólo son buenas para los rastreadores de los motores de búsqueda, sino que también crean una experiencia de sitio web más familiar para sus usuarios. Algo tan simple como tener títulos de pestañas informativas para diferentes páginas hace un mundo de diferencia para un costo de implementación relativamente bajo. Al adoptar el renderizado del lado del servidor, no te encontrarás con brechas de producción inesperadas, como por ejemplo que la gente intente compartir tu sitio en las redes sociales y obtenga una miniatura en blanco.
A medida que la web evoluciona, espero que veamos un día en el que los rastreadores y los servidores de captura de pantalla interactúen con los sitios web de una manera más acorde con la forma en que los usuarios interactúan en sus dispositivos, diferenciando las aplicaciones web de los sitios web de antaño que se ven obligados a emular. Por ahora, sin embargo, como desarrolladores debemos seguir apoyando el viejo mundo.
