Wikipediassa annetun määritelmän mukaan Anscomben kvartetti koostuu neljästä tietokokonaisuudesta, joilla on lähes identtiset yksinkertaiset tilastolliset ominaisuudet, mutta jotka näyttäytyvät hyvin erilaisina, kun ne esitetään graafisesti. Kukin aineisto koostuu yhdestätoista (x,y) pisteestä. Tilastotieteilijä Francis Anscombe konstruoi ne vuonna 1973 havainnollistaakseen sekä datan graafisen esittämisen tärkeyttä ennen sen analysointia että poikkeamien vaikutusta tilastollisiin ominaisuuksiin.
Yksinkertainen ymmärrys:
Kerran Francis John ”Frank” Anscombe, joka oli maineikas tilastotieteilijä, löysi unessaan 4 11 datapisteen sarjaa ja pyysi viimeisenä toiveenaan neuvostoa piirtämään nämä pisteet. Nuo 4 11 datapisteen sarjaa ovat alla.
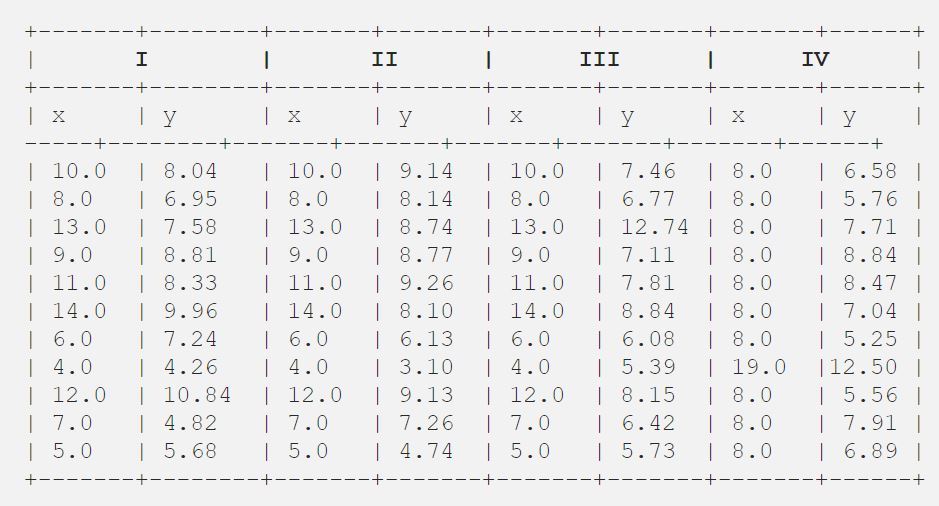
Sen jälkeen neuvosto analysoi ne käyttäen vain kuvailevia tilastoja ja löysi x:n ja y:n välisen keskiarvon, keskihajonnan ja korrelaation.
Lataa csv-tiedosto täältä.
Code: Python-ohjelma keskiarvon, keskihajonnan löytämiseksi, ja x:n ja y:n välinen korrelaatio
pandas as pd import statistics from scipy.stats import pearsonr df = pd.read_csv("anscombe.csv") list1 = df list2 = df print('%.1f' % statistics.mean(list1)) print('%.2f' % statistics.stdev(list1)) print('%.1f' % statistics.mean(list2)) print('%.2f' % statistics.stdev(list2)) corr, _ = pearsonr(list1, list2) print('%.3f' % corr) Output:
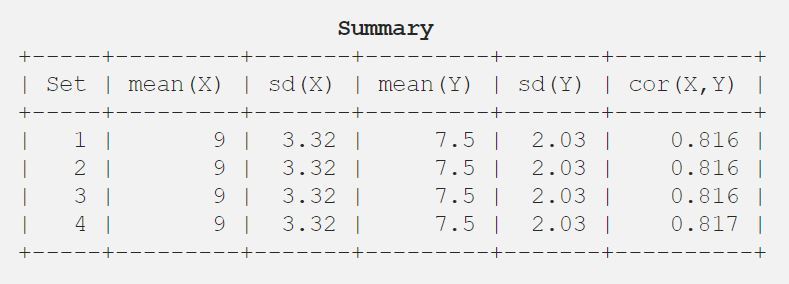
9.03.327.52.030.816
Näytän siis tuloksen taulukkomuodossa paremman ymmärryksen vuoksi.
Code: Python-ohjelma hajontadiagrammin piirtämiseen
from matplotlib import pyplot as plt import pandas as pd df = pd.read_csv("anscombe.csv") list1 = df list2 = df plt.scatter(list1, list2) plt.show() Regressiosuoran osalta viitataan tähän.
Tulos:
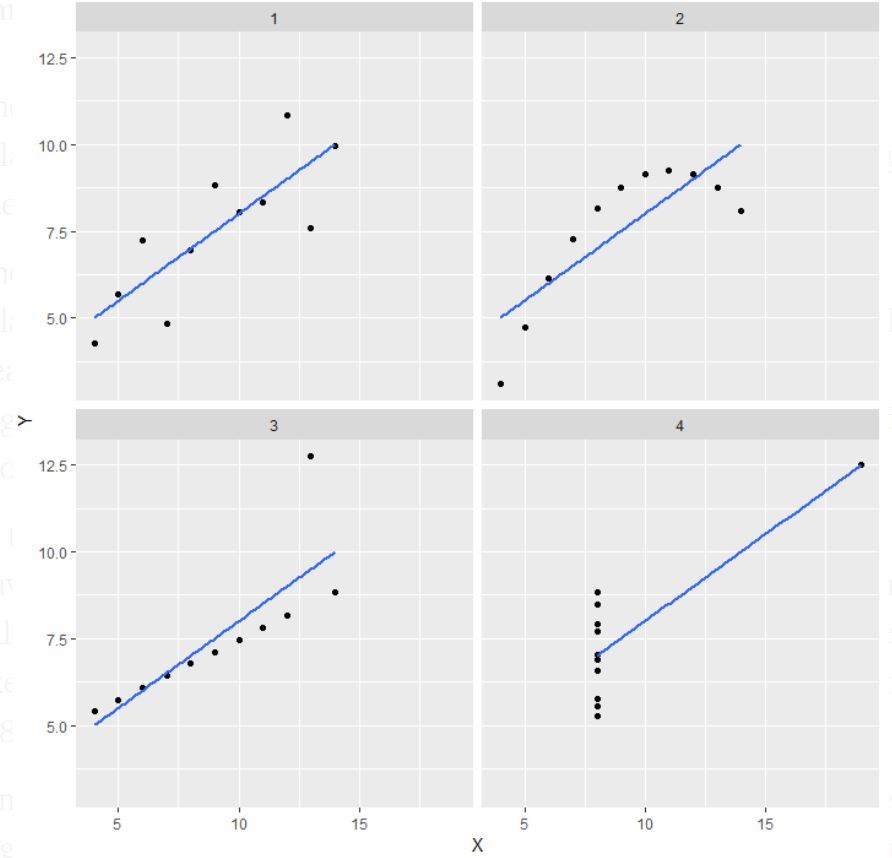
Huomautus: Määritelmässä mainitaan, että Anscomben kvartetti koostuu neljästä aineistosta, joilla on lähes identtiset yksinkertaiset tilastolliset ominaisuudet, mutta jotka näyttäytyvät kuitenkin hyvin erilaisina, kun ne esitetään graafisesti.
Tämän tuloksen selitys:
- Ensimmäisessä (ylhäällä vasemmalla) jos katsot hajontakuviota, näet, että x:n ja y:n välillä näyttää olevan lineaarinen suhde.
- Kakkosessa (ylhäällä oikealla) jos katsot tätä kuviota, voit päätellä, että x:n ja y:n välillä on epälineaarinen suhde.
- Kolmannessa(alhaalla vasemmalla) voit sanoa, kun on täydellinen lineaarinen suhde kaikille datapisteille paitsi yhdelle, joka näyttää olevan outlier, joka on merkitty olevan kaukana tästä suorasta.
- Viimeiseksi, neljäs(alhaalla oikealla) näyttää esimerkin, kun yksi erittäin vipuvaikutteinen piste riittää tuottamaan korkean korrelaatiokertoimen.
Sovellus:
Kvartettia käytetään edelleen usein havainnollistamaan sitä, kuinka tärkeää on tarkastella datajoukkoa graafisesti, ennen kuin aletaan analysoida tietynlaisen suhteen mukaan, sekä tilastollisten perusominaisuuksien riittämättömyyttä realististen datajoukkojen kuvailuun.