Lorsque l’on écrit des applications à page unique, il est facile et naturel de se laisser prendre à essayer de créer l’expérience idéale pour le type d’utilisateurs le plus commun – d’autres humains comme nous. Cette focalisation agressive sur un type de visiteur de notre site peut souvent laisser de côté un autre groupe important – les crawlers et les bots utilisés par les moteurs de recherche tels que Google. Ce guide montrera comment certaines bonnes pratiques faciles à mettre en œuvre et un mouvement vers le rendu côté serveur peuvent donner à votre application le meilleur des deux mondes en matière d’expérience utilisateur SPA et de SEO.
Prérequis
Une connaissance pratique d’Angular 5+ est supposée. Certaines parties du guide traitent d’Angular 6, mais sa connaissance n’est pas strictement requise.
Une grande partie des erreurs de référencement involontaires que nous faisons provient de l’état d’esprit selon lequel nous construisons des applications web et non des sites web. Quelle est la différence ? C’est une distinction subjective, mais je dirais que du point de vue de la concentration des efforts :
- Les applications web se concentrent sur les interactions naturelles et intuitives pour les utilisateurs
- Les sites web se concentrent sur la mise à disposition générale des informations
Mais ces deux concepts n’ont pas besoin d’être mutuellement exclusifs ! En revenant simplement aux racines des règles de développement des sites Web, nous pouvons maintenir l’aspect et la convivialité lisses des SPA et mettre l’information à tous les bons endroits pour faire un site Web idéal pour les crawlers.
Ne pas cacher le contenu derrière les interactions
Un principe auquel il faut penser lors de la conception des composants est que les crawlers sont en quelque sorte stupides. Ils cliqueront sur vos ancres, mais ils ne vont pas balayer aléatoirement les éléments ou cliquer sur une div juste parce que son contenu indique « Read More ». Cela va à l’encontre d’Angular, où une pratique courante pour cacher des informations est de les « *ngifer ». Et bien souvent, cela a du sens ! Nous utilisons cette pratique pour améliorer les performances de l’application en n’ayant pas de composants potentiellement lourds juste assis dans une partie non visible de la page.
Cependant, cela signifie que si vous cachez du contenu sur votre page grâce à des interactions intelligentes, il y a de fortes chances qu’un crawler ne voit jamais ce contenu. Vous pouvez atténuer cela en utilisant simplement CSS plutôt que *ngif pour cacher ce type de contenu. Bien sûr, les robots d’exploration intelligents remarqueront que le texte est caché et il sera probablement considéré comme moins important que le texte visible. Mais c’est un meilleur résultat que le texte qui n’est pas du tout accessible dans le DOM. Un exemple de cette approche ressemble à :
Ne pas créer d' » ancres virtuelles «
Le composant ci-dessous montre un anti-modèle que je vois beaucoup dans les applications Angular que j’appelle une » ancre virtuelle » :
Basiquement, ce qui se passe, c’est qu’un gestionnaire de clic est attaché à quelque chose comme un <bouton> ou une balise <div> et ce gestionnaire va exécuter une certaine logique, puis utiliser le routeur Angular importé pour naviguer vers une autre page. Ceci est problématique pour deux raisons :
- Les crawlers ne cliqueront probablement pas sur ce genre d’éléments, et même s’ils le font, ils n’établiront pas de lien entre la page source et la page de destination.
- Cela empêche la fonction très pratique ‘Ouvrir dans un nouvel onglet’ que les navigateurs fournissent nativement aux balises d’ancrage réelles.
Au lieu d’utiliser des ancres virtuelles, utilisez une balise <a> réelle avec la directive routerlink. Si vous devez exécuter une logique supplémentaire avant la navigation, vous pouvez toujours ajouter un gestionnaire de clic à la balise d’ancrage.
N’oubliez pas les titres
L’un des principes d’un bon référencement consiste à établir l’importance relative des différents textes sur une page. Un outil important pour cela dans le kit du développeur web est les titres. Il est courant d’oublier complètement les titres lors de la conception de la hiérarchie des composants d’une application Angular ; le fait qu’ils soient inclus ou non ne fait aucune différence visuelle dans le produit final. Mais c’est un élément dont vous devez tenir compte pour vous assurer que les robots d’exploration se concentrent sur les bonnes parties de vos informations. Envisagez donc d’utiliser des balises d’en-tête lorsque cela s’avère utile. Cependant, assurez-vous que les composants qui incluent des balises d’en-tête ne peuvent pas être disposés de telle sorte qu’un <h1> apparaisse à l’intérieur d’un <h2>.
Faites des « pages de résultats de recherche » des liens
Retournez au principe de la façon dont les crawlers sont muets – considérez une page de recherche pour une entreprise de widgets. Un crawler ne va pas voir une entrée de texte sur un formulaire et taper quelque chose comme « Toronto widgets ». Conceptuellement, pour rendre les résultats de recherche disponibles aux crawlers, il faut faire ce qui suit :
- Une page de recherche doit être mise en place qui accepte les paramètres de recherche à travers le chemin et/ou la requête.
- Les liens vers des recherches spécifiques que vous pensez que le crawler pourrait trouver intéressant doivent être ajoutés au sitemap ou comme liens d’ancrage sur d’autres pages du site.
La stratégie autour du point #2 sort du cadre de cet article (Certaines ressources utiles sont https://yoast.com/internal-linking-for-seo-why-and-how/ et https://moz.com/learn/seo/internal-link). Ce qui est important, c’est que les composants et les pages de recherche doivent être conçus avec le point #1 à l’esprit, afin que vous ayez la flexibilité de créer un lien vers n’importe quel type de recherche possible, ce qui permet de l’injecter où vous voulez. Cela signifie importer l’ActivatedRoute et réagir à ses changements de chemin et de paramètres de requête pour piloter les résultats de recherche sur votre page, au lieu de s’appuyer uniquement sur vos composants de requête et de filtrage sur la page.
Rendre la pagination liable
Pendant que nous parlons des pages de recherche, il est important de s’assurer que la pagination est gérée correctement afin que les crawlers puissent accéder à chaque page de vos résultats de recherche s’ils le souhaitent. Il y a quelques bonnes pratiques que vous pouvez suivre pour assurer cela.
Pour réitérer les points précédents : n’utilisez pas d' »ancres virtuelles » pour vos liens « suivant », « précédent » et « numéro de page ». Si un crawler ne peut pas les voir comme des ancres, il peut ne jamais regarder quoi que ce soit au-delà de votre première page. Utilisez des balises <a> réelles avec RouterLink pour ces liens. De plus, incluez la pagination comme une partie facultative de vos URL de recherche liable – cela se présente souvent sous la forme d’un paramètre de requête page=.
Vous pouvez fournir des indices supplémentaires aux robots d’exploration sur la pagination de votre site en ajoutant des balises relatives « prev »/ »next » <link>. Une explication sur la raison pour laquelle celles-ci peuvent être utiles peut être trouvée à : https://webmasters.googleblog.com/2011/09/pagination-with-relnext-and-relprev.html. Voici un exemple de service qui peut gérer automatiquement ces balises <link> d’une manière conviviale pour Angular :
Inclure des métadonnées dynamiques
L’une des premières choses que nous faisons à une nouvelle application Angular est de faire des ajustements au fichier index.html – définir le favicon, ajouter des balises méta responsive et très probablement définir le contenu des balises <title> et <meta name= »description »> à des valeurs par défaut raisonnables pour votre application. Mais si vous vous souciez de la façon dont vos pages s’affichent dans les résultats de recherche, vous ne pouvez pas vous arrêter là. Sur chaque route de votre application, vous devez définir dynamiquement les balises title et description pour qu’elles correspondent au contenu de la page. Cela aidera non seulement les robots d’exploration, mais aussi les utilisateurs, car ils pourront voir des titres d’onglet de navigateur informatifs, des signets et des informations de prévisualisation lorsqu’ils partageront un lien sur les médias sociaux. Le snippet ci-dessous montre comment vous pouvez les mettre à jour d’une manière conviviale pour Angular en utilisant les classes Meta et Title:
Tester pour que les crawlers cassent votre code
Certaines bibliothèques tierces ou SDK se ferment ou ne peuvent pas être chargées depuis leur hébergeur lorsque des agents utilisateurs appartenant à des crawlers de moteurs de recherche sont détectés. Si une partie de votre fonctionnalité repose sur ces dépendances, vous devriez fournir une solution de repli pour les dépendances qui interdisent les crawlers. À tout le moins, votre application devrait se dégrader gracieusement dans ces cas, plutôt que de planter le processus de rendu du client. Un excellent outil pour tester l’interaction de votre code avec les crawlers est la page de test Google Mobile Friendly : https://search.google.com/test/mobile-friendly. Recherchez des sorties comme celle-ci qui signifient que le crawler se voit bloquer l’accès à un SDK :

Réduire la taille des paquets avec Angular 6
La taille des paquets dans les applications Angular est un problème bien connu, mais il existe de nombreuses optimisations qu’un développeur peut faire pour l’atténuer, notamment en utilisant des builds AOT et en étant conservateur avec l’inclusion de bibliothèques tierces. Cependant, pour obtenir les plus petits bundles Angular possibles aujourd’hui, il faut passer à Angular 6. La raison en est la mise à niveau parallèle requise vers RXJS 6, qui offre des améliorations significatives à sa capacité de secouer l’arbre. Pour obtenir réellement cette amélioration, il y a quelques exigences dures pour votre application :
- Supprimez la bibliothèque rxjs-compat (qui est ajoutée par défaut dans le processus de mise à niveau d’Angular 6) – cette bibliothèque rend votre code rétrocompatible avec RXJS 5 mais défait les améliorations de tree-shaking.
- Assurez-vous que toutes les dépendances font référence à Angular 6 et n’utilisent pas la bibliothèque rxjs-compat.
- Importez les opérateurs RXJS un à la fois au lieu d’en gros pour vous assurer que le tree shaking peut faire son travail. Voir https://github.com/ReactiveX/rxjs/blob/master/docs_app/content/guide/v6/migration.md pour un guide complet sur la migration.
Rendu du serveur
Même après avoir suivi toutes les meilleures pratiques précédentes, vous pouvez constater que votre site Web Angular n’est pas classé aussi haut que vous le souhaiteriez. Une raison possible à cela est l’un des défauts fondamentaux des frameworks SPA dans le contexte du référencement – ils s’appuient sur Javascript pour rendre la page. Ce problème peut se manifester de deux manières :
- Bien que Googlebot puisse exécuter Javascript, tous les crawlers ne le font pas. Pour ceux qui ne le font pas, toutes vos pages auront l’air essentiellement vides pour eux.
- Pour qu’une page affiche un contenu utile, le crawler devra attendre que les bundles Javascript se téléchargent, que le moteur les analyse, que le code s’exécute et que tout XHR externe revienne – puis il y aura du contenu dans le DOM. Par rapport aux langages plus traditionnels à rendu serveur où les informations sont disponibles dans le DOM dès que le document frappe le navigateur, un SPA est susceptible d’être quelque peu pénalisé ici.
Heureusement, Angular a une solution à ce problème qui permet de servir une application sous une forme à rendu serveur : Angular Universal (https://github.com/angular/universal). Une mise en œuvre typique utilisant cette solution ressemble à :
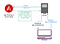
- Un client fait une demande pour une url particulière à votre serveur d’application.
- Le serveur transmet la demande à un service de rendu qui est votre application Angular exécutée dans un conteneur Node.js. Ce service pourrait être (mais n’est pas nécessairement) sur la même machine que le serveur d’application.
- La version serveur de l’application rend le HTML et le CSS complets pour le chemin et la requête demandés, y compris les balises <script> pour télécharger l’application Angular du client.
- Le navigateur reçoit la page et peut afficher le contenu immédiatement. L’application cliente se charge de manière asynchrone et, une fois prête, rend à nouveau la page actuelle et remplace le HTML statique rendu par le serveur. Désormais, le site Web se comporte comme un SPA pour toute interaction future. Ce processus devrait être transparent pour un utilisateur naviguant sur le site.
Cette magie n’est pas gratuite, cependant. À quelques reprises dans ce guide, j’ai mentionné comment faire les choses d’une manière ‘Angular-friendly’. Ce que je voulais vraiment dire, c’était » Angular server-rendering-friendly « . Toutes les bonnes pratiques que vous avez lues à propos d’Angular, comme ne pas toucher directement au DOM ou limiter l’utilisation de setTimeout, vous reviendront en pleine figure si vous ne les avez pas suivies – sous la forme d’un chargement lent ou même de pages totalement cassées. Une liste exhaustive des « gotchas » universels se trouve à l’adresse suivante : https://github.com/angular/universal/blob/master/docs/gotchas.md
Hello Server
Il existe plusieurs options différentes pour faire fonctionner un projet avec Universal :
- Pour les projets Angular 5, vous pouvez exécuter la commande suivante dans un projet existant :
ng generate universal server - Pour les projets Angular 6, il n’existe pas encore de commande CLI officielle pour créer un projet Universal fonctionnel avec un client et un serveur. Vous pouvez exécuter la commande tierce suivante dans un projet existant :
ng add @ng-toolkit/universal - Vous pouvez également cloner ce dépôt pour l’utiliser comme point de départ de votre projet ou pour le fusionner dans un projet existant : https://github.com/angular/universal-starter
L’injection de dépendances est votre ami (du serveur)
Dans une configuration typique d’Angular Universal, vous aurez trois modules d’application différents – un module réservé au navigateur, un module réservé au serveur et un module partagé. Nous pouvons utiliser cela à notre avantage en créant des services abstraits que nos composants injectent, et fournir des implémentations spécifiques au client et au serveur dans chaque module. Considérons cet exemple d’un service qui peut définir le focus sur un élément : nous définissons un service abstrait, des implémentations client et serveur, nous les fournissons dans leurs modules respectifs et nous importons le service abstrait dans les composants.
Correction des dépendances hostiles au serveur
Tout composant tiers qui ne suit pas les meilleures pratiques d’Angular (c’est-à-dire qui utilise document ou window) va planter le rendu du serveur de toute page qui utilise ce composant. La meilleure option est de trouver une alternative à la bibliothèque compatible avec Universal. Parfois, cela n’est pas possible, ou des contraintes de temps empêchent de remplacer la dépendance. Dans ces cas, il existe deux options principales pour empêcher la bibliothèque d’interférer.
Vous pouvez *ngIf out les composants offensifs sur le serveur. Un moyen facile de le faire est de créer une directive qui peut décider si un élément sera rendu en fonction de la plateforme actuelle :
Certaines bibliothèques sont plus problématiques ; l’acte même d’importer le code peut très bien tenter d’utiliser des dépendances réservées au navigateur qui feront planter le rendu du serveur. Un exemple est toute bibliothèque qui importe jquery comme une dépendance npm, plutôt que de s’attendre à ce que le consommateur ait jquery disponible dans la portée globale. Pour s’assurer que ces bibliothèques n’endommagent pas le serveur, nous devons à la fois éliminer le composant incriminé par *ngIf et supprimer la bibliothèque dépendante de webpack. En supposant que la bibliothèque qui importe jquery s’appelle ‘jquery-funpicker’, nous pouvons écrire une règle webpack comme celle ci-dessous pour la dépouiller de la construction du serveur :
Cela nécessite également de placer un fichier avec le contenu {} à webpack/empty.json dans la structure de votre projet. Le résultat sera que la bibliothèque obtiendra une implémentation vide pour son instruction d’importation ‘jquery-funpicker’, mais cela n’a pas d’importance car nous avons supprimé ce composant partout dans l’application serveur avec notre nouvelle directive.
Améliorer les performances du navigateur – ne répétez pas vos XHR
Une partie de la conception de Universal est que la version client de l’application va ré-exécuter toute la logique qui a été exécutée sur le serveur pour créer la vue client – y compris faire les mêmes appels XHR à votre back-end que le rendu du serveur a déjà fait ! Cela crée une charge supplémentaire sur votre back-end et donne l’impression aux crawlers que la page est toujours en train de charger du contenu, même si elle affichera probablement les mêmes informations après le retour de ces XHR. À moins qu’il n’y ait un risque de perte de données, vous devriez empêcher l’application client de dupliquer les XHR que le serveur a déjà effectués. Le module TransferHttpCacheModule d’Angular est un module pratique qui peut aider à cela : https://github.com/angular/universal/blob/master/docs/transfer-http.md
Sous le capot, le TransferHttpCacheModule utilise la classe TransferState qui peut être utilisée pour tout transfert d’état à usage général du serveur au client :
Pré-rendu pour déplacer le temps au premier octet vers zéro
Une chose à considérer lors de l’utilisation d’Universal (ou même d’un service de rendu tiers comme https://prerender.io/) est qu’une page rendue par le serveur aura un temps plus long avant que le premier octet n’atteigne le navigateur qu’une page rendue par le client. Cela devrait être logique si l’on considère que pour qu’un serveur fournisse une page rendue par le client, il doit essentiellement fournir une page index.html statique. Universal n’effectue pas de rendu tant que l’application n’est pas considérée comme « stable ». La stabilité dans le contexte d’Angular est compliquée, mais les deux plus grands contributeurs au retard de la stabilité seront probablement :
- Des XHR en suspens
- Des appels setTimeout en suspens
Si vous n’avez aucun moyen d’optimiser davantage ce qui précède, une option pour réduire votre temps au premier octet est de simplement pré-rendre une partie ou la totalité des pages de votre application et de les servir à partir d’un cache. Le repo de démarrage d’Angular Universal, dont le lien figure plus haut dans ce guide, contient une implémentation du pré-rendu. Une fois que vous avez vos pages pré-rendues, en fonction de votre architecture, une solution de mise en cache peut être quelque chose comme Varnish, Redis, un CDN, ou une combinaison de technologies. En supprimant le temps de rendu du chemin de réponse serveur-client, vous pouvez fournir des chargements de page initiaux extrêmement rapides aux crawlers et aux utilisateurs humains de votre application.
Conclusion
Plusieurs des techniques de cet article ne sont pas seulement bonnes pour les crawlers des moteurs de recherche, elles créent également une expérience de site web plus familière pour vos utilisateurs. Quelque chose d’aussi simple que d’avoir des titres d’onglet informatifs pour différentes pages fait un monde de différence pour un coût de mise en œuvre relativement faible. En adoptant le rendu côté serveur, vous ne serez pas frappé par des lacunes de production inattendues, telles que des personnes essayant de partager votre site sur les médias sociaux et obtenant une vignette vide.
A mesure que le web évolue, j’espère que nous verrons un jour où les crawlers et les serveurs de capture d’écran interagissent avec les sites web d’une manière plus conforme à la façon dont les utilisateurs interagissent sur leurs appareils – différenciant les applications web des sites web d’autrefois qu’ils sont forcés d’émuler. Pour l’instant cependant, en tant que développeurs, nous devons continuer à soutenir l’ancien monde.

.