Selon la définition donnée par Wikipédia, le quatuor d’Anscombe comprend quatre ensembles de données qui ont des propriétés statistiques simples presque identiques, mais qui apparaissent très différents lorsqu’ils sont représentés graphiquement. Chaque ensemble de données est constitué de onze points (x,y). Ils ont été construits en 1973 par le statisticien Francis Anscombe pour démontrer à la fois l’importance de représenter graphiquement les données avant de les analyser et l’effet des valeurs aberrantes sur les propriétés statistiques.
Compréhension simple :
Une fois, Francis John « Frank » Anscombe qui était un statisticien de grande renommée a trouvé 4 ensembles de 11 points de données dans son rêve et a demandé au conseil comme son dernier souhait de tracer ces points. Ces 4 ensembles de 11 points de données sont donnés ci-dessous.
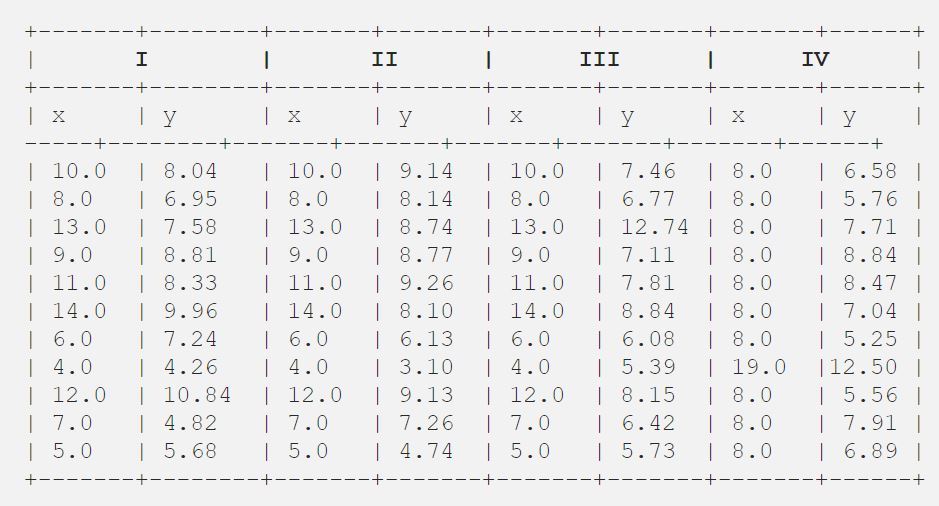
Après cela, le conseil les a analysés en utilisant uniquement des statistiques descriptives et a trouvé la moyenne, l’écart-type et la corrélation entre x et y.
Veuillez télécharger le fichier csv ici.
Code : Programme Python pour trouver la moyenne, l’écart type, et la corrélation entre x et y
import pandas as pd import statistics from scipy.stats import pearsonr df = pd.read_csv("anscombe.csv") list1 = df list2 = df print('%.1f' % statistics.mean(list1)) print('%.2f' % statistics.stdev(list1)) print('%.1f' % statistics.mean(list2)) print('%.2f' % statistics.stdev(list2)) corr, _ = pearsonr(list1, list2) print('%.3f' % corr) Sortie :
9.03.327.52.030.816
Je vais donc vous montrer le résultat sous forme de tableau pour une meilleure compréhension.
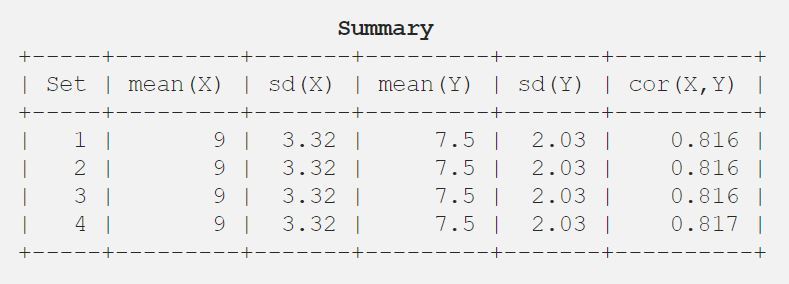
Code: Programme Python pour tracer un nuage de points
from matplotlib import pyplot as plt import pandas as pd df = pd.read_csv("anscombe.csv") list1 = df list2 = df plt.scatter(list1, list2) plt.show() Pour la ligne de régression se référer à ceci.
Sortie:
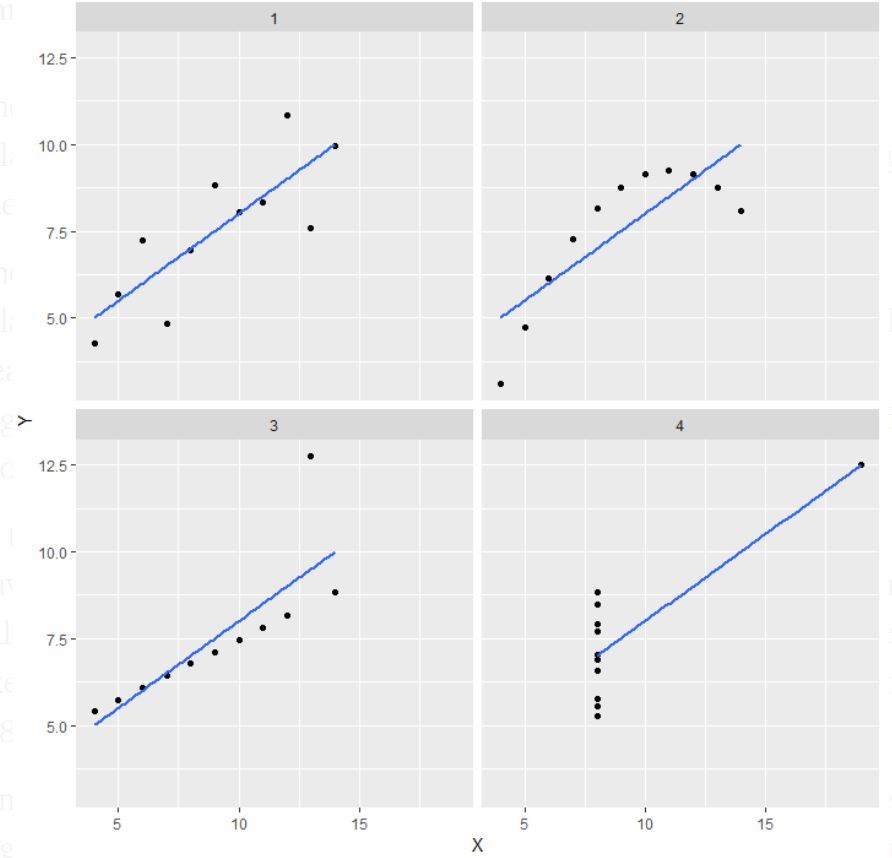
Note : Il est mentionné dans la définition que le quatuor d’Anscombe comprend quatre ensembles de données qui ont des propriétés statistiques simples presque identiques, mais qui apparaissent très différents lorsqu’ils sont représentés graphiquement.
Explication de cette sortie :
- Dans la première(en haut à gauche) si vous regardez le nuage de points, vous verrez qu’il semble y avoir une relation linéaire entre x et y.
- Dans la seconde(en haut à droite) si vous regardez cette figure, vous pouvez conclure qu’il y a une relation non linéaire entre x et y.
- Dans la troisième(en bas à gauche) vous pouvez dire quand il y a une relation linéaire parfaite pour tous les points de données sauf un qui semble être une aberration qui est indiqué être loin de cette ligne.
- Enfin, le quatrième(en bas à droite) montre un exemple où un point à fort effet de levier est suffisant pour produire un coefficient de corrélation élevé.
Application:
Le quatuor est encore souvent utilisé pour illustrer l’importance de regarder un ensemble de données graphiquement avant de commencer à analyser selon un type particulier de relation, et l’inadéquation des propriétés statistiques de base pour décrire des ensembles de données réalistes.