Ebben a fejezetben a cache koherencia protokollokat tárgyaljuk a multicache inkonzisztencia problémák kezelésére.
A gyorsítótár-koherencia probléma
Egy többprocesszoros rendszerben az adatinkonzisztencia előfordulhat a memóriahierarchia szomszédos szintjei között vagy ugyanazon a szinten belül. Például a gyorsítótár és a főmemória rendelkezhet ugyanazon objektum ellentmondásos másolataival.
Mivel több processzor párhuzamosan működik, és egymástól függetlenül több gyorsítótár is rendelkezhet ugyanazon memóriablokk különböző másolataival, ez gyorsítótár-koherencia problémát okoz. A gyorsítótár-koherencia sémák segítenek elkerülni ezt a problémát azáltal, hogy minden egyes gyorsítótárban tárolt adatblokkhoz egységes állapotot tartanak fenn.
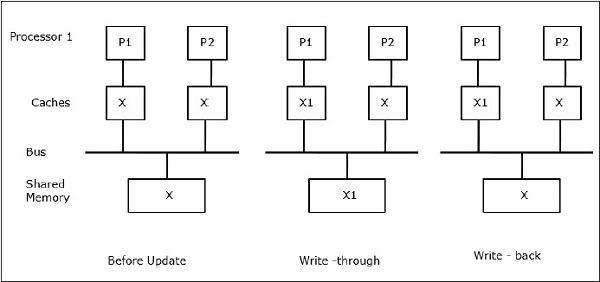
Legyen X a megosztott adatok egy eleme, amelyre két processzor, P1 és P2 hivatkozik. Kezdetben X három példánya konzisztens. Ha a P1 processzor egy új X1 adatot ír a gyorsítótárba, az átírási politika alkalmazásával ugyanaz a másolat azonnal beíródik a megosztott memóriába. Ebben az esetben következetlenség lép fel a gyorsítótár és a főmemória között. Visszaírási házirend használata esetén a főmemória akkor frissül, amikor a gyorsítótárban lévő módosított adatot kicserélik vagy érvénytelenítik.
Az inkonzisztenciaproblémának általában három forrása van –
- Az írható adatok megosztása
- Folyamatmigráció
- I/O tevékenység
Snoopy buszprotokollok
A snoopy protokollok az adatok konzisztenciáját a gyorsítótár és a megosztott memória között egy buszalapú memóriarendszer segítségével érik el. A cache konzisztencia fenntartására a write-invalidate és write-update irányelveket használják.
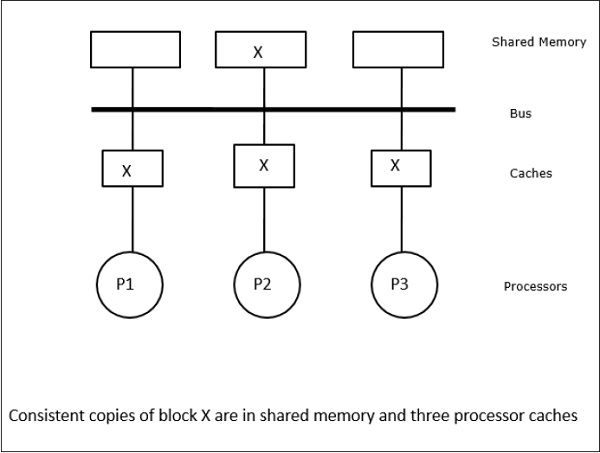
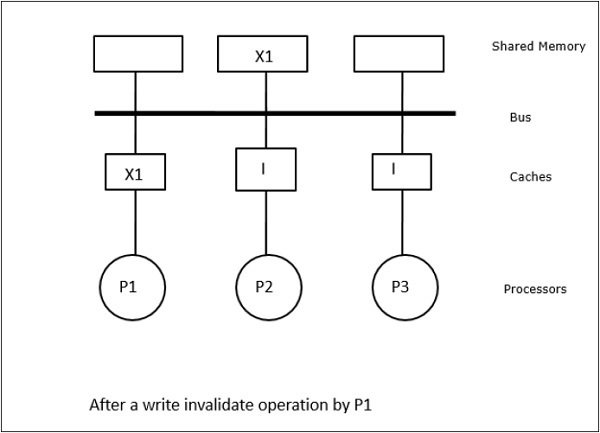
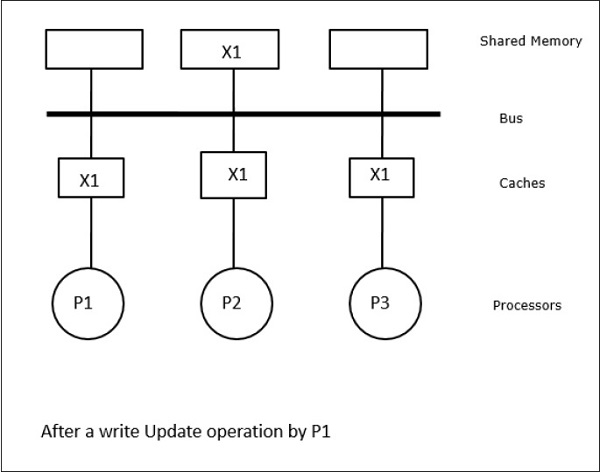
Ez esetben három processzorunk, P1, P2 és P3 rendelkezik az “X” adatelem konzisztens másolatával a helyi cache-memóriában és a megosztott memóriában (ábra-a). A P1 processzor írja az X1-et a cache-memóriájába write-invalidate protokollal. Így az összes többi másolat érvénytelenítésre kerül a buszon keresztül. Ezt az “I” jelöli (b ábra). Az érvénytelenített blokkokat piszkosnak is nevezik, azaz nem szabad használni őket. A write-update protokoll a buszon keresztül frissíti az összes gyorsítótár-másolatot. A visszaíró gyorsítótár használatával a memóriamásolat is frissül (c ábra).
Cache Events and Actions
A memória-hozzáférési és érvénytelenítési parancsok végrehajtásakor a következő események és műveletek következnek be –
-
Read-miss – Amikor a processzor olvasni akar egy blokkot, de az nincs a gyorsítótárban, akkor read-miss következik be. Ez egy buszos olvasási műveletet indít el. Ha nincs piszkos másolat, akkor a konzisztens másolattal rendelkező főmemória másolatot szolgáltat a kérő cache-memóriának. Ha egy távoli gyorsítótár-memóriában van piszkos másolat, akkor ez a gyorsítótár visszatartja a főmemóriát, és másolatot küld a kérő gyorsítótár-memóriának. Mindkét esetben a gyorsítótármásolat egy olvasási hiba után érvényes állapotba kerül.
-
Write-hit – Ha a másolat piszkos vagy foglalt állapotban van, az írás helyben történik, és az új állapot piszkos. Ha az új állapot érvényes, az write-invalidate parancs az összes gyorsítótárba elküldésre kerül, érvénytelenítve azok másolatait. Ha a megosztott memóriát átírják, az így kapott állapotot ezután az első írás után lefoglalják.
-
Write-miss – Ha a processzor nem tud írni a helyi gyorsítótár-memóriába, a másolatnak vagy a főmemóriából, vagy egy távoli, piszkos blokkú gyorsítótár-memóriából kell érkeznie. Ez egy read-invalidate parancs elküldésével történik, amely érvényteleníti az összes cache-másolatot. Ezután a helyi másolat a piszkos állapottal frissül.
-
Read-hit – A read-hit mindig a helyi cache-memóriában történik, anélkül, hogy állapotátmenetet okozna vagy a snoopy-buszt használná érvénytelenítésre.
-
Block replacement – Ha egy másolat piszkos, akkor azt a block replacement módszerrel vissza kell írni a főmemóriába. Ha azonban a másolat vagy érvényes, vagy foglalt, vagy érvénytelen állapotban van, akkor nem történik csere.
Könyvtár alapú protokollok
A többlépcsős hálózat használatakor egy nagy, több száz processzort tartalmazó multiprocesszor felépítéséhez a snoopy cache protokollokat a hálózati képességeknek megfelelően módosítani kell. Mivel egy többlépcsős hálózatban nagyon költséges a közvetítés, a konzisztenciaparancsokat csak azoknak a gyorsítótáraknak küldjük el, amelyek a blokk egy példányát őrzik. Ez az oka a könyvtáralapú protokollok kifejlesztésének a hálózatba kapcsolt többprocesszorokhoz.
A könyvtáralapú protokollrendszerben a megosztandó adatokat egy közös könyvtárban helyezik el, amely fenntartja a gyorsítótárak közötti koherenciát. A könyvtár itt szűrőként működik, ahol a processzorok engedélyt kérnek egy bejegyzés betöltésére az elsődleges memóriából a saját gyorsítótár-memóriájukba. Ha egy bejegyzés megváltozik, a könyvtár vagy frissíti azt, vagy érvényteleníti a többi gyorsítótárat az adott bejegyzéssel.
Hardveres szinkronizációs mechanizmusok
A szinkronizáció a kommunikáció egy speciális formája, ahol adatvezérlés helyett információcsere történik az azonos vagy különböző processzorokban található kommunikáló folyamatok között.
A többprocesszoros rendszerek hardveres mechanizmusokat használnak az alacsony szintű szinkronizációs műveletek megvalósítására. A legtöbb multiprocesszor rendelkezik olyan hardveres mechanizmusokkal, amelyek atomi műveleteket, például memóriaolvasási, -írási vagy olvasás-módosítás-írás műveleteket írnak elő egyes szinkronizációs primitívek megvalósítására. Az atomi memóriaoperációkon kívül néhány processzorok közötti megszakítást is használnak szinkronizációs célokra.
Cache koherencia megosztott memóriájú gépekben
A cache koherencia fenntartása problémát jelent a többprocesszoros rendszerben, ha a processzorok helyi cache-memóriát tartalmaznak. A különböző gyorsítótárak közötti adatinkonzisztencia könnyen előfordul ebben a rendszerben.
A fő problémás területek: –
- Az írható adatok megosztása
- Folyamatok migrációja
- I/O tevékenység
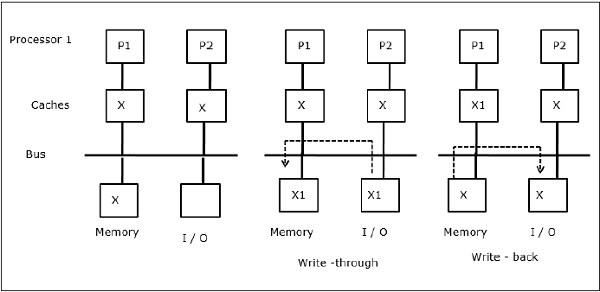
Az írható adatok megosztása
Ha két processzor (P1 és P2) azonos adatelemmel (X) rendelkezik a helyi gyorsítótárakban, és az egyik folyamat (P1) ír az adatelembe (X), mivel a gyorsítótárak a P1 helyi gyorsítótárán keresztül íródnak, a főmemória is frissül. Most, amikor P2 megpróbálja olvasni az adatelemet (X), nem találja X-et, mert a P2 gyorsítótárában lévő adatelem elavult.
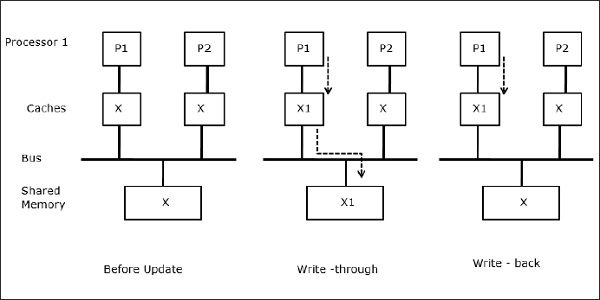
Folyamatok migrációja
Az első szakaszban P1 gyorsítótárában van X adatelem, míg P2-ben nincs semmi. Egy P2-n lévő folyamat először X-re ír, majd átmegy P1-re. Most a folyamat elkezdi olvasni az X adatelemet, de mivel a P1 processzoron elavult adatok vannak, a folyamat nem tudja olvasni. Tehát a P1-en lévő folyamat ír az X adatelemre, majd átmegy a P2-re. A migráció után a P2-n lévő folyamat elkezdi olvasni az X adatelemet, de a főmemóriában az X elavult változatát találja.
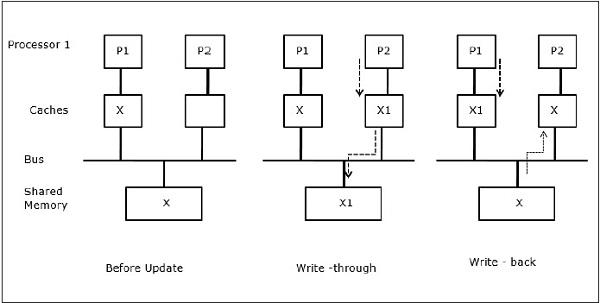
I/O tevékenység
Az ábrán látható módon egy kétprocesszoros többprocesszoros architektúrában egy I/O eszköz kerül a buszra. Kezdetben mindkét gyorsítótár tartalmazza az X adatelemet. Amikor az I/O-eszköz egy új X elemet kap, az új elemet közvetlenül a főmemóriában tárolja. Most, amikor P1 vagy P2 (feltételezzük, hogy P1) megpróbálja olvasni az X elemet, egy elavult másolatot kap. Tehát P1 ír az X elembe. Most, ha az I/O eszköz megpróbálja továbbítani X-et, akkor egy elavult másolatot kap.
Egységes memóriaelérés (UMA)
Az egységes memóriaelérés (UMA) architektúra azt jelenti, hogy a megosztott memória a rendszerben lévő összes processzor számára azonos. Az UMA gépek népszerű osztályai, amelyeket általában (fájl-) szerverekhez használnak, az úgynevezett szimmetrikus multiprocesszorok (SMP-k). Egy SMP-ben az összes rendszererőforrás, például a memória, a lemezek, az egyéb I/O-eszközök stb. a processzorok számára egységesen hozzáférhetőek.
Non-Uniform Memory Access (NUMA)
A NUMA architektúrában több SMP-klaszter van, amelyek belső közvetett/megosztott hálózattal rendelkeznek, és skálázható üzenetátviteli hálózatba vannak kapcsolva. A NUMA architektúra tehát logikailag megosztott, fizikailag elosztott memóriaarchitektúra.
A NUMA gépben a processzor gyorsítótár-vezérlője határozza meg, hogy egy memóriahivatkozás az SMP memóriájában helyi vagy távoli. A távoli memóriaelérések számának csökkentése érdekében a NUMA architektúrák általában olyan gyorsítótárazó processzorokat alkalmaznak, amelyek képesek a távoli adatok gyorsítótárazására. Ha azonban gyorsítótárakról van szó, a gyorsítótár-koherenciát fenn kell tartani. Ezért ezeket a rendszereket CC-NUMA (Cache Coherent NUMA) néven is ismerik.
Cache Only Memory Architecture (COMA)
A COMA gépek hasonlóak a NUMA gépekhez, azzal a különbséggel, hogy a COMA gépek fő memóriái közvetlen leképezésű vagy halmaz-asszociatív gyorsítótárként működnek. Az adatblokkok a címüknek megfelelő helyre kerülnek a DRAM gyorsítótárban. A távolról lehívott adatokat valójában a helyi főmemóriában tárolják. Ráadásul az adatblokkoknak nincs fix otthoni helyük, szabadon mozoghatnak a rendszerben.
ACOMA architektúrák többnyire hierarchikus üzenetátviteli hálózattal rendelkeznek. Egy ilyen fában egy kapcsoló egy adatelemeket tartalmazó könyvtárat tartalmaz alfaként. Mivel az adatoknak nincs otthoni helye, ezért azokat explicit módon kell megkeresni. Ez azt jelenti, hogy a távoli hozzáféréshez a fában lévő kapcsolókon végig kell haladni, hogy azok könyvtáraiban megkeressük a kívánt adatokat. Ha tehát egy kapcsoló a hálózatban több kérést kap az alfájából ugyanarra az adatra, akkor azokat egyetlen kéréssé egyesíti, amelyet a kapcsoló szülőjének küld el. Amikor a kért adat visszatér, a switch több másolatot küld lefelé a részfáján.
COMA versus CC-NUMA
A következőkben a COMA és a CC-NUMA közötti különbségeket ismertetjük.
-
A COMA általában rugalmasabb, mint a CC-NUMA, mivel a COMA átláthatóan támogatja az adatok migrációját és replikációját az operációs rendszer igénybevétele nélkül.
-
A COMA gépeket drága és bonyolult megépíteni, mert nem szabványos memóriakezelő hardverre van szükségük, és a koherencia protokollt nehezebb megvalósítani.
-
A COMA-ban a távoli hozzáférések gyakran lassabbak, mint a CC-NUMA-ban, mivel a fahálózatot kell bejárni az adatok megtalálásához.