Bij het schrijven van single page applicaties is het makkelijk en natuurlijk om verstrikt te raken in het proberen de ideale ervaring te creëren voor het meest voorkomende type gebruikers – andere mensen zoals wijzelf. Deze agressieve focus op één soort bezoeker van onze site kan vaak een andere belangrijke groep in de kou laten staan – de crawlers en bots die worden gebruikt door zoekmachines zoals Google. Deze gids laat zien hoe een aantal eenvoudig te implementeren best practices en een beweging naar server-side rendering uw applicatie het beste van twee werelden kan geven als het gaat om SPA gebruikerservaring en SEO.
Voorvereisten
Een actieve kennis van Angular 5+ wordt verondersteld. Sommige delen van de gids gaan over Angular 6, maar kennis daarvan is niet strikt vereist.
Veel van de onbedoelde SEO-fouten die we maken, komen voort uit de mentaliteit dat we webapplicaties bouwen en geen websites. Wat is het verschil? Het is een subjectief onderscheid, maar ik zou zeggen vanuit het oogpunt van de focus van de inspanning:
- Web applicaties richten zich op natuurlijke en intuïtieve interacties voor gebruikers
- Web sites richten zich op het algemeen beschikbaar stellen van informatie
Maar deze twee concepten hoeven elkaar niet uit te sluiten! Door gewoon terug te keren naar de wortels van de regels voor website-ontwikkeling, kunnen we de gelikte look en feel van SPA’s behouden en informatie op alle juiste plaatsen zetten om een ideale website voor crawlers te maken.
Verstop inhoud niet achter interacties
Een principe om over na te denken bij het ontwerpen van componenten is dat crawlers een soort van dom zijn. Ze zullen op je ankers klikken, maar ze zullen niet willekeurig over elementen vegen of op een div klikken alleen omdat de inhoud “Lees meer” zegt. Dit komt op gespannen voet te staan met Angular, waar een gangbare praktijk om informatie te verbergen is om “*ngif it out”. En vaak is dit zinvol! We gebruiken dit om de prestaties van applicaties te verbeteren door potentieel zware componenten niet in een niet zichtbaar deel van de pagina te laten zitten.
Dit betekent echter dat als je content op je pagina verbergt door slimme interacties, de kans groot is dat een crawler die content nooit te zien krijgt. Je kunt dit tegengaan door CSS te gebruiken in plaats van *ngif om dit soort inhoud te verbergen. Natuurlijk, slimme crawlers zullen merken dat de tekst verborgen is en het zal waarschijnlijk worden gewogen als minder belangrijk dan zichtbare tekst. Maar dit is een beter resultaat dan dat de tekst helemaal niet toegankelijk is in het DOM. Een voorbeeld van deze aanpak ziet er als volgt uit:
Maak geen “virtuele ankers”
Het onderstaande component toont een antipatroon dat ik veel zie in Angular-toepassingen en dat ik een “virtueel anker” noem:
Basically what’s happening is that a click handler is attached to something like a <button> or <div> tag and that handler will perform some logic, then use the imported Angular Router to navigate to another page. Dit is problematisch om twee redenen:
- Crawlers zullen waarschijnlijk niet op dit soort elementen klikken, en zelfs als ze dat doen, zullen ze geen link leggen tussen de bron- en bestemmingspagina.
- Dit voorkomt de zeer handige ‘Open in nieuw tabblad’-functie die browsers van nature bieden aan echte anker-tags.
In plaats van virtuele ankers te gebruiken, gebruik dan een echte <a>-tag met de routerlink-richtlijn. Als u extra logica moet uitvoeren voordat u navigeert, kunt u nog steeds een click handler aan de anchor tag toevoegen.
Vergeet de koppen niet
Een van de principes van goede SEO is het vaststellen van het relatieve belang van verschillende tekst op een pagina. Een belangrijk hulpmiddel hierbij voor webontwikkelaars zijn de koppen. Het is gebruikelijk om de koppen helemaal te vergeten bij het ontwerpen van de component hiërarchie van een Angular applicatie; of ze wel of niet worden opgenomen maakt geen visueel verschil in het eindproduct. Maar dit is wel iets waar je rekening mee moet houden om ervoor te zorgen dat crawlers zich richten op de juiste delen van je informatie. Overweeg dus om heading tags te gebruiken waar dat zinvol is. Zorg er echter voor dat onderdelen die heading-tags bevatten niet zo kunnen worden gerangschikt dat een <h1> binnen een <h2> verschijnt.
Maak “Zoekresultaat-pagina’s” linkbaar
Terugkomend op het principe van hoe crawlers dom zijn – denk aan een zoekpagina voor een widget-bedrijf. Een crawler ziet geen tekst op een formulier en typt iets in als “Toronto widgets”. Conceptueel, om zoekresultaten beschikbaar te maken voor crawlers moet het volgende gebeuren:
- Er moet een zoekpagina worden opgezet die zoekparameters accepteert via het pad en/of de query.
- Links naar specifieke zoekopdrachten waarvan u denkt dat de crawler ze interessant zou kunnen vinden, moeten worden toegevoegd aan de sitemap of als ankerlinks op andere pagina’s van de site.
De strategie rond punt #2 valt buiten het bestek van dit artikel (Enkele nuttige bronnen zijn https://yoast.com/internal-linking-for-seo-why-and-how/ en https://moz.com/learn/seo/internal-link). Wat belangrijk is, is dat zoekcomponenten en -pagina’s worden ontworpen met punt #1 in gedachten, zodat je de flexibiliteit hebt om een link te maken naar elk soort zoekactie die mogelijk is, zodat deze kan worden geïnjecteerd waar je maar wilt. Dit betekent dat je de ActivatedRoute importeert en reageert op de veranderingen in pad en query parameters om de zoekresultaten op je pagina aan te sturen, in plaats van alleen te vertrouwen op je on-page query en filtering componenten.
Maak paginering linkable
Wanneer we het toch over zoekpagina’s hebben, is het belangrijk om er voor te zorgen dat paginering correct wordt afgehandeld, zodat crawlers elke pagina van je zoekresultaten kunnen benaderen als ze dat willen. Er zijn een paar best practices die je kunt volgen om dit te verzekeren.
Om eerdere punten te herhalen: gebruik geen “Virtuele Ankers” voor je “volgende”, “vorige” en “paginanummer” links. Als een crawler deze niet als ankers kan zien, zal hij misschien nooit verder kijken dan de eerste pagina. Gebruik hiervoor echte <a> tags met RouterLink. Neem paginering ook op als optioneel onderdeel van uw doorklikbare zoek-URL’s – dit gebeurt vaak in de vorm van een page= queryparameter.
U kunt crawlers extra hints geven over de paginering van uw site door relatieve “prev”/”next” <link>-tags toe te voegen. Een uitleg over waarom deze nuttig kunnen zijn, is te vinden op: https://webmasters.googleblog.com/2011/09/pagination-with-relnext-and-relprev.html. Hier volgt een voorbeeld van een service die deze <link>-tags automatisch kan beheren op een Angular-vriendelijke manier:
Dynamische metadata opnemen
Eén van de eerste dingen die we doen bij een nieuwe Angular-applicatie is aanpassingen aanbrengen in het index.html bestand – het instellen van de favicon, het toevoegen van responsive meta tags en waarschijnlijk het instellen van de inhoud van de <title> en <meta name=”description”> tags op een aantal verstandige standaardwaarden voor uw applicatie. Maar als u er om geeft hoe uw pagina’s in de zoekresultaten verschijnen, kunt u het daar niet bij laten. Op elke route voor je applicatie moet je dynamisch de titel en beschrijving tags instellen zodat ze overeenkomen met de pagina inhoud. Dit helpt niet alleen crawlers, het helpt ook gebruikers, omdat zij informatieve browsertabbladtitels, bladwijzers en voorbeeldinformatie te zien krijgen wanneer ze een link delen op sociale media. Onderstaand knipsel laat zien hoe u deze op een Angular-vriendelijke manier kunt bijwerken met de klassen Meta en Title:
Test of crawlers uw code kraken
Sommige bibliotheken of SDK’s van derden worden afgesloten of kunnen niet worden geladen van hun hostingprovider wanneer user agents worden gedetecteerd die behoren tot crawlers van zoekmachines. Als een deel van uw functionaliteit afhankelijk is van deze afhankelijkheden, moet u een fallback bieden voor afhankelijkheden die crawlers niet toestaan. Op zijn minst zou je applicatie in deze gevallen gracieus moeten degraderen, in plaats van het renderproces van de client te laten crashen. Een goed hulpmiddel voor het testen van de interactie van je code met crawlers is de Google Mobile Friendly testpagina: https://search.google.com/test/mobile-friendly. Zoek naar uitvoer zoals deze, die aangeeft dat de toegang tot een SDK voor de crawler wordt geblokkeerd:

Bundelgrootte verkleinen met Angular 6
Bundelgrootte in Angular-applicaties is een bekend probleem, maar er zijn veel optimalisaties die een ontwikkelaar kan doorvoeren om dit te beperken, waaronder het gebruik van AOT builds en conservatief zijn met het opnemen van bibliotheken van derden. Echter, om vandaag de dag de kleinst mogelijke Angular bundels te krijgen, is het nodig om te upgraden naar Angular 6. De reden hiervoor is de vereiste parallelle upgrade naar RXJS 6, die aanzienlijke verbeteringen biedt in de mogelijkheid om met bomen te schudden. Om deze verbetering daadwerkelijk te krijgen, zijn er enkele harde eisen voor uw applicatie:
- Verwijder de rxjs-compat library (die standaard wordt toegevoegd in het Angular 6 upgrade proces) – deze library maakt uw code backwards compatible met RXJS 5 maar verslaat de tree-shaking verbeteringen.
- Zorg ervoor dat alle afhankelijkheden naar Angular 6 verwijzen en de rxjs-compat-bibliotheek niet gebruiken.
- Importeer RXJS-operatoren een voor een in plaats van in het groot om ervoor te zorgen dat tree shaking zijn werk kan doen. Zie https://github.com/ReactiveX/rxjs/blob/master/docs_app/content/guide/v6/migration.md voor een volledige gids over migreren.
Server Rendering
Zelfs na het volgen van alle voorgaande best practices kunt u merken dat uw Angular-website niet zo hoog wordt gerangschikt als u zou willen. Een mogelijke reden hiervoor is een van de fundamentele gebreken met SPA frameworks in de context van SEO – ze vertrouwen op Javascript om de pagina te renderen. Dit probleem kan zich op twee manieren manifesteren:
- Terwijl Googlebot Javascript kan uitvoeren, doet niet elke crawler dat. Voor degenen die dat niet doen, zullen al uw pagina’s er in wezen leeg uitzien.
- Om een pagina bruikbare inhoud te laten zien, moet de crawler wachten tot Javascript-bundels zijn gedownload, de engine ze heeft geparseerd, de code is uitgevoerd, en eventuele externe XHR’s zijn teruggekeerd – dan zal er inhoud in het DOM zijn. Vergeleken met meer traditionele server rendered talen waar informatie beschikbaar is in het DOM zodra het document de browser raakt, zal een SPA hier waarschijnlijk enigszins worden gestraft.
Gelukkig heeft Angular een oplossing voor dit probleem dat het mogelijk maakt een applicatie in een server rendered vorm te serveren: Angular Universal (https://github.com/angular/universal). Een typische implementatie die gebruik maakt van deze oplossing ziet er als volgt uit:
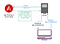
- Een client doet een verzoek voor een bepaalde url aan uw applicatieserver.
- De server proxieert het verzoek naar een rendering service die uw Angular applicatie is die draait in een Node.js container. Deze dienst zou kunnen zijn (maar is niet noodzakelijk) op dezelfde machine als de applicatie server.
- De server versie van de applicatie rendert volledige HTML en CSS voor het gevraagde pad en query, inclusief <script> tags om de client Angular applicatie te downloaden.
- De browser ontvangt de pagina en kan de inhoud onmiddellijk tonen. De client applicatie laadt asynchroon en zodra klaar, re-rendert de huidige pagina en vervangt de statische HTML die de server renderde. Nu gedraagt de website zich als een SPA voor elke interactie in de toekomst. Dit proces zou naadloos moeten zijn voor een gebruiker die de site bekijkt.
Deze magie is echter niet gratis. Een paar keer in deze gids heb ik het gehad over hoe je dingen op een ‘Angular-vriendelijke’ manier kunt doen. Wat ik echt bedoelde was ‘Angular server-rendering-vriendelijk’. Alle best practices die je leest over Angular zoals het niet direct aanraken van het DOM of het beperken van het gebruik van setTimeout zullen je terug bijten als je ze niet hebt opgevolgd – in de vorm van traag ladende of zelfs totaal kapotte pagina’s. Een uitgebreide lijst van de universele ‘gotchas’ is te vinden op: https://github.com/angular/universal/blob/master/docs/gotchas.md
Hello Server
Er zijn een paar verschillende opties om een project draaiende te krijgen met Universal:
- Voor Angular 5 projecten kunt u het volgende commando uitvoeren in een bestaand project:
ng generate universal server - Voor Angular 6 projecten is er nog geen officieel CLI commando voor het maken van een werkend Universal project met een client en server. U kunt het volgende commando van een derde partij uitvoeren in een bestaand project:
ng add @ng-toolkit/universal - U kunt deze repository ook klonen om als startpunt voor uw project te gebruiken of om in een bestaand project samen te voegen: https://github.com/angular/universal-starter
Dependency injection is your (server’s) friend
In een typische Angular Universal set-up heb je drie verschillende applicatie modules – een browser-only module, een server-only module en een gedeelde module. We kunnen dit in ons voordeel gebruiken door abstracte services te maken die onze componenten injecteren, en client- en server-specifieke implementaties in elke module aan te bieden. Beschouw dit voorbeeld van een service die focus op een element kan zetten: we definiëren een abstracte service, client, en server implementaties, bieden ze aan in hun respectievelijke modules, en importeren de abstracte service in componenten.
Servervijandige afhankelijkheden verhelpen
Elke component van derden die niet de Angular best practices volgt (d.w.z. document of venster gebruikt), zal de server-rendering van elke pagina die die component gebruikt, laten crashen. De beste optie is om een universeel-compatibel alternatief voor de library te vinden. Soms is dit niet mogelijk, of verhinderen tijdsbeperkingen het vervangen van de afhankelijkheid. In deze gevallen zijn er twee mogelijkheden om te voorkomen dat de bibliotheek interfereert.
U kunt *ngIf offending components op de server uitschakelen. Een eenvoudige manier om dit te doen is het maken van een richtlijn die kan beslissen of een element zal worden gerenderd afhankelijk van het huidige platform:
Sommige bibliotheken zijn problematischer; de handeling zelf van het importeren van de code kan heel goed proberen om browser-only afhankelijkheden te gebruiken die de server render zal laten crashen. Een voorbeeld hiervan is een bibliotheek die jquery importeert als een npm-afhankelijkheid, in plaats van te verwachten dat de gebruiker jquery beschikbaar heeft in het globale bereik. Om ervoor te zorgen dat deze bibliotheken de server niet laten crashen, moeten we zowel de overtredende component *ngIf eruit halen, als de afhankelijke bibliotheek uit webpack halen. Ervan uitgaande dat de bibliotheek die jquery importeert ‘jquery-funpicker’ heet, kunnen we een webpack-regel als de onderstaande schrijven om deze uit de server build te strippen:
Dit vereist ook het plaatsen van een bestand met de inhoud {} bij webpack/empty.json in uw projectstructuur. Het resultaat zal zijn dat de bibliotheek een lege implementatie krijgt voor zijn ‘jquery-funpicker’ import statement, maar het maakt niet uit omdat we die component overal in de server applicatie hebben verwijderd met onze nieuwe directive.
Verbeter de browser performance – herhaal je XHRs niet
Onderdeel van het ontwerp van Universal is dat de client versie van de applicatie alle logica die op de server is uitgevoerd om de client view te maken, opnieuw zal uitvoeren – inclusief het maken van dezelfde XHR calls naar je back end die de server rendering al heeft gemaakt! Dit zorgt voor een extra belasting van je backend en een perceptie bij crawlers dat de pagina nog steeds inhoud aan het laden is, ook al zal hij waarschijnlijk dezelfde informatie tonen nadat die XHR’s terugkomen. Tenzij er een probleem is met data-stilheid, moet je voorkomen dat de client applicatie XHRs dupliceert die de server al heeft gemaakt. De TransferHttpCacheModule van Angular is een handige module die hierbij kan helpen: https://github.com/angular/universal/blob/master/docs/transfer-http.md
Onder de motorkap maakt de TransferHttpCacheModule gebruik van de TransferState klasse die kan worden gebruikt voor elke state transfer voor algemene doeleinden van server naar client:
Pre render om time-to-first-byte naar nul te brengen
Een ding om te overwegen wanneer u Universal gebruikt (of zelfs een renderservice van derden zoals https://prerender.io/) is dat een server gerenderde pagina een langere tijd zal hebben voordat de eerste byte de browser bereikt dan een client gerenderde pagina. Dit zou logisch moeten zijn als je bedenkt dat een server om een client-rendered pagina af te leveren in principe alleen een statische index.html pagina hoeft af te leveren. Universal zal een render pas voltooien als de applicatie als ‘stabiel’ wordt beschouwd. Stabiliteit in de context van Angular is gecompliceerd, maar de twee grootste bijdragen aan de vertraging van stabiliteit zullen waarschijnlijk zijn:
- Outstanding XHRs
- Outstanding setTimeout calls
Als je geen manier hebt om het bovenstaande verder te optimaliseren, is een optie om je time-to-first-byte te verminderen door simpelweg enkele of alle pagina’s van je applicatie te pre-renderen en ze vanuit een cache te serveren. De Angular Universal starter repo die eerder in deze gids is gelinkt komt met een implementatie voor pre-rendering. Als je eenmaal je pre-rendered pagina’s hebt, afhankelijk van je architectuur, kan een caching oplossing iets zijn als Varnish, Redis, een CDN, of een combinatie van technologieën. Door het verwijderen van de rendering tijd uit de server-to-client respons pad, kunt u extreem snelle eerste pagina ladingen aan crawlers en de menselijke gebruikers van uw applicatie.
Conclusie
Vele van de technieken in dit artikel zijn niet alleen goed voor zoekmachine crawlers, ze creëren een meer vertrouwde website ervaring voor uw gebruikers ook. Zoiets eenvoudigs als informatieve tabbladtitels voor verschillende pagina’s maakt een wereld van verschil tegen relatief lage implementatiekosten. Door server-side rendering te omarmen, zult u niet worden getroffen door onverwachte productielacunes, zoals mensen die uw site proberen te delen op sociale media en een lege thumbnail te zien krijgen.
Naarmate het web zich ontwikkelt, hoop ik dat we een dag zullen meemaken waarop crawlers en screen capture-servers met websites communiceren op een manier die meer in lijn is met de manier waarop gebruikers op hun apparaten communiceren – waardoor webapplicaties zich onderscheiden van de oude websites die ze gedwongen zijn na te bootsen. Voorlopig moeten we als ontwikkelaars echter de oude wereld blijven ondersteunen.
