In dit hoofdstuk zullen we de cache coherentie protocollen bespreken om de multicache inconsistentie problemen het hoofd te bieden.
Het Cache Coherentie Probleem
In een multiprocessor systeem kan inconsistentie van gegevens optreden tussen aangrenzende niveaus of binnen hetzelfde niveau van de geheugenhiërarchie. De cache en het hoofdgeheugen kunnen bijvoorbeeld inconsistente kopieën van hetzelfde object hebben.
Als meerdere processoren parallel werken, en onafhankelijk daarvan meerdere caches verschillende kopieën van hetzelfde geheugenblok kunnen bezitten, ontstaat er een cache coherentie probleem. Cachecoherentieregelingen helpen dit probleem te voorkomen door een uniforme toestand te handhaven voor elk gegevensblok in de cache.
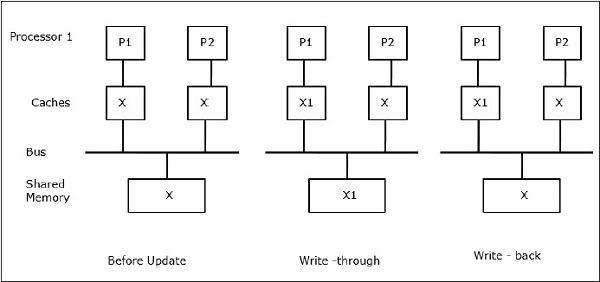
Laat X een element van gedeelde gegevens zijn waarnaar wordt verwezen door twee processoren, P1 en P2. In het begin zijn drie kopieën van X consistent. Als processor P1 een nieuw gegeven X1 in de cache schrijft, wordt met behulp van het doorschrijfbeleid dezelfde kopie onmiddellijk in het gedeelde geheugen geschreven. In dit geval treedt er inconsistentie op tussen het cachegeheugen en het hoofdgeheugen. Wanneer een write-back policy wordt gebruikt, zal het hoofdgeheugen worden bijgewerkt wanneer de gewijzigde gegevens in de cache worden vervangen of ongeldig worden gemaakt.
In het algemeen zijn er drie bronnen van het inconsistentieprobleem –
- Delen van beschrijfbare gegevens
- Procesmigratie
- I/O-activiteit
Snoopy Bus Protocols
Snoopy protocols bereiken gegevensconsistentie tussen het cachegeheugen en het gedeelde geheugen door middel van een bus-gebaseerd geheugensysteem. Write-invalidate- en write-update-beleidslijnen worden gebruikt om de cacheconsistentie te handhaven.
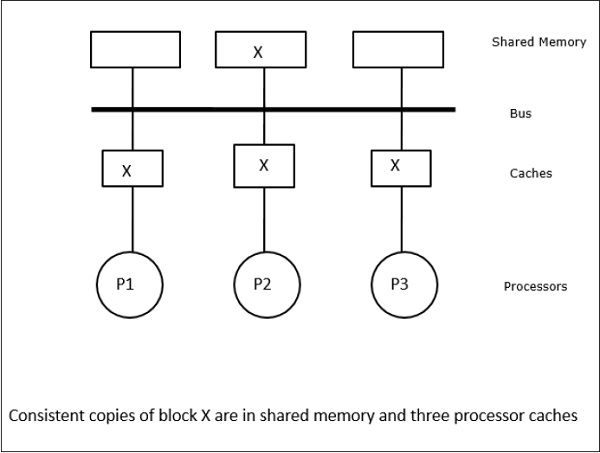
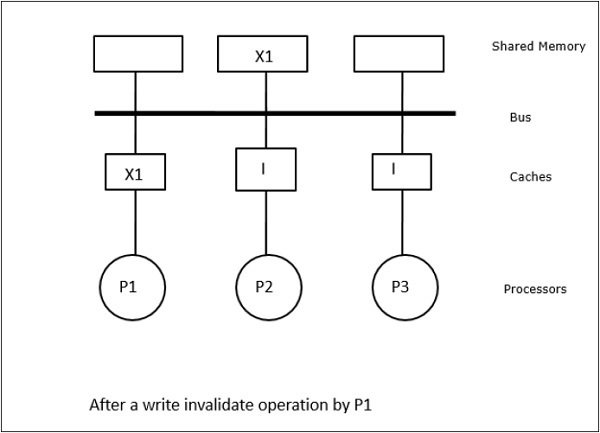
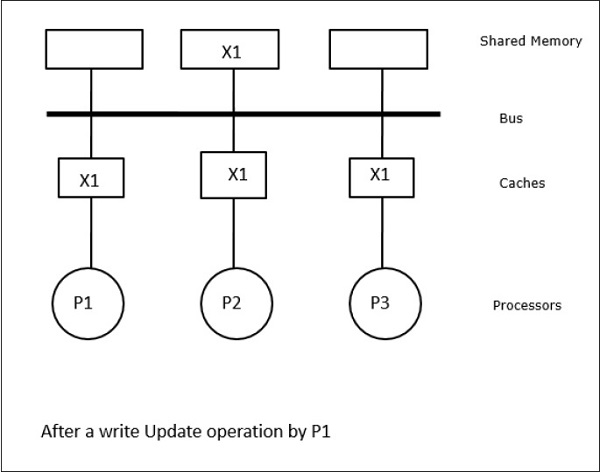
In dit geval hebben we drie processoren P1, P2 en P3 die een consistente kopie van gegevenselement “X” in hun lokale cachegeheugen en in het gedeelde geheugen hebben (afbeelding-a). Processor P1 schrijft X1 in zijn cachegeheugen door gebruik te maken van het write-invalidate protocol. Alle andere kopieën worden dus ongeldig gemaakt via de bus. Dit wordt aangeduid met “I” (figuur-b). Ongeldig gemaakte blokken worden ook wel “dirty” genoemd, d.w.z. dat ze niet gebruikt mogen worden. Het write-update protocol werkt alle cache kopieën bij via de bus. Door gebruik te maken van write back cache wordt ook de geheugenkopie bijgewerkt (afbeelding-c).
Cache Events and Actions
De volgende gebeurtenissen en acties treden op bij de uitvoering van geheugen-toegangs- en ongeldigmakingscommando’s –
-
Read-miss – Wanneer een processor een blok wil lezen en dit zich niet in de cache bevindt, treedt er een read-miss op. Hierdoor wordt een bus-leesbewerking gestart. Als er geen vuile kopie bestaat, levert het hoofdgeheugen dat een consistente kopie heeft, een kopie aan het aanvragende cachegeheugen. Als er een vuile kopie bestaat in een ver cache-geheugen, zal dat cache-geheugen het hoofdgeheugen inhouden en een kopie sturen naar het aanvragende cache-geheugen. In beide gevallen komt de cache-kopie in de geldige status na een leesmiss.
-
Write-hit – Als de kopie zich in de status dirty of reserved bevindt, wordt er lokaal geschreven en is de nieuwe status dirty. Als de nieuwe status geldig is, wordt het commando write-invalidate naar alle caches gestuurd, waardoor hun kopieën ongeldig worden. Als het gedeelde geheugen wordt doorgeschreven, wordt de resulterende status na deze eerste schrijfactie gereserveerd.
-
Write-miss – Als een processor er niet in slaagt om in het lokale cachegeheugen te schrijven, moet de kopie afkomstig zijn uit het hoofdgeheugen of uit een extern cachegeheugen met een vuil blok. Dit wordt gedaan door een read-invalidate commando te sturen, dat alle cache-kopieën ongeldig maakt. Vervolgens wordt de lokale kopie bijgewerkt met de vuile status.
-
Read-hit – Read-hit wordt altijd uitgevoerd in het lokale cachegeheugen zonder een toestandsovergang te veroorzaken of de snoopy-bus te gebruiken voor ongeldigmaking.
-
Blokvervanging – Wanneer een kopie vuil is, moet deze naar het hoofdgeheugen worden teruggeschreven met behulp van de blokvervangingsmethode. Wanneer de kopie zich echter in de status geldig of gereserveerd of ongeldig bevindt, vindt er geen vervanging plaats.
Directory-Based Protocols
Bij gebruik van een meerfasig netwerk voor het bouwen van een grote multiprocessor met honderden processors, moeten de snoopy-cacheprotocollen worden aangepast aan de netwerkmogelijkheden. Omdat broadcasting erg duur is om uit te voeren in een meertraps netwerk, worden de consistentie-opdrachten alleen naar die caches gestuurd die een kopie van het blok bewaren. Dit is de reden voor de ontwikkeling van directory-gebaseerde protocollen voor netwerk-verbonden multiprocessors.
In een directory-gebaseerd protocollensysteem worden de te delen gegevens in een gemeenschappelijke directory geplaatst die de coherentie tussen de caches bewaart. Hier fungeert de directory als een filter waar de processoren toestemming vragen om een entry uit het primaire geheugen in zijn cachegeheugen te laden. Als een entry wordt gewijzigd, wordt deze door de directory bijgewerkt of worden de andere caches met die entry ongeldig gemaakt.
Hardware Synchronisatie Mechanismen
Synchronisatie is een speciale vorm van communicatie waarbij in plaats van datacontrole, informatie wordt uitgewisseld tussen communicerende processen die zich in dezelfde of verschillende processoren bevinden.
Multiprocessor systemen gebruiken hardware mechanismen om low-level synchronisatie operaties te implementeren. De meeste multiprocessoren hebben hardwaremechanismen om atomaire bewerkingen op te leggen, zoals geheugenlezen, -schrijven of lees-wijzig-schrijfbewerkingen om sommige synchronisatieprimitieven te implementeren. Behalve atomaire geheugenbewerkingen worden ook sommige interprocessor interrupts gebruikt voor synchronisatiedoeleinden.
Cache coherency in Shared Memory Machines
Het handhaven van cache coherency is een probleem in multiprocessor systemen wanneer de processoren lokaal cachegeheugen bevatten. Data inconsistentie tussen verschillende caches treedt gemakkelijk op in dit systeem.
De belangrijkste probleemgebieden zijn –
- Delen van beschrijfbare gegevens
- Procesmigratie
- I/O-activiteit
Delen van beschrijfbare gegevens
Wanneer twee processoren (P1 en P2) hetzelfde data-element (X) in hun lokale caches hebben en één proces (P1) schrijft naar het data-element (X), omdat de caches door de lokale cache van P1 worden geschreven, wordt het hoofdgeheugen ook bijgewerkt. Wanneer P2 nu probeert data-element (X) te lezen, vindt hij X niet, omdat het data-element in de cache van P2 verouderd is.
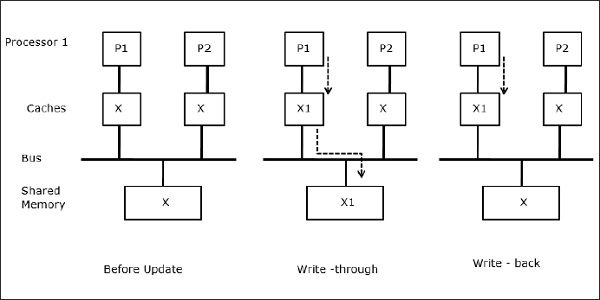
Procesmigratie
In de eerste fase heeft cache van P1 data-element X, terwijl P2 niets heeft. Een proces op P2 schrijft eerst op X en migreert dan naar P1. Nu begint het proces data-element X te lezen, maar omdat de processor P1 verouderde data heeft, kan het proces deze niet lezen. Dus, een proces op P1 schrijft naar het data-element X en migreert dan naar P2. Na de migratie begint een proces op P2 het data-element X te lezen, maar het vindt een verouderde versie van X in het hoofdgeheugen.
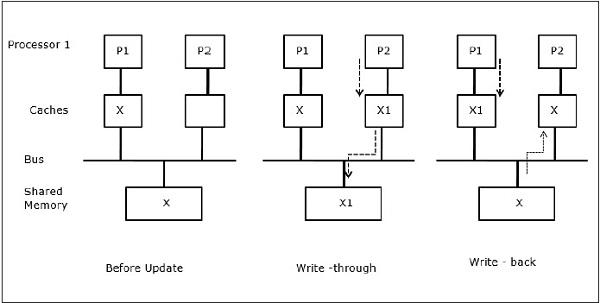
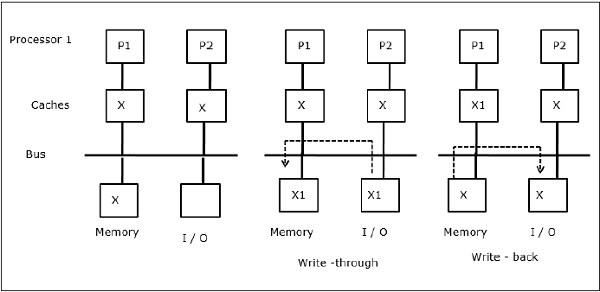
I/O-activiteit
Zoals geïllustreerd in de figuur, wordt een I/O-apparaat toegevoegd aan de bus in een twee-processor multiprocessor architectuur. In het begin bevatten beide caches het data-element X. Wanneer het I/O-apparaat een nieuw element X ontvangt, slaat het het nieuwe element direct in het hoofdgeheugen op. Wanneer nu P1 of P2 (neem aan P1) element X probeert te lezen, krijgt het een verouderde kopie. Dus schrijft P1 naar element X. Als het I/O-apparaat nu X probeert te verzenden, krijgt het een verouderde kopie.
Uniform Memory Access (UMA)
Uniform Memory Access (UMA) architectuur betekent dat het gedeelde geheugen voor alle processoren in het systeem hetzelfde is. Populaire klassen van UMA-machines, die vaak voor (file-)servers worden gebruikt, zijn de zogenaamde Symmetrische Multiprocessoren (SMP’s). In een SMP zijn alle systeembronnen, zoals geheugen, schijven, andere I/O-apparaten, enz. door de processoren op uniforme wijze toegankelijk.
Non-Uniform Memory Access (NUMA)
In een NUMA-architectuur zijn er meerdere SMP-clusters met een intern indirect/shared netwerk, die in een schaalbaar message-passing netwerk met elkaar verbonden zijn. De NUMA-architectuur is dus een logisch gedeelde, fysiek gedistribueerde geheugenarchitectuur.
In een NUMA-machine bepaalt de cache-controller van een processor of een geheugenverwijzing lokaal is voor het SMP-geheugen of dat deze op afstand is. Om het aantal remote geheugentoegangen te verminderen, worden in NUMA-architecturen meestal caching-processoren toegepast die de remote gegevens kunnen cachen. Maar wanneer het om caches gaat, moet de cachecoherentie worden gehandhaafd. Daarom worden deze systemen ook wel CC-NUMA (Cache Coherent NUMA) genoemd.
Cache Only Memory Architecture (COMA)
COMA-machines lijken op NUMA-machines, met als enig verschil dat de hoofdgeheugens van COMA-machines fungeren als direct-mapped of set-associative caches. De gegevensblokken worden gehasht naar een plaats in de DRAM-cache op basis van hun adres. Gegevens die op afstand worden opgehaald, worden feitelijk in het lokale hoofdgeheugen opgeslagen. Bovendien hebben gegevensblokken geen vaste thuislocatie, zij kunnen zich vrijelijk door het systeem bewegen.
COMA-architecturen hebben meestal een hiërarchisch message-passing netwerk. Een schakelaar in een dergelijke boom bevat een directory met gegevenselementen als subboom. Aangezien gegevens geen thuislocatie hebben, moet er expliciet naar worden gezocht. Dit betekent dat een toegang op afstand een traversal langs de schakelaars in de boom vereist om hun mappen te doorzoeken op de vereiste gegevens. Dus, als een switch in het netwerk meerdere verzoeken van zijn subboom ontvangt voor dezelfde gegevens, combineert hij deze tot een enkel verzoek dat naar de ouder van de switch wordt gestuurd. Wanneer de opgevraagde gegevens terugkomen, stuurt de switch meerdere kopieën ervan naar zijn subboom.
COMA versus CC-NUMA
Hieronder volgen de verschillen tussen COMA en CC-NUMA.
-
COMA is flexibeler dan CC-NUMA omdat COMA op transparante wijze de migratie en replicatie van gegevens ondersteunt zonder dat daarvoor het besturingssysteem nodig is.
-
COMA-machines zijn duur en complex om te bouwen omdat ze niet-standaard geheugenbeheerhardware vereisen en het coherency-protocol moeilijker te implementeren is.
-
Toegang op afstand in COMA is vaak langzamer dan in CC-NUMA, omdat het boomnetwerk moet worden doorkruist om de gegevens te vinden.