Volgens de definitie in Wikipedia bestaat Anscombe’s kwartet uit vier datasets die vrijwel identieke eenvoudige statistische eigenschappen hebben, maar toch heel verschillend lijken wanneer ze in een grafiek worden gezet. Elke dataset bestaat uit elf (x,y) punten. Ze werden in 1973 geconstrueerd door de statisticus Francis Anscombe om zowel het belang aan te tonen van het grafisch weergeven van gegevens alvorens ze te analyseren als het effect van uitschieters op statistische eigenschappen.
Eenvoudig begrip:
Ooit vond Francis John “Frank” Anscombe, die een statisticus van grote faam was, 4 sets van 11 datapunten in zijn droom en vroeg de raad als zijn laatste wens om die punten te plotten. Deze 4 reeksen van 11 datapunten zijn hieronder weergegeven.
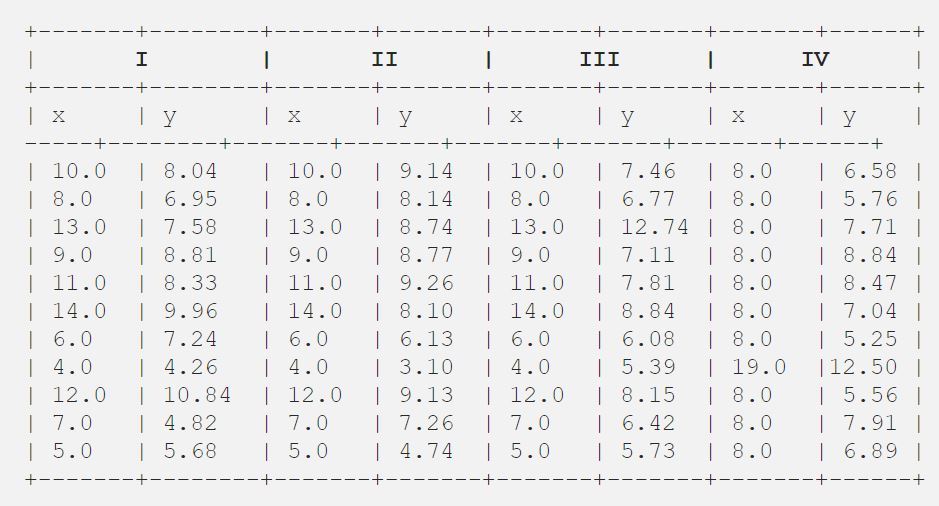
Daarna analyseerde de raad ze met alleen beschrijvende statistieken en vond het gemiddelde, de standaardafwijking en de correlatie tussen x en y.
Download hier het csv-bestand.
Code: Python programma om gemiddelde, standaardafwijking te vinden, en de correlatie tussen x en y
import pandas as pd import statistics from scipy.stats import pearsonr df = pd.read_csv("anscombe.csv") list1 = df list2 = df print('%.1f' % statistics.mean(list1)) print('%.2f' % statistics.stdev(list1)) print('%.1f' % statistics.mean(list2)) print('%.2f' % statistics.stdev(list2)) corr, _ = pearsonr(list1, list2) print('%.3f' % corr) Output:
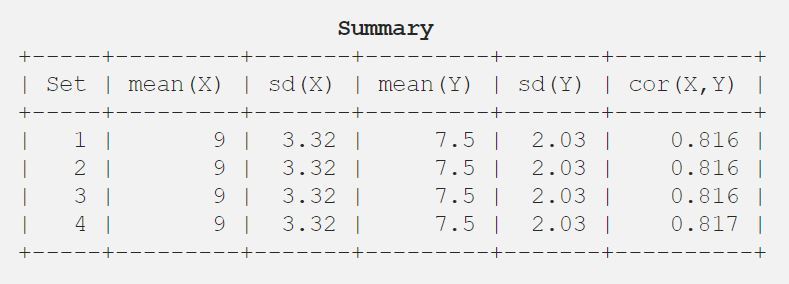
9.03.327.52.030.816
Dus laat ik u het resultaat in tabelvorm zien voor een beter begrip.
Code: Python-programma om scatterplot te tekenen
from matplotlib import pyplot as plt import pandas as pd df = pd.read_csv("anscombe.csv") list1 = df list2 = df plt.scatter(list1, list2) plt.show() Voor regressielijn zie dit.
Output:
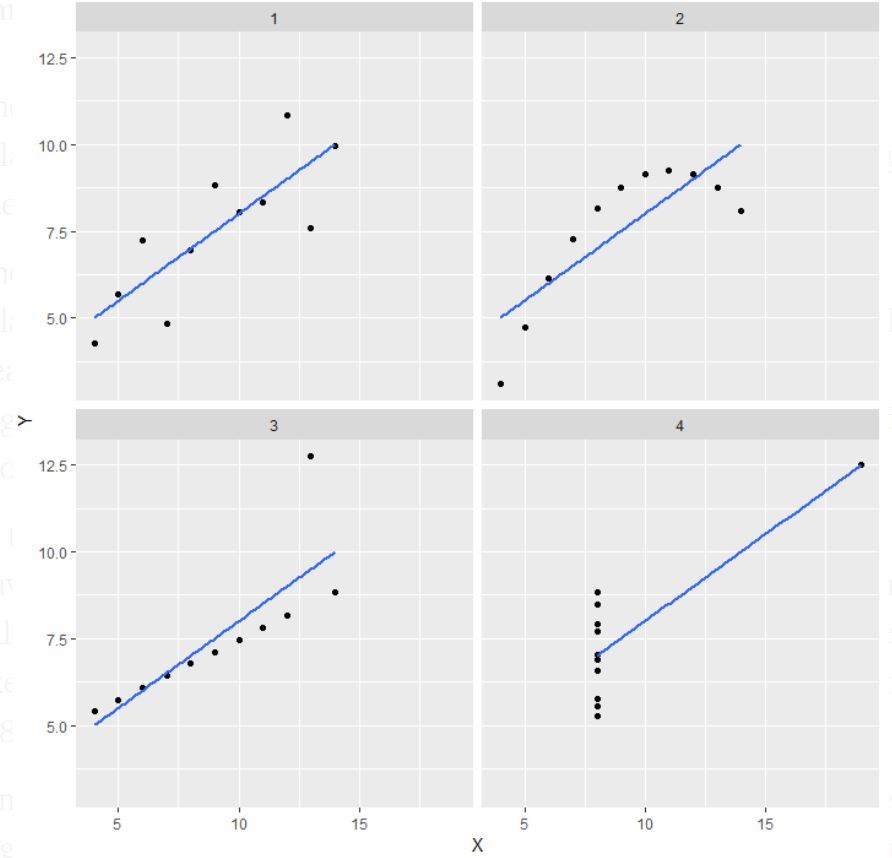
Note: In de definitie wordt vermeld dat het kwartet van Anscombe bestaat uit vier datasets die vrijwel identieke eenvoudige statistische eigenschappen hebben, maar toch zeer verschillend lijken wanneer ze in een grafiek worden weergegeven.
Uitleg van deze output:
- In de eerste (linksboven) als u naar de scatter plot kijkt ziet u dat er een lineair verband lijkt te zijn tussen x en y.
- In de tweede (rechtsboven) als u naar deze figuur kijkt kunt u concluderen dat er een niet-lineair verband is tussen x en y.
- In de derde (linksonder) kun je zeggen dat er een perfect lineair verband is voor alle datapunten, behalve voor één dat een uitbijter lijkt te zijn die ver van die lijn afligt.
- Tot slot, de vierde (rechtsonder) toont een voorbeeld wanneer één punt met een hoog hefboomeffect genoeg is om een hoge correlatiecoëfficiënt te produceren.
Toepassing:
Het kwartet wordt nog vaak gebruikt om het belang te illustreren van het grafisch bekijken van een reeks gegevens alvorens te beginnen met het analyseren volgens een bepaald type van verband, en de ontoereikendheid van statistische basiseigenschappen voor het beschrijven van realistische datasets.