Podczas pisania aplikacji jednostronicowych łatwo i naturalnie jest dać się złapać na próbę stworzenia idealnego doświadczenia dla najczęstszego typu użytkowników – innych ludzi, takich jak my sami. To agresywne skupienie się na jednym rodzaju odwiedzających naszą stronę może często pozostawić na lodzie inną ważną grupę – crawlery i boty używane przez wyszukiwarki takie jak Google. Ten przewodnik pokaże, jak niektóre łatwe do wdrożenia najlepsze praktyki i przejście na renderowanie po stronie serwera mogą dać twojej aplikacji to, co najlepsze z obu światów, jeśli chodzi o doświadczenia użytkownika SPA i SEO.
Wymagania wstępne
Zakładana jest robocza znajomość Angular 5+. Niektóre części przewodnika dotyczą Angular 6, ale jego znajomość nie jest bezwzględnie wymagana.
Wiele nieumyślnych błędów SEO, które popełniamy, pochodzi z nastawienia, że budujemy aplikacje internetowe, a nie strony internetowe. Jaka jest różnica? To subiektywne rozróżnienie, ale powiedziałbym, że z punktu widzenia koncentracji wysiłku:
- Aplikacje internetowe skupiają się na naturalnych i intuicyjnych interakcjach dla użytkowników
- Strony internetowe skupiają się na udostępnianiu informacji
Ale te dwie koncepcje nie muszą się wzajemnie wykluczać! Poprzez prosty powrót do korzeni zasad tworzenia stron internetowych, możemy zachować zgrabny wygląd SPA i umieścić informacje we wszystkich właściwych miejscach, aby stworzyć idealną stronę internetową dla robotów indeksujących.
Nie ukrywaj treści za interakcjami
Jedną z zasad, o której należy myśleć przy projektowaniu komponentów, jest to, że roboty indeksujące są w pewnym sensie głupie. Będą klikać na twoje kotwice, ale nie będą losowo przesuwać palcem po elementach lub klikać na div tylko dlatego, że jego treść mówi „Czytaj więcej”. Jest to sprzeczne z Angular, gdzie powszechną praktyką ukrywania informacji jest „*ngif it out”. I w wielu przypadkach ma to sens! Używamy tej praktyki, aby poprawić wydajność aplikacji, nie mając potencjalnie ciężkich komponentów po prostu siedzących w niewidocznej części strony.
Oznacza to jednak, że jeśli ukryjesz zawartość na swojej stronie poprzez sprytne interakcje, są szanse, że crawler nigdy nie zobaczy tej zawartości. Możesz to złagodzić po prostu używając CSS zamiast *ngif do ukrywania tego typu treści. Oczywiście, inteligentne crawlery zauważą, że tekst jest ukryty i będzie on prawdopodobnie ważony jako mniej ważny niż tekst widoczny. Jest to jednak lepszy rezultat niż to, że tekst nie jest w ogóle dostępny w DOM. Przykład takiego podejścia wygląda następująco:
Nie twórz „wirtualnych kotwic”
Poniższy komponent pokazuje anty-wzór, który często widzę w aplikacjach Angular, które nazywam „wirtualną kotwicą”:
Podstawowo to, co się dzieje, to fakt, że handler kliknięcia jest dołączony do czegoś takiego jak <button> lub <div> tag i ten handler wykona jakąś logikę, a następnie użyje zaimportowanego Angular Router do nawigacji do innej strony. Jest to problematyczne z dwóch powodów:
- Crawlery prawdopodobnie nie będą klikać na tego typu elementy, a nawet jeśli to zrobią, nie ustanowią połączenia między stroną źródłową a docelową.
- Uniemożliwia to korzystanie z bardzo wygodnej funkcji „Otwórz w nowej karcie”, którą przeglądarki zapewniają natywnie dla rzeczywistych znaczników zakotwiczenia.
Zamiast używać wirtualnych kotwic, użyj rzeczywistego znacznika <a> z dyrektywą routerlink. Jeśli potrzebujesz wykonać dodatkową logikę przed nawigacją, nadal możesz dodać obsługę kliknięcia do znacznika zakotwiczenia.
Nie zapomnij o nagłówkach
Jedną z zasad dobrego SEO jest ustalenie względnej ważności różnych tekstów na stronie. Ważnym narzędziem do tego celu w zestawie web developera są nagłówki. Często zdarza się całkowicie zapomnieć o nagłówkach podczas projektowania hierarchii komponentów aplikacji Angular; to, czy są one uwzględnione, czy nie, nie robi żadnej wizualnej różnicy w produkcie końcowym. Jest to jednak coś, co musisz rozważyć, aby upewnić się, że roboty indeksujące skupiają się na właściwych częściach twoich informacji. Rozważ więc użycie znaczników nagłówków tam, gdzie ma to sens. Upewnij się jednak, że elementy zawierające znaczniki nagłówków nie mogą być rozmieszczone w taki sposób, że <h1> pojawia się wewnątrz <h2>.
Uczyń „Strony wyników wyszukiwania” linkowalnymi
Powracając do zasady, że roboty indeksujące są głupie – rozważ stronę wyszukiwania dla firmy produkującej widżety. Crawler nie będzie zobaczyć wejście tekstowe na formularzu i wpisz coś w rodzaju „Toronto widgets”. Koncepcyjnie, aby wyniki wyszukiwania były dostępne dla robotów indeksujących, należy wykonać następujące czynności:
- Należy skonfigurować stronę wyszukiwania, która akceptuje parametry wyszukiwania poprzez ścieżkę i/lub zapytanie.
- Linki do konkretnych wyszukiwań, które Twoim zdaniem mogą zainteresować crawlera, muszą zostać dodane do sitemapy lub jako linki zakotwiczone na innych stronach witryny.
Strategia wokół punktu #2 wykracza poza zakres tego artykułu (niektóre pomocne zasoby to https://yoast.com/internal-linking-for-seo-why-and-how/ i https://moz.com/learn/seo/internal-link). Ważne jest to, że komponenty wyszukiwania i strony powinny być zaprojektowane z myślą o punkcie #1, tak abyś miał elastyczność w tworzeniu linków do każdego rodzaju wyszukiwania, pozwalając na wstrzyknięcie go gdziekolwiek chcesz. Oznacza to importowanie ActivatedRoute i reagowanie na jego zmiany w ścieżce i parametrach zapytania, aby kierować wynikami wyszukiwania na twojej stronie, zamiast polegać wyłącznie na twoich komponentach zapytań i filtrowania na stronie.
Uczyń linkowalność paginacji
Podczas gdy jesteśmy przy temacie stron wyszukiwania, ważne jest, aby upewnić się, że paginacja jest obsługiwana poprawnie, tak aby roboty indeksujące mogły uzyskać dostęp do każdej strony twoich wyników wyszukiwania, jeśli tak postanowią. Istnieje kilka najlepszych praktyk, których możesz przestrzegać, aby to zapewnić.
Powtarzając wcześniejsze punkty: nie używaj „wirtualnych kotwic” dla swoich linków „następnej”, „poprzedniej” i „numeru strony”. Jeśli crawler nie widzi ich jako anchorów, może nigdy nie spojrzeć na nic poza pierwszą stroną. Użyj rzeczywistych tagów <a> z RouterLink dla tych linków. Ponadto, uwzględnij paginację jako opcjonalną część adresów URL do wyszukiwania – często występuje to w formie parametru zapytania page=.
Możesz zapewnić dodatkowe wskazówki dla robotów indeksujących na temat paginacji witryny poprzez dodanie względnych tagów „prev”/”next” <link>. Wyjaśnienie, dlaczego mogą one być przydatne, można znaleźć pod adresem: https://webmasters.googleblog.com/2011/09/pagination-with-relnext-and-relprev.html. Oto przykład usługi, która może automatycznie zarządzać tymi znacznikami <link> w sposób przyjazny dla Angulara:
Include dynamic metadata
Jedną z pierwszych rzeczy, które robimy w nowej aplikacji Angulara jest dostosowanie pliku index.html – ustawienie favicon, dodanie responsywnych meta tagów i najprawdopodobniej ustawienie zawartości tagów <title> i <meta name=”description”> na jakieś sensowne wartości domyślne dla twojej aplikacji. Ale jeśli zależy Ci na tym, jak Twoje strony pokazują się w wynikach wyszukiwania, nie możesz na tym poprzestać. Na każdej trasie dla swojej aplikacji powinieneś dynamicznie ustawiać znaczniki title i description tak, aby pasowały do zawartości strony. Nie tylko pomoże to robotom indeksującym, ale także użytkownikom, którzy będą mogli zobaczyć pouczające tytuły kart przeglądarki, zakładek i informacje o podglądzie, gdy udostępnią link w mediach społecznościowych. Poniższy snippet pokazuje, jak można zaktualizować te informacje w sposób przyjazny dla Angulara, używając klas Meta i Title:
Test na łamanie kodu przez roboty indeksujące
Niektóre biblioteki firm trzecich lub SDK albo się wyłączają, albo nie mogą być załadowane z ich dostawcy hostingu, gdy zostaną wykryte agenty użytkownika należące do robotów indeksujących wyszukiwarek. Jeśli jakaś część Twojej funkcjonalności opiera się na tych zależnościach, powinieneś zapewnić awaryjne rozwiązanie dla zależności, które nie pozwalają na działanie robotów indeksujących. Przynajmniej Twoja aplikacja powinna w takich przypadkach degradować się z gracją, a nie przerywać proces renderowania klienta. Świetnym narzędziem do testowania interakcji Twojego kodu z robotami indeksującymi jest strona testowa Google Mobile Friendly: https://search.google.com/test/mobile-friendly. Poszukaj danych wyjściowych takich jak te, które oznaczają, że crawlerowi zablokowano dostęp do SDK:

Reducing bundle size with Angular 6
Rozmiar pakietów w aplikacjach Angular jest dobrze znanym problemem, ale istnieje wiele optymalizacji, które deweloper może wykonać, aby go złagodzić, w tym korzystanie z kompilacji AOT i bycie konserwatywnym przy dołączaniu bibliotek stron trzecich. Jednakże, aby uzyskać najmniejsze możliwe wiązki Angulara dzisiaj wymaga aktualizacji do Angulara 6. Powodem tego jest wymagana równoległa aktualizacja do RXJS 6, która oferuje znaczące ulepszenia w możliwości potrząsania drzewem. Aby faktycznie uzyskać to ulepszenie, istnieje kilka twardych wymagań dla twojej aplikacji:
- Usuń bibliotekę rxjs-compat (która jest domyślnie dodawana w procesie aktualizacji Angular 6) – ta biblioteka sprawia, że twój kod jest wstecznie kompatybilny z RXJS 5, ale pokonuje ulepszenia związane z potrząsaniem drzewami.
- Upewnij się, że wszystkie zależności odwołują się do Angular 6 i nie używają biblioteki rxjs-compat.
- Importuj operatory RXJS pojedynczo zamiast hurtowo, aby upewnić się, że tree shaking może wykonać swoją pracę. Zobacz https://github.com/ReactiveX/rxjs/blob/master/docs_app/content/guide/v6/migration.md, aby uzyskać pełny przewodnik na temat migracji.
Rendering na serwerze
Nawet po zastosowaniu wszystkich poprzednich najlepszych praktyk może się okazać, że twoja witryna Angular nie jest umieszczona w rankingu tak wysoko, jak byś chciał. Jednym z możliwych powodów jest jedna z podstawowych wad frameworków SPA w kontekście SEO – polegają one na Javascript do renderowania strony. Problem ten może objawiać się na dwa sposoby:
- O ile Googlebot może wykonać Javascript, nie każdy crawler to zrobi. W przypadku tych, które tego nie robią, wszystkie twoje strony będą dla nich wyglądały na puste.
- Aby na stronie pojawiła się użyteczna zawartość, robot indeksujący będzie musiał poczekać na pobranie pakietów Javascript, przetworzenie ich przez silnik, uruchomienie kodu i zwrócenie wszelkich zewnętrznych XHR – wtedy w DOM pojawi się zawartość. W porównaniu z bardziej tradycyjnymi językami renderowanymi przez serwer, w których informacje są dostępne w DOM, gdy tylko dokument trafi do przeglądarki, SPA prawdopodobnie zostanie tutaj nieco ukarane.
Na szczęście Angular ma rozwiązanie tego problemu, które pozwala na serwowanie aplikacji w formie renderowanej przez serwer: Angular Universal (https://github.com/angular/universal). Typowa implementacja wykorzystująca to rozwiązanie wygląda następująco:
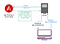
- Klient zgłasza żądanie określonego adresu url do Twojego serwera aplikacji.
- Serwer proksesuje żądanie do usługi renderowania, którą jest Twoja aplikacja Angular działająca w kontenerze Node.js. Ta usługa może być (ale nie musi) na tej samej maszynie co serwer aplikacji.
- Serwerowa wersja aplikacji renderuje kompletny HTML i CSS dla żądanej ścieżki i zapytania, w tym znaczniki <script>, aby pobrać aplikację Angular klienta.
- Przeglądarka otrzymuje stronę i może natychmiast wyświetlić zawartość. Aplikacja kliencka ładuje się asynchronicznie, a gdy jest gotowa, ponownie wyświetla bieżącą stronę i zastępuje statyczny HTML, który wyrenderował serwer. Teraz strona internetowa zachowuje się jak SPA dla każdej interakcji idącej dalej. Ten proces powinien być bezproblemowy dla użytkownika przeglądającego witrynę.
Ta magia nie przychodzi za darmo, jednak. Kilka razy w tym przewodniku wspomniałem, jak robić rzeczy w sposób „przyjazny dla Angulara”. To, co naprawdę miałem na myśli, to „przyjazny dla serwera renderującego Angulara”. Wszystkie najlepsze praktyki, które przeczytałeś o Angularze, takie jak nie dotykanie DOM bezpośrednio lub ograniczenie użycia setTimeout, wrócą do Ciebie, jeśli nie będziesz ich przestrzegał – w postaci wolno ładujących się lub nawet całkowicie zepsutych stron. Obszerną listę uniwersalnych 'gotchas’ można znaleźć pod adresem: https://github.com/angular/universal/blob/master/docs/gotchas.md
Hello Server
Istnieje kilka różnych opcji, aby uruchomić projekt z Universal:
- Dla projektów Angular 5 możesz uruchomić następujące polecenie w istniejącym projekcie:
ng generate universal server - Dla projektów Angular 6 nie ma jeszcze oficjalnego polecenia CLI do tworzenia działającego projektu Universal z klientem i serwerem. Możesz uruchomić następujące polecenie strony trzeciej w istniejącym projekcie:
ng add @ng-toolkit/universal - Możesz również sklonować to repozytorium, aby użyć go jako punktu wyjścia dla swojego projektu lub scalić z istniejącym: https://github.com/angular/universal-starter
Dependency injection is your (server’s) friend
W typowej konfiguracji Angular Universal będziesz miał trzy różne moduły aplikacji – moduł tylko dla przeglądarki, moduł tylko dla serwera i moduł współdzielony. Możemy to wykorzystać na naszą korzyść, tworząc abstrakcyjne usługi, które nasze komponenty wstrzykują i dostarczają implementacje specyficzne dla klienta i serwera w każdym module. Rozważmy poniższy przykład usługi, która może ustawić fokus na elemencie: definiujemy abstrakcyjną usługę, implementacje klienta i serwera, dostarczamy je w odpowiednich modułach i importujemy abstrakcyjną usługę w komponentach.
Poprawianie zależności szkodliwych dla serwera
Każdy komponent innej firmy, który nie przestrzega najlepszych praktyk Angulara (np. używa dokumentu lub okna), spowoduje awarię renderowania na serwerze każdej strony, która używa tego komponentu. Najlepszą opcją jest znalezienie uniwersalnej, kompatybilnej alternatywy dla biblioteki. Czasami nie jest to możliwe, lub ograniczenia czasowe uniemożliwiają zastąpienie tej zależności. W takich przypadkach istnieją dwie główne opcje zapobiegania interferencji biblioteki.
Możesz *ngIf out obraźliwych komponentów na serwerze. Łatwym sposobem na to jest stworzenie dyrektywy, która może zdecydować, czy element będzie renderowany w zależności od bieżącej platformy:
Niektóre biblioteki są bardziej problematyczne; sam akt importowania kodu może równie dobrze próbować używać zależności tylko dla przeglądarki, które spowodują awarię renderowania serwera. Przykładem jest każda biblioteka, która importuje jquery jako zależność npm, zamiast oczekiwać, że konsument będzie miał jquery dostępne w zakresie globalnym. Aby upewnić się, że te biblioteki nie zepsują serwera, musimy zarówno *ngIf usunąć komponent, jak i usunąć zależną bibliotekę z webpacka. Zakładając, że biblioteka, która importuje jquery nazywa się 'jquery-funpicker’, możemy napisać regułę webpack jak ta poniżej, aby usunąć ją z kompilacji serwera:
To również wymaga umieszczenia pliku o zawartości {} w webpack/empty.json w strukturze projektu. Rezultatem będzie to, że biblioteka otrzyma pustą implementację dla swojej deklaracji importu 'jquery-funpicker’, ale to nie ma znaczenia, ponieważ usunęliśmy ten komponent wszędzie w aplikacji serwera za pomocą naszej nowej dyrektywy.
Popraw wydajność przeglądarki – nie powtarzaj swoich XHR
Częścią projektu Universal jest to, że wersja kliencka aplikacji będzie ponownie uruchamiać całą logikę, która została uruchomiona na serwerze, aby utworzyć widok klienta – włączając w to wykonywanie tych samych wywołań XHR do twojego back-endu, które serwer już wykonał! Powoduje to dodatkowe obciążenie back-endu i percepcję dla robotów indeksujących, że strona wciąż ładuje zawartość, mimo że prawdopodobnie będzie pokazywać te same informacje po powrocie XHR. Jeśli nie ma obawy, że dane są nieaktualne, powinieneś uniemożliwić aplikacji klienckiej duplikowanie XHRów, które serwer już wykonał. Moduł TransferHttpCacheModule z Angulara jest poręcznym modułem, który może w tym pomóc: https://github.com/angular/universal/blob/master/docs/transfer-http.md
Pod maską, moduł TransferHttpCacheModule używa klasy TransferState, która może być używana do dowolnego ogólnego transferu stanu z serwera do klienta:
Pre render to move time-to-first-byte towards zero
Jedną z rzeczy do rozważenia podczas używania Universal (lub nawet usługi renderowania stron trzecich, takiej jak https://prerender.io/) jest to, że strona renderowana przez serwer będzie miała dłuższy czas, zanim pierwszy bajt trafi do przeglądarki, niż strona renderowana przez klienta. Powinno to mieć sens, jeśli weźmiesz pod uwagę, że aby serwer dostarczył stronę renderowaną przez klienta, w zasadzie musi po prostu dostarczyć statyczną stronę index.html. Universal nie zakończy renderowania, dopóki aplikacja nie zostanie uznana za „stabilną”. Stabilność w kontekście Angulara jest skomplikowana, ale dwa największe czynniki przyczyniające się do opóźnienia stabilności będą prawdopodobnie:
- Niezrozumiałe XHRs
- Niezrozumiałe wywołania setTimeout
Jeśli nie masz sposobu na dalszą optymalizację powyższego, opcją na zmniejszenie czasu do pierwszego bajtu jest po prostu wstępne renderowanie niektórych lub wszystkich stron aplikacji i serwowanie ich z pamięci podręcznej. Angular Universal starter repo, do którego link znajduje się na początku tego poradnika, zawiera implementację pre-renderingu. Kiedy masz już wstępnie wyrenderowane strony, w zależności od architektury, rozwiązaniem buforującym może być coś takiego jak Varnish, Redis, CDN, lub kombinacja technologii. Usuwając czas renderowania ze ścieżki odpowiedzi od serwera do klienta, możesz zapewnić bardzo szybkie początkowe ładowanie stron dla robotów indeksujących i ludzkich użytkowników twojej aplikacji.
Koniec
Wiele z technik w tym artykule nie jest po prostu dobrych dla robotów indeksujących wyszukiwarek, tworzą one bardziej znajome doświadczenie strony internetowej również dla twoich użytkowników. Coś tak prostego jak posiadanie informacyjnych tytułów zakładek dla różnych stron czyni świat różnicy za stosunkowo niski koszt wdrożenia. Przyjmując renderowanie po stronie serwera, nie zostaniesz uderzony przez nieoczekiwane luki produkcyjne, takie jak ludzie próbujący udostępnić witrynę na portalach społecznościowych i otrzymujący pustą miniaturę.
Jak sieć ewoluuje, mam nadzieję, że doczekamy dnia, w którym serwery indeksujące i serwery przechwytywania ekranu będą współdziałać z witrynami w sposób, który jest bardziej zgodny z tym, jak użytkownicy współdziałają na swoich urządzeniach – odróżniając aplikacje internetowe od starych stron internetowych, które są zmuszone emulować. Na razie jednak, jako deweloperzy, musimy nadal wspierać stary świat.

.