Zgodnie z definicją podaną w Wikipedii, kwartet Anscombe’a składa się z czterech zbiorów danych, które mają prawie identyczne proste właściwości statystyczne, ale wydają się bardzo różne, gdy się je wykreśli. Każdy zestaw danych składa się z jedenastu (x,y) punktów. Zostały one skonstruowane w 1973 roku przez statystyka Francisa Anscombe’a w celu zademonstrowania zarówno znaczenia wykresów danych przed ich analizą, jak i wpływu wartości odstających na właściwości statystyczne.
Proste zrozumienie:
Once Francis John „Frank” Anscombe, który był statystykiem o wielkiej reputacji, znalazł 4 zestawy 11 punktów danych w swoim śnie i poprosił radę jako jego ostatnie życzenie, aby wykreślić te punkty. Te 4 zestawy 11 punktów danych są podane poniżej.
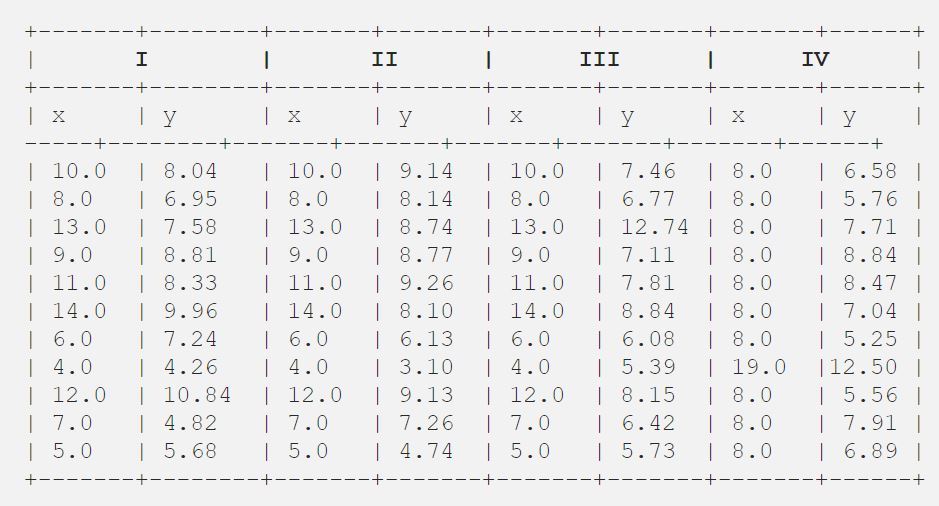
Po tym, rada przeanalizowała je używając tylko statystyk opisowych i znalazła średnią, odchylenie standardowe i korelację między x i y.
Proszę pobrać plik csv tutaj.
Kod: Program w Pythonie do znalezienia średniej, odchylenia standardowego, i korelację między x i y
import pandas as pd import statistics from scipy.stats import pearsonr df = pd.read_csv("anscombe.csv") list1 = df list2 = df print('%.1f' % statistics.mean(list1)) print('%.2f' % statistics.stdev(list1)) print('%.1f' % statistics.mean(list2)) print('%.2f' % statistics.stdev(list2)) corr, _ = pearsonr(list1, list2) print('%.3f' % corr) Wyjście:
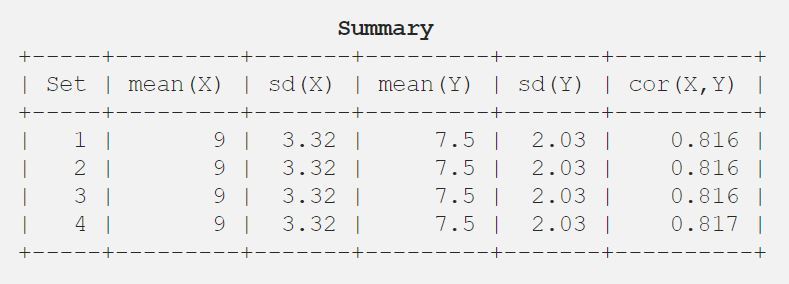
9.03.327.52.030.816
Pozwól więc, że pokażę ci wynik w sposób tabelaryczny dla lepszego zrozumienia.
Code: Python program to plot scatter plot
from matplotlib import pyplot as plt import pandas as pd df = pd.read_csv("anscombe.csv") Dla linii regresji odnieś to.
Wyjście:
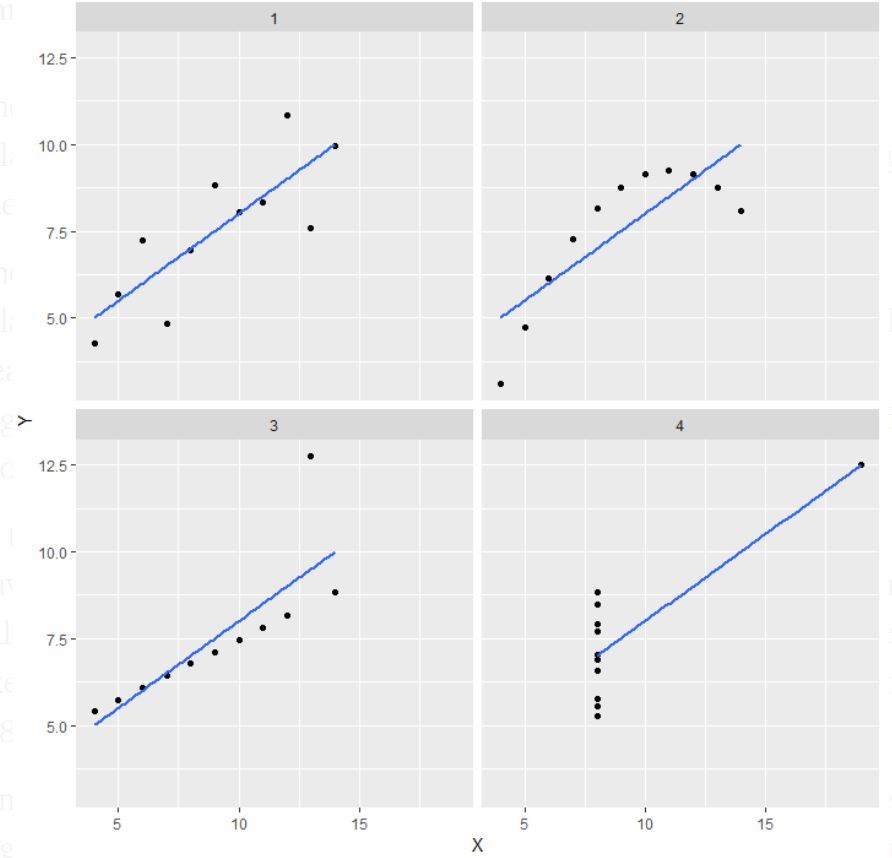
Uwaga: W definicji jest wspomniane, że kwartet Anscombe’a obejmuje cztery zbiory danych, które mają prawie identyczne proste właściwości statystyczne, ale wydają się bardzo różne, gdy się je wykresuje.
Objaśnienie tych danych wyjściowych:
- W pierwszym (u góry po lewej), jeśli spojrzysz na wykres rozrzutu, zobaczysz, że wydaje się, iż istnieje liniowa zależność między x i y.
- W drugim (u góry po prawej), jeśli spojrzysz na ten rysunek, możesz dojść do wniosku, że istnieje nieliniowa zależność między x i y.
- W trzecim (na dole po lewej) można powiedzieć, że istnieje doskonała liniowa zależność dla wszystkich punktów danych, z wyjątkiem jednego, który wydaje się być odstający, który jest wskazany być daleko od tej linii.
- Wreszcie, czwarty (na dole po prawej) pokazuje przykład, kiedy jeden punkt o wysokiej dźwigni wystarczy, aby uzyskać wysoki współczynnik korelacji.
Zastosowanie:
Kwartet jest nadal często używany do zilustrowania znaczenia graficznego spojrzenia na zestaw danych przed rozpoczęciem analizy według określonego typu relacji, a także nieadekwatności podstawowych właściwości statystyki do opisywania realistycznych zbiorów danych.