W tym rozdziale omówimy protokoły koherencji pamięci podręcznej, aby poradzić sobie z problemami niespójności w pamięci wieloprocesorowej.
Problem spójności pamięci podręcznej
W systemie wieloprocesorowym niespójność danych może występować między sąsiednimi poziomami lub w obrębie tego samego poziomu hierarchii pamięci. Na przykład, pamięć podręczna i pamięć główna mogą mieć niespójne kopie tego samego obiektu.
Jako że wiele procesorów działa równolegle i niezależnie wiele pamięci podręcznych może posiadać różne kopie tego samego bloku pamięci, stwarza to problem spójności pamięci podręcznej. Schematy spójności pamięci podręcznej pomagają uniknąć tego problemu poprzez utrzymywanie jednolitego stanu dla każdego zbuforowanego bloku danych.
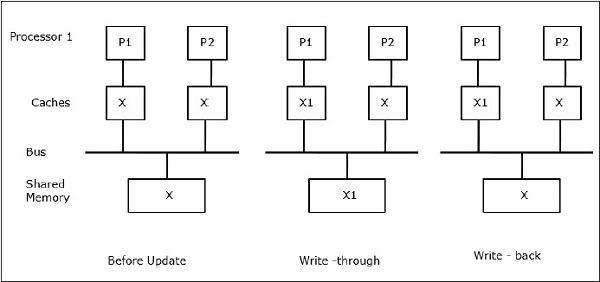
Niech X będzie elementem współdzielonych danych, do którego odwołują się dwa procesory, P1 i P2. Na początku trzy kopie X są spójne. Jeśli procesor P1 zapisze nową daną X1 do pamięci podręcznej, to stosując politykę write-through, ta sama kopia zostanie natychmiast zapisana do pamięci współdzielonej. W tym przypadku występuje niespójność pomiędzy pamięcią podręczną a pamięcią główną. Gdy stosowana jest polityka write-back, pamięć główna zostanie zaktualizowana, gdy zmodyfikowane dane w pamięci podręcznej zostaną zastąpione lub unieważnione.
Ogólnie, istnieją trzy źródła problemu niespójności –
- Współdzielenie danych zapisywalnych
- Migracja procesów
- Aktywność wejścia/wyjścia
Protokoły magistrali Snoopy
Protokoły Snoopy osiągają spójność danych między pamięcią podręczną a pamięcią współdzieloną poprzez system pamięci oparty na magistrali. Polityki write-invalidate i write-update są używane do utrzymania spójności pamięci podręcznej.
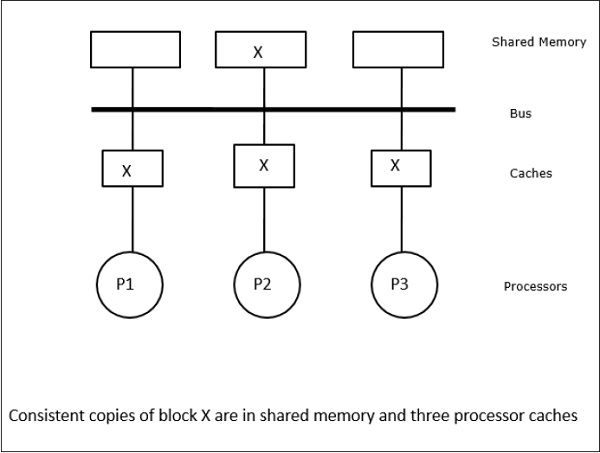
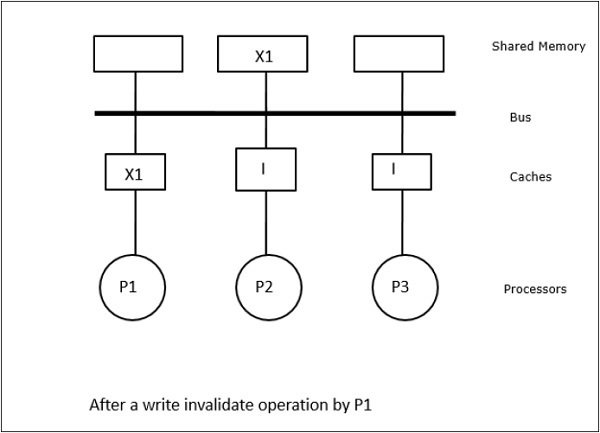
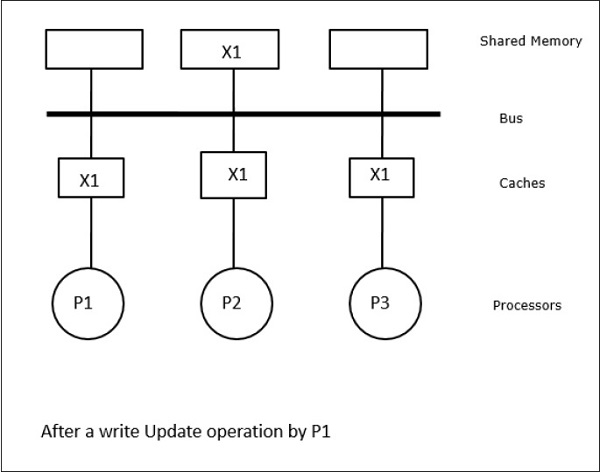
W tym przypadku mamy trzy procesory P1, P2 i P3 posiadające spójne kopie elementu danych „X” w ich lokalnej pamięci podręcznej i w pamięci współdzielonej (Rysunek-a). Procesor P1 zapisuje X1 do swojej pamięci cache używając protokołu write-invalidate. Wszystkie pozostałe kopie są więc unieważniane przez magistralę. Oznaczane jest to literą „I” (rysunek-b). Bloki unieważnione są również znane jako brudne, tzn. nie powinny być używane. Protokół write-update aktualizuje wszystkie kopie pamięci podręcznej poprzez magistralę. Używając write back cache, aktualizowana jest również kopia pamięci (rysunek-c).
Zdarzenia i akcje pamięci podręcznej
Następujące zdarzenia i akcje występują przy wykonywaniu rozkazów dostępu do pamięci i unieważnienia –
-
Read-miss – Gdy procesor chce odczytać blok, a nie ma go w pamięci podręcznej, występuje read-miss. Inicjuje to operację bus-read. Jeśli nie istnieje brudna kopia, to pamięć główna, która ma spójną kopię, dostarcza kopię do żądającej pamięci podręcznej. Jeżeli brudna kopia istnieje w odległej pamięci podręcznej, to ta pamięć podręczna zastąpi pamięć główną i wyśle kopię do żądającej pamięci podręcznej. W obu przypadkach kopia pamięci podręcznej wejdzie w ważny stan po pominięciu odczytu.
-
Write-hit – Jeśli kopia jest w brudnym lub zarezerwowanym stanie, zapis jest wykonywany lokalnie, a nowy stan jest brudny. Jeśli nowy stan jest prawidłowy, komenda write-invalidate jest rozsyłana do wszystkich cache’ów, unieważniając ich kopie. Gdy pamięć współdzielona jest zapisywana, wynikowy stan jest zarezerwowany po tym pierwszym zapisie.
-
Write-miss – Jeśli procesorowi nie uda się zapisać w lokalnej pamięci cache, kopia musi pochodzić albo z pamięci głównej, albo ze zdalnej pamięci cache z brudnym blokiem. Odbywa się to poprzez wysłanie komendy read-invalidate, która unieważnia wszystkie kopie pamięci podręcznej. Następnie lokalna kopia jest aktualizowana stanem dirty.
-
Read-hit – Read-hit jest zawsze wykonywany w lokalnej pamięci cache bez powodowania przejścia stanu lub używania magistrali snoopy do unieważniania.
-
Block replacement – Kiedy kopia jest brudna, ma być zapisana z powrotem do pamięci głównej metodą block replacement. Natomiast gdy kopia jest w stanie valid lub reserved lub invalid, wymiana nie będzie miała miejsca.
Protokoły oparte na katalogach
Używając sieci wielostopniowej do budowy dużego multiprocesora z setkami procesorów, należy zmodyfikować protokoły snoopy cache, aby dostosować je do możliwości sieci. Rozgłaszanie jest bardzo kosztowne do wykonania w sieci wielostopniowej, polecenia spójności są wysyłane tylko do tych pamięci podręcznych, które posiadają kopię bloku. Jest to powód opracowania protokołów opartych na katalogach dla połączonych sieciowo wieloprocesorów.
W systemie protokołów opartych na katalogach dane, które mają być współdzielone, są umieszczane we wspólnym katalogu, który utrzymuje spójność między cache’ami. Tutaj katalog działa jak filtr, w którym procesory pytają o zgodę na załadowanie wpisu z pamięci głównej do swojej pamięci podręcznej. Jeśli wpis jest zmieniony, katalog albo go aktualizuje, albo unieważnia inne pamięci podręczne z tym wpisem.
Sprzętowe mechanizmy synchronizacji
Synchronizacja jest specjalną formą komunikacji, w której zamiast kontroli danych, informacje są wymieniane między komunikującymi się procesami rezydującymi w tych samych lub różnych procesorach.
Systemy wieloprocesorowe używają mechanizmów sprzętowych do implementacji niskopoziomowych operacji synchronizacji. Większość multiprocesorów posiada mechanizmy sprzętowe do narzucania operacji atomowych, takich jak operacje odczytu, zapisu lub odczytu-modyfikacji-zapisu pamięci w celu implementacji niektórych prymitywów synchronizacji. Inne niż atomowe operacje pamięci, niektóre przerwania międzyprocesorowe są również używane do celów synchronizacji.
Cache Coherency in Shared Memory Machines
Utrzymanie spójności pamięci podręcznej jest problemem w systemie wieloprocesorowym, gdy procesory zawierają lokalną pamięć podręczną. Niespójność danych pomiędzy różnymi cache’ami łatwo występuje w tym systemie.
Główne obszary problemowe to –
- Współdzielenie danych zapisywalnych
- Migracja procesów
- Aktywność wejścia/wyjścia
Współdzielenie danych zapisywalnych
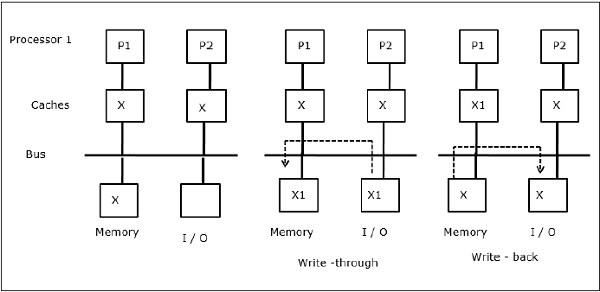
Gdy dwa procesory (P1 i P2) mają ten sam element danych (X) w swoich lokalnych pamięciach podręcznych i jeden proces (P1) zapisuje do elementu danych (X), ponieważ cache jest zapisywany przez lokalną pamięć podręczną P1, pamięć główna jest również aktualizowana. Teraz, gdy P2 próbuje odczytać element danych (X), nie znajduje X, ponieważ element danych w pamięci podręcznej P2 stał się nieaktualny.
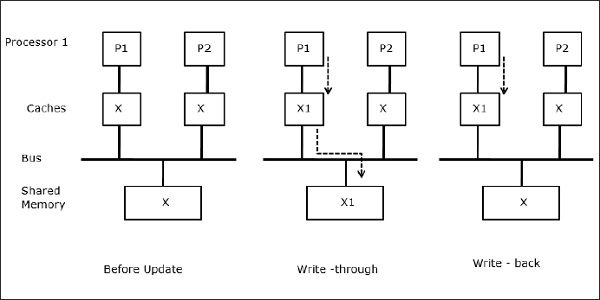
Migracja procesów
W pierwszym etapie, pamięć podręczna P1 ma element danych X, podczas gdy P2 nie ma nic. Proces na P2 najpierw zapisuje na X, a następnie migruje na P1. Teraz proces zaczyna czytać element danych X, ale ponieważ procesor P1 ma nieaktualne dane, proces nie może ich odczytać. Proces na P1 zapisuje więc do elementu danych X, a następnie migruje do P2. Po migracji proces na P2 zaczyna czytać element danych X, ale w pamięci głównej znajduje nieaktualną wersję X.
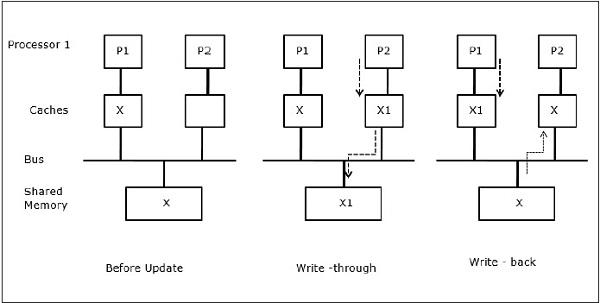
Aktywność I/O
Jak pokazano na rysunku, w dwuprocesorowej architekturze wieloprocesorowej do magistrali dodane jest urządzenie I/O. Na początku obie pamięci podręczne zawierają element danych X. Gdy urządzenie wejścia/wyjścia otrzyma nowy element X, zapisuje go bezpośrednio w pamięci głównej. Teraz, gdy P1 lub P2 (załóżmy, że P1) próbuje odczytać element X, otrzymuje nieaktualną kopię. Więc P1 zapisuje do elementu X. Teraz, jeśli urządzenie I/O próbuje przesłać X, dostaje nieaktualną kopię.
Uniform Memory Access (UMA)
Architektura UMA oznacza, że pamięć współdzielona jest taka sama dla wszystkich procesorów w systemie. Popularnymi klasami maszyn UMA, które są powszechnie stosowane w serwerach (plików), są tzw. wieloprocesory symetryczne (SMP). W SMP wszystkie zasoby systemowe, takie jak pamięć, dyski, inne urządzenia wejścia/wyjścia itp. są dostępne dla procesorów w jednolity sposób.
Non-Uniform Memory Access (NUMA)
W architekturze NUMA istnieje wiele klastrów SMP posiadających wewnętrzną pośrednią/współdzieloną sieć, które są połączone w skalowalną sieć typu message-passing. Tak więc architektura NUMA jest logicznie współdzieloną, fizycznie rozproszoną architekturą pamięci.
W maszynie NUMA, kontroler pamięci podręcznej procesora określa, czy odwołanie do pamięci jest lokalne w pamięci SMP, czy jest zdalne. Aby zmniejszyć liczbę zdalnych dostępów do pamięci, architektury NUMA zwykle stosują procesory buforujące, które mogą buforować zdalne dane. Ale kiedy pamięci podręczne są zaangażowane, spójność pamięci podręcznej musi być utrzymywana. Dlatego systemy te są również znane jako CC-NUMA (Cache Coherent NUMA).
Cache Only Memory Architecture (COMA)
Maszyny COMA są podobne do maszyn NUMA, z tą różnicą, że pamięci główne maszyn COMA działają jako pamięci podręczne z bezpośrednim mapowaniem lub set-associative cache. Bloki danych są haszowane do miejsca w pamięci podręcznej DRAM zgodnie z ich adresami. Dane, które są pobierane zdalnie, są w rzeczywistości przechowywane w lokalnej pamięci głównej. Ponadto bloki danych nie mają stałej lokalizacji macierzystej, mogą się swobodnie przemieszczać w całym systemie.
Architektury COMA mają najczęściej hierarchiczną sieć przekazywania komunikatów. Przełącznik w takim drzewie zawiera katalog z elementami danych jako jego poddrzewo. Ponieważ dane nie mają lokalizacji macierzystej, muszą być jawnie wyszukane. Oznacza to, że zdalny dostęp wymaga trawersowania wzdłuż przełączników w drzewie, aby przeszukać ich katalogi w poszukiwaniu wymaganych danych. Tak więc, jeśli przełącznik w sieci otrzymuje wiele żądań ze swojego poddrzewa dla tych samych danych, łączy je w jedno żądanie, które jest wysyłane do rodzica przełącznika. Gdy żądane dane powrócą, przełącznik wysyła wiele ich kopii w dół swojego poddrzewa.
COMA kontra CC-NUMA
Następnie przedstawiono różnice między COMA i CC-NUMA.
-
COMA ma tendencję do bycia bardziej elastyczną niż CC-NUMA, ponieważ COMA transparentnie wspiera migrację i replikację danych bez potrzeby systemu operacyjnego.
-
Maszyny COMA są drogie i skomplikowane w budowie, ponieważ wymagają niestandardowego sprzętu do zarządzania pamięcią, a protokół spójności jest trudniejszy do wdrożenia.
-
Dostęp zdalny w COMA jest często wolniejszy niż w CC-NUMA, ponieważ sieć drzewiasta musi zostać przemierzona, aby znaleźć dane.
.