>
>
Ao escrever aplicações de uma única página, é fácil e natural ser apanhado na tentativa de criar a experiência ideal para o tipo mais comum de utilizadores – outros humanos como nós. Este foco agressivo num tipo de visitante do nosso site pode muitas vezes deixar outro grupo importante de fora ao frio – os rastejadores e robots utilizados pelos motores de busca como o Google. Este guia irá mostrar como algumas das melhores práticas fáceis de implementar e um movimento para renderização do lado do servidor podem dar à sua aplicação o melhor de dois mundos quando se trata de experiência de usuário de SPA e SEO.
Prerequisites
Um conhecimento de trabalho do Angular 5+ é assumido. Algumas partes do guia lidam com o Angular 6, mas o conhecimento dele não é estritamente necessário.
Muitos dos erros inadvertidos de SEO que cometemos provêm da mentalidade de que estamos a construir aplicações web e não web sites. Qual é a diferença? É uma distinção subjetiva, mas eu diria que do ponto de vista de esforço:
- As aplicações web focam em interações naturais e intuitivas para os usuários
- Os sites web focam em tornar a informação geralmente disponível
Mas estes dois conceitos não precisam ser mutuamente exclusivos! Simplesmente voltando às raízes das regras de desenvolvimento de web sites, podemos manter a aparência manhosa dos SPAs e colocar informações em todos os lugares certos para fazer um web site ideal para os crawlers.
Não esconda o conteúdo atrás das interações
Um princípio a ser considerado ao projetar componentes é que os crawlers são meio burros. Eles vão clicar em suas âncoras, mas não vão passar por cima de elementos aleatoriamente ou clicar em um div só porque seu conteúdo diz “Leia mais”. Isto vem a ser uma odisseia com o Angular, onde uma prática comum para esconder informação é “*ngif it out”. E muitas vezes isto faz sentido! Nós usamos essa prática para melhorar o desempenho do aplicativo não tendo componentes potencialmente pesados apenas sentados em uma parte não visível da página.
No entanto, isso significa que se você esconder conteúdo em sua página através de interações inteligentes, as chances são de que um rastreador nunca vai ver esse conteúdo. Você pode mitigar isso simplesmente usando CSS em vez de *ngif para esconder esse tipo de conteúdo. É claro que os rastejadores inteligentes notarão que o texto está escondido e provavelmente será ponderado como menos importante que o texto visível. Mas este é um resultado melhor do que o texto não ser acessível no DOM. Um exemplo desta abordagem parece ser:
Não criar “Virtual Anchors”
O componente abaixo mostra um anti-padrão que eu vejo muito em aplicações angulares que eu chamo de ‘âncora virtual’:
Basicamente o que está acontecendo é que um manipulador de cliques é anexado a algo como um tag <button> ou <div> e esse manipulador irá executar alguma lógica, então use o Roteador Angular importado para navegar para outra página. Isto é problemático por duas razões:
- Roteadores provavelmente não clicarão nestes tipos de elementos, e mesmo que o façam, eles não estabelecerão um link entre a página de origem e a página de destino.
- Isto impede a função muito conveniente ‘Abrir em nova aba’ que os navegadores fornecem nativamente para as tags âncoras reais.
Em vez de usar âncoras virtuais, use uma tag real <a> com a diretiva routerlink. Se você precisar executar uma lógica extra antes de navegar, você ainda pode adicionar um manipulador de cliques à âncora tag.
Não se esqueça dos títulos
Um dos princípios do bom SEO é estabelecer a importância relativa de diferentes textos em uma página. Uma ferramenta importante para isso no kit do desenvolvedor web são os cabeçalhos. É comum esquecer completamente os cabeçalhos ao desenhar a hierarquia de componentes de uma aplicação angular; a inclusão ou não deles não faz diferença visual no produto final. Mas isso é algo que você precisa considerar para garantir que os rastreadores se concentrem nas partes corretas de suas informações. Portanto, considere o uso de etiquetas de cabeçalho onde faz sentido. No entanto, certifique-se de que os componentes que incluem etiquetas de cabeçalho não podem ser organizados de tal forma que um <h1> apareça dentro de um <h2>.
Faça o link “Search Result Pages”
Retornando ao princípio de como os rastejadores são burros – considere uma página de pesquisa para uma empresa widget. Um crawler não vai ver uma entrada de texto em um formulário e digitar algo como “widgets de Toronto”. Conceitualmente, para disponibilizar os resultados da pesquisa aos crawlers é necessário fazer o seguinte:
- Uma página de pesquisa precisa ser configurada que aceite parâmetros de pesquisa através do caminho e/ou da consulta.
- Links para pesquisas específicas que você acha que o rastreador pode achar interessante devem ser adicionados ao mapa do site ou como links de âncora em outras páginas do site.
A estratégia em torno do ponto #2 está fora do escopo deste artigo (Alguns recursos úteis são https://yoast.com/internal-linking-for-seo-why-and-how/ e https://moz.com/learn/seo/internal-link). O importante é que os componentes de pesquisa e as páginas devem ser concebidos tendo em mente o ponto #1 para que você tenha a flexibilidade de criar um link para qualquer tipo de pesquisa possível, permitindo que ele seja injetado onde você quiser. Isto significa importar o ActivatedRoute e reagir às suas alterações nos parâmetros de caminho e consulta para conduzir os resultados da pesquisa na sua página, em vez de confiar apenas na sua consulta na página e na filtragem dos componentes.
Faça a paginação linkável
Apesar do assunto das páginas de pesquisa, é importante certificar-se de que a paginação é tratada correctamente para que os rastejadores possam aceder a cada uma das páginas dos resultados da sua pesquisa se assim o desejarem. Há um par de melhores práticas que você pode seguir para garantir isso.
Para reiterar pontos anteriores: não use “Âncoras Virtuais” para seus links “próximo”, “anterior” e “número de página”. Se um rastejador não consegue vê-los como âncoras, pode nunca olhar para nada além da sua primeira página. Use as tags reais <a> com o RouterLink para estas. Além disso, inclua paginação como parte opcional de suas URLs de busca com link – isto geralmente vem na forma de uma página= parâmetro de consulta.
Você pode fornecer dicas adicionais para os rastreadores sobre a paginação do seu site através da adição de tags relativas “prev”/”next” <link>. Uma explicação sobre porque estas podem ser úteis pode ser encontrada em: https://webmasters.googleblog.com/2011/09/pagination-with-relnext-and-relprev.html. Aqui está um exemplo de um serviço que pode gerir automaticamente estas <link> tags de uma forma amigável para Angular:
Incluir metadados dinâmicos
Uma das primeiras coisas que fazemos a uma nova aplicação Angular é fazer ajustes no índice.html – definir o favicon, adicionar meta tags responsivas e muito provavelmente definir o conteúdo do arquivo <title> e <meta name=”description”> tags para alguns padrões sensatos para a sua aplicação. Mas se você se importa com a forma como suas páginas aparecem nos resultados da busca, você não pode parar por aí. Em cada rota de sua aplicação você deve definir dinamicamente as tags de título e descrição para combinar com o conteúdo da página. Isso não só ajudará os rastreadores, como também ajudará os usuários, pois eles poderão ver os títulos informativos das guias do navegador, os marcadores e as informações de visualização quando compartilharem um link nas mídias sociais. O snippet abaixo mostra como você pode atualizá-los de uma forma amigável usando as classes Meta e Título:
Teste para rastreadores que quebram seu código
Algumas bibliotecas de terceiros ou SDKs ou desligam ou não podem ser carregadas do provedor de hospedagem quando agentes de usuários que pertencem aos rastreadores dos mecanismos de busca são detectados. Se alguma parte de sua funcionalidade depende dessas dependências, você deve fornecer um fallback para as dependências que desautorizam os crawlers. No mínimo, a sua aplicação deve degradar-se graciosamente nestes casos, em vez de travar o processo de renderização do cliente. Uma ótima ferramenta para testar a interação do seu código com os rastreadores é a página de teste do Google Mobile Friendly: https://search.google.com/test/mobile-friendly. Procure uma saída como esta que significa que o rastejador está bloqueando o acesso a um SDK:

>
Tamanho do pacote com Angular 6
Tamanho do pacote com Angular 6
Tamanho do pacote com Angular é um problema bem conhecido, mas há muitas otimizações que um desenvolvedor pode fazer para mitigá-lo, incluindo o uso de compilações AOT e ser conservador com a inclusão de bibliotecas de terceiros. No entanto, para obter os menores pacotes Angular possíveis hoje em dia, é necessário atualizar para o Angular 6. A razão para isso é a atualização paralela necessária para o RXJS 6, que oferece melhorias significativas na sua capacidade de abalar árvores. Para realmente obter esta melhoria, existem alguns requisitos difíceis para a sua aplicação:
- Remover a biblioteca rxjs-compat (que é adicionada por padrão no processo de atualização do Angular 6) – esta biblioteca torna o seu código compatível com o RXJS 5, mas derrota as melhorias de trepidação.
- Segure que todas as dependências estão referenciando o Angular 6 e não use a biblioteca rxjs-compat.
- Importe os operadores RXJS um de cada vez ao invés de por atacado para garantir que o tremor de árvore possa fazer seu trabalho. Veja https://github.com/ReactiveX/rxjs/blob/master/docs_app/content/guide/v6/migration.md para um guia completo sobre migração.
Renderização de Servidor
Even após seguir todas as melhores práticas anteriores você pode descobrir que o seu site Angular não está classificado tão alto quanto você gostaria que estivesse. Uma das razões possíveis para isso é uma das falhas fundamentais dos frameworks de SPA no contexto de SEO – eles dependem do Javascript para renderizar a página. Este problema pode se manifestar de duas maneiras:
- Embora o Googlebot possa executar Javascript, nem todos os crawler o farão. Para aqueles que não o fazem, todas as suas páginas parecerão essencialmente vazias para eles.
- Para uma página mostrar conteúdo útil, o crawler terá que esperar que os pacotes de Javascript sejam baixados, o mecanismo para analisá-los, o código a ser executado e qualquer XHR externo a ser retornado – então haverá conteúdo no DOM. Comparado com os idiomas mais tradicionais de renderização do servidor onde a informação está disponível no DOM assim que o documento chega ao navegador, um SPA provavelmente será penalizado de alguma forma aqui.
Felizmente, Angular tem uma solução para este problema que permite servir uma aplicação em uma forma renderizada no servidor: Angular Universal (https://github.com/angular/universal). Uma implementação típica usando esta solução se parece com:
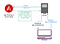
- Um cliente faz um pedido de uma determinada url para o seu servidor de aplicação.
- >O servidor faz um proxy do pedido para um serviço de renderização que é a sua aplicação Angular rodando em um container Node.js. Este serviço poderia estar (mas não é necessariamente) na mesma máquina do servidor de aplicação.
- A versão servidor da aplicação renderiza HTML e CSS completos para o caminho e consulta solicitados, incluindo <script> tags para baixar a aplicação Angular cliente.
- O navegador recebe a página e pode mostrar o conteúdo imediatamente. A aplicação cliente carrega de forma assíncrona e, uma vez pronta, reenvia a página atual e substitui o HTML estático que o servidor renderizou. Agora o site se comporta como um SPA para qualquer interação que vá adiante. Este processo deve ser perfeito para um usuário navegando no site.
Esta mágica não vem de graça, no entanto. Algumas vezes neste guia eu mencionei como fazer as coisas de uma forma ‘Angular-friendly’. O que eu realmente quis dizer foi ‘Angular server-rendering-friendly’. Todas as melhores práticas que você leu sobre Angular, como não tocar diretamente no DOM ou limitar o uso do setTimeout, voltarão para te morder se você não as tiver seguido – na forma de carregamento lento ou mesmo páginas totalmente quebradas. Uma extensa lista de ‘gotchas’ universais pode ser encontrada em: https://github.com/angular/universal/blob/master/docs/gotchas.md
Hello Server
Existem algumas opções diferentes para ter um projeto em execução com Universal:
- Para projetos Angular 5 você pode executar o seguinte comando em um projeto existente:
ng generate universal server - Para projetos Angular 6 ainda não existe um comando CLI oficial para criar um projeto Universal em execução com um cliente e servidor. Você pode executar o seguinte comando de terceiros em um projeto existente:
ng add @ng-toolkit/universal - Você também pode clonar este repositório para usar como um ponto de partida para o seu projeto ou para fundir em um projeto existente: https://github.com/angular/universal-starter
Injeção de dependência é seu amigo (servidor)
Em uma configuração típica do Angular Universal você terá três módulos de aplicação diferentes – um módulo apenas de navegador, um módulo apenas de servidor e um módulo compartilhado. Podemos usar isso em nosso benefício criando serviços abstratos que nossos componentes injetam, e fornecer implementações específicas de cliente e servidor em cada módulo. Considere este exemplo de um serviço que pode definir o foco para um elemento: definimos um serviço abstrato, cliente e implementações de servidor, os fornecemos em seus respectivos módulos, e importamos o serviço abstrato em componentes.
Fixar dependências servidor-hostile
Um componente de terceiros que não siga as melhores práticas angulares (ou seja, use documento ou janela) vai travar a renderização do servidor de qualquer página que use esse componente. A melhor opção é encontrar uma alternativa compatível com a Universal para a biblioteca. Às vezes isso não é possível, ou restrições de tempo impedem a substituição da dependência. Nestes casos há duas opções principais para evitar que a biblioteca interfira.
Você pode *se ofender os componentes no servidor. Uma maneira fácil de fazer isso é criar uma diretiva que possa decidir se um elemento será renderizado dependendo da plataforma atual:
Algumas bibliotecas são mais problemáticas; o próprio ato de importar o código pode muito bem tentar usar dependências somente do navegador que irão travar a renderização do servidor. Um exemplo é qualquer biblioteca que importa jquery como uma dependência npm, ao invés de esperar que o consumidor tenha jquery disponível em âmbito global. Para garantir que essas bibliotecas não danifiquem o servidor, precisamos tanto *se o componente ofensivo for eliminado, como tirar a biblioteca dependente do pacote da Web. Assumindo que a biblioteca que importa o jquery se chama ‘jquery-funpicker’, podemos escrever uma regra do webpack como a que está abaixo para retirá-la do build do servidor:
Isso também requer colocar um arquivo com o conteúdo {} no webpack/empty.json na estrutura do seu projeto. O resultado será que a biblioteca terá uma implementação vazia para sua declaração de importação ‘jquery-funpicker’, mas isso não importa porque removemos esse componente em toda parte da aplicação do servidor com nossa nova diretiva.
Melhorar o desempenho do navegador – não repita seu XHRs
Parte do design do Universal é que a versão cliente da aplicação irá executar novamente toda a lógica que foi executada no servidor para criar a visão cliente – incluindo fazer as mesmas chamadas XHR para o seu back end que a renderização do servidor já fez! Isso cria uma carga extra no seu back end e uma percepção para os rastreadores de que a página ainda está carregando conteúdo, mesmo que ela provavelmente exibirá a mesma informação após o retorno desses XHRs. A menos que haja uma preocupação com a estabilidade dos dados, você deve evitar que a aplicação cliente duplique XHRs que o servidor já fez. O TransferHttpCacheModule da Angular é um módulo útil que pode ajudar com isso: https://github.com/angular/universal/blob/master/docs/transfer-http.md
Atrás da capa, o TransferHttpCacheModule usa a classe TransferState que pode ser usada para qualquer transferência de estado de propósito geral do servidor para o cliente:
Pre renderização para mover o tempo para o primeiro byte para zero
Uma coisa a considerar ao usar Universal (ou mesmo um serviço de renderização de terceiros como https://prerender.io/) é que uma página renderizada no servidor terá um tempo maior antes do primeiro byte atingir o navegador do que uma página renderizada no cliente. Isto deve fazer sentido quando você considera que para um servidor entregar uma página renderizada pelo cliente, ele essencialmente só precisa entregar uma página index.html estática. A Universal não completará uma renderização até que a aplicação seja considerada ‘estável’. A estabilidade no contexto do Angular é complicada, mas os dois maiores contribuintes para o atraso da estabilidade provavelmente serão:
- Superior XHRs
- Setuperior setTimeout chamadas
Se você não tem como otimizar ainda mais o acima descrito, uma opção para reduzir seu tempo de renderização de algumas ou todas as páginas de sua aplicação e servi-las a partir de um cache. O repositório de inicialização Angular Universal, que está ligado anteriormente neste guia, vem com uma implementação para pré-renderização. Uma vez que você tenha suas páginas pré-renderizadas, dependendo de sua arquitetura, uma solução de cache pode ser algo como Verniz, Redis, um CDN, ou uma combinação de tecnologias. Removendo o tempo de renderização do caminho de resposta servidor-a-cliente, você pode fornecer cargas iniciais de página extremamente rápidas para os crawlers e os usuários humanos de sua aplicação.
Conclusion
Muitas das técnicas neste artigo não são boas apenas para os crawlers dos mecanismos de busca, elas criam uma experiência de web site mais familiar para seus usuários também. Algo tão simples como ter títulos informativos de separadores para páginas diferentes faz um mundo de diferença por um custo de implementação relativamente baixo. Ao abraçar a renderização do lado do servidor, você não será atingido por lacunas de produção inesperadas, como pessoas tentando compartilhar seu site em mídias sociais e obtendo uma miniatura em branco.
À medida que a web evolui, espero que vejamos um dia em que os crawlers e os servidores de captura de tela interajam com os sites de uma forma mais alinhada com a forma como os usuários interagem em seus dispositivos – diferenciando as aplicações web dos sites antigos que são forçados a emular. Por enquanto, porém, como desenvolvedores devemos continuar a suportar o mundo antigo.

>
>
>
>