Neste capítulo, discutiremos os protocolos de coerência de cache para lidar com os problemas de inconsistência de cache múltipla.
O problema de coerência do cache
Num sistema multiprocessador, a inconsistência de dados pode ocorrer entre níveis adjacentes ou dentro do mesmo nível da hierarquia da memória. Por exemplo, o cache e a memória principal podem ter cópias inconsistentes do mesmo objeto.
Como vários processadores operam em paralelo, e independentemente vários caches podem possuir cópias diferentes do mesmo bloco de memória, isto cria um problema de coerência do cache. Os esquemas de coerência do cache ajudam a evitar este problema mantendo um estado uniforme para cada bloco de dados em cache.
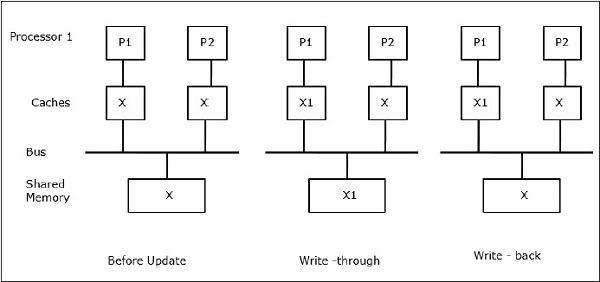
Deixe X ser um elemento de dados compartilhados que foi referenciado por dois processadores, P1 e P2. No início, três cópias de X são consistentes. Se o processador P1 escreve um novo dado X1 no cache, usando a política de gravação, a mesma cópia será escrita imediatamente na memória compartilhada. Neste caso, ocorre inconsistência entre a memória cache e a memória principal. Quando uma política de gravação é usada, a memória principal será atualizada quando os dados modificados na cache forem substituídos ou invalidados.
Em geral, existem três fontes de problemas de inconsistência –
- Partilha de dados graváveis
- Migração de processos
- Atividade I/O
Protocolos de barramento de bisbilhotice
Protocolos de bisbilhotice alcançam consistência de dados entre a memória cache e a memória compartilhada através de um sistema de memória baseado em barramento. As políticas de write-invalidate e write-update são usadas para manter a consistência da cache.
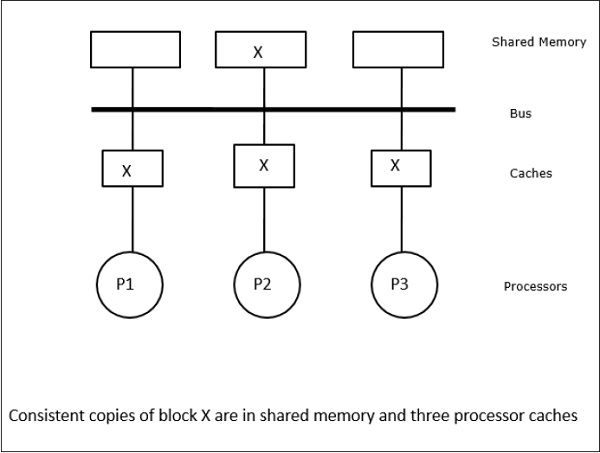
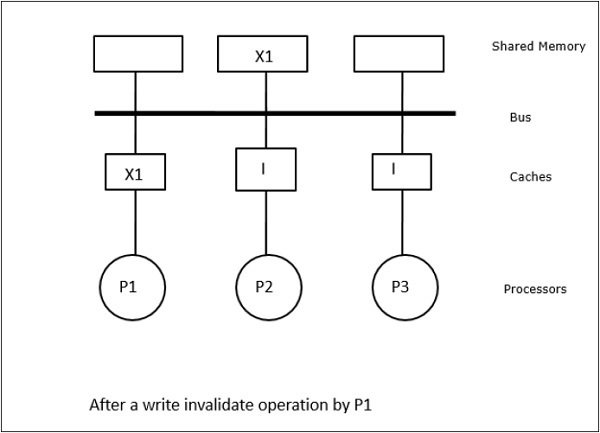
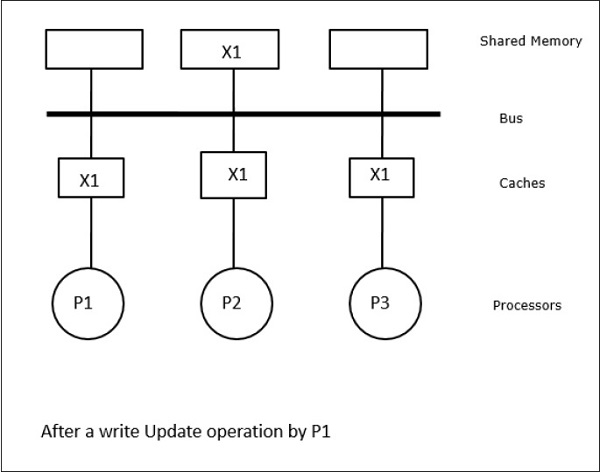
Neste caso, temos três processadores P1, P2 e P3 tendo uma cópia consistente do elemento de dados ‘X’ na sua memória cache local e na memória compartilhada (Figura-a). O processador P1 grava X1 na sua memória cache usando o protocolo write-invalidate. Assim, todas as outras cópias são invalidadas através do bus. Ele é denotado por ‘I’ (Figura-b). Blocos invalidados também são conhecidos como sujos, ou seja, eles não devem ser usados. O protocolo write-update actualiza todas as cópias do cache através do bus. Ao usar o cache de write-back, a cópia de memória também é atualizada (Figura-c).
Cache Events and Actions
Following events and actions occur on the execution of memory-access and invalidation commands –
-
Read-miss – Quando um processador quer ler um bloco e ele não está no cache, ocorre uma read-miss. Isto inicia uma operação de leitura de barramento. Se não existir nenhuma cópia suja, então a memória principal que tem uma cópia consistente, fornece uma cópia para a memória cache solicitante. Se uma cópia suja existir numa memória cache remota, essa cache irá restringir a memória principal e enviar uma cópia para a memória cache solicitante. Em ambos os casos, a cópia de cache entrará no estado válido após uma falha de leitura.
-
Write-hit – Se a cópia estiver em estado sujo ou reservado, a escrita é feita localmente e o novo estado está sujo. Se o novo estado for válido, o comando write-invalidate é transmitido para todos os caches, invalidando as suas cópias. Quando a memória partilhada é gravada, o estado resultante é reservado após esta primeira gravação.
-
Write-miss – Se um processador falhar a gravação na memória cache local, a cópia deve vir da memória principal ou de uma memória cache remota com um bloco sujo. Isto é feito através do envio de um comando read-invalidate, que invalidará todas as cópias de cache. Então a cópia local é atualizada com estado sujo.
-
Read-hit – Read-hit é sempre executado na memória cache local sem causar uma transição de estado ou usando o barramento snoopy para invalidação.
-
Block replacement – Quando uma cópia está suja, ela deve ser escrita de volta na memória principal pelo método de substituição de bloco. Entretanto, quando a cópia está em estado válido ou reservado ou inválido, nenhuma substituição ocorrerá.
Protocolos Baseados em Diretórios
Usando uma rede de múltiplos estágios para construir um grande multiprocessador com centenas de processadores, os protocolos de cache snoopy precisam ser modificados para se adequarem às capacidades da rede. Sendo a transmissão muito cara para ser executada em uma rede multi-estágio, os comandos de consistência são enviados apenas para aqueles caches que mantêm uma cópia do bloco. Esta é a razão para o desenvolvimento de protocolos baseados em diretórios para multiprocessadores conectados à rede.
Num sistema de protocolos baseados em diretórios, os dados a serem compartilhados são colocados em um diretório comum que mantém a coerência entre os caches. Aqui, o diretório funciona como um filtro onde os processadores pedem permissão para carregar uma entrada da memória primária para sua memória cache. Se uma entrada for alterada o diretório atualiza ou invalida os outros caches com essa entrada.
Mecanismos de sincronização de hardware
Sincronização é uma forma especial de comunicação onde ao invés de controle de dados, a informação é trocada entre processos de comunicação residentes no mesmo ou em processadores diferentes.
Sistemas multiprocessadores usam mecanismos de hardware para implementar operações de sincronização de baixo nível. A maioria dos multiprocessadores tem mecanismos de hardware para impor operações atômicas como operações de leitura, escrita ou leitura-modificação-escrita de memória para implementar algumas primitivas de sincronização. Além das operações de memória atômica, algumas interrupções entre processadores também são usadas para fins de sincronização.
Cache Coherency in Shared Memory Machines
Maintaining cache coherency is a problem in multiprocessor system when the processor contain the local cache memory. A inconsistência de dados entre diferentes caches ocorre facilmente neste sistema.
As principais áreas de preocupação são –
- Partilha de dados graváveis
- Migração de processos
- Atividade I/O
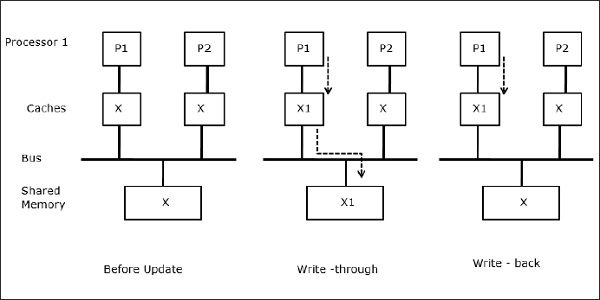
Partilha de dados graváveis
Quando dois processadores (P1 e P2) têm o mesmo elemento de dados (X) nos seus caches locais e um processo (P1) escreve para o elemento de dados (X), como as caches são gravadas no cache local de P1, a memória principal também é atualizada. Agora quando P2 tenta ler o elemento de dados (X), não encontra X porque o elemento de dados na cache de P2 tornou-se desactualizado.
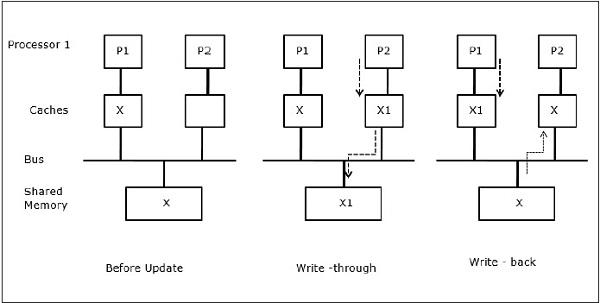
Migração de Processos
Na primeira fase, a cache de P1 tem o elemento de dados X, enquanto que P2 não tem nada. Um processo em P2 primeiro escreve em X e depois migra para P1. Agora, o processo começa a ler o elemento de dados X, mas como o processador P1 tem dados desatualizados, o processo não pode lê-los. Então, um processo em P1 escreve no elemento de dados X e depois migra para P2. Após a migração, um processo em P2 começa a ler o elemento de dados X mas encontra uma versão desatualizada do X na memória principal.
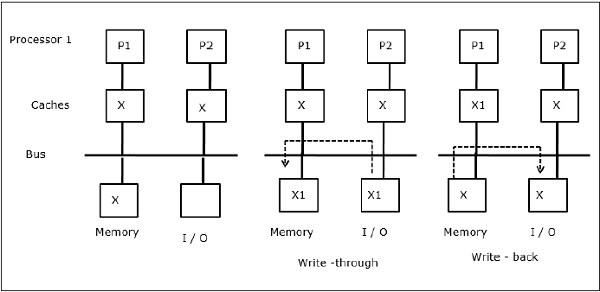
Atividade I/O
Como ilustrado na figura, um dispositivo I/O é adicionado ao barramento em uma arquitetura de dois processadores multiprocessadores. No início, ambos os caches contêm o elemento de dados X. Quando o dispositivo de E/S recebe um novo elemento X, ele armazena o novo elemento diretamente na memória principal. Agora, quando P1 ou P2 (assumir P1) tenta ler o elemento X, ele recebe uma cópia desatualizada. Então, P1 escreve no elemento X. Agora, se o dispositivo de E/S tenta transmitir X ele recebe uma cópia desatualizada.
Acesso Uniforme de Memória (UMA)
Arquitetura de Acesso Uniforme de Memória (UMA) significa que a memória compartilhada é a mesma para todos os processadores no sistema. As classes populares de máquinas UMA, que são comumente usadas para servidores (de arquivos), são os chamados Multiprocessadores Simétricos (SMPs). Em um SMP, todos os recursos do sistema como memória, discos, outros dispositivos de E/S, etc. são acessíveis pelos processadores de maneira uniforme.
Non-Uniform Memory Access (NUMA)
Na arquitetura NUMA, há múltiplos clusters SMP com uma rede interna indireta/partilhada, que são conectados em uma rede de passagem de mensagens escalável. Portanto, a arquitetura NUMA é logicamente compartilhada fisicamente.
Em uma máquina NUMA, o controlador de cache de um processador determina se uma referência de memória é local para a memória do SMP ou se é remota. Para reduzir o número de acessos à memória remota, as arquiteturas NUMA normalmente aplicam processadores de cache que podem armazenar em cache os dados remotos. Mas quando os caches estão envolvidos, a coerência do cache precisa ser mantida. Portanto, esses sistemas também são conhecidos como CC-NUMA (Cache Coherent NUMA).
Cache Only Memory Architecture (COMA)
COMA são similares às máquinas NUMA, com a única diferença de que as memórias principais das máquinas COMA atuam como caches diretamente mapeadas ou associadas. Os blocos de dados são colocados em hash em um local na cache DRAM de acordo com seus endereços. Os dados que são buscados remotamente são na verdade armazenados na memória principal local. Além disso, os blocos de dados não têm uma localização fixa, eles podem se mover livremente através do sistema.
COMA arquiteturas na maioria das vezes têm uma rede de passagem de mensagens hierárquica. Um switch em tal árvore contém um diretório com elementos de dados como sua sub-árvore. Uma vez que os dados não têm localização home, eles devem ser explicitamente pesquisados. Isto significa que um acesso remoto requer uma travessia ao longo dos switches na árvore para procurar os dados necessários em seus diretórios. Assim, se um switch na rede recebe várias solicitações da sua sub-árvore para os mesmos dados, ele as combina em uma única solicitação que é enviada para o pai do switch. Quando os dados solicitados retornam, o switch envia múltiplas cópias dos mesmos para a sub-árvore.
COMA versus CC-NUMA
Seguindo são as diferenças entre COMA e CC-NUMA.
-
COMA tende a ser mais flexível que CC-NUMA porque COMA suporta transparentemente a migração e replicação de dados sem a necessidade do SO.
-
COMA são máquinas caras e complexas de construir porque precisam de hardware de gerenciamento de memória não-padrão e o protocolo de coerência é mais difícil de implementar.
-
Os acessos de memorização no COMA são muitas vezes mais lentos do que os do CC-NUMA, pois a rede de árvore precisa ser atravessada para encontrar os dados.