De acordo com a definição dada na Wikipedia, o quarteto de Anscombe é composto por quatro conjuntos de dados que têm propriedades estatísticas simples e quase idênticas, mas que parecem muito diferentes quando agarrados. Cada conjunto de dados é composto por onze (x,y) pontos. Eles foram construídos em 1973 pelo estatístico Francis Anscombe para demonstrar tanto a importância dos dados gráficos antes de analisá-los quanto o efeito dos outliers sobre as propriedades estatísticas.
Simples understanding:
Após Francis John “Frank” Anscombe que era um estatístico de grande reputação encontrou 4 conjuntos de 11 pontos de dados em seu sonho e solicitou ao conselho como seu último desejo de traçar esses pontos. Esses 4 conjuntos de 11 pontos de dados são dados abaixo.
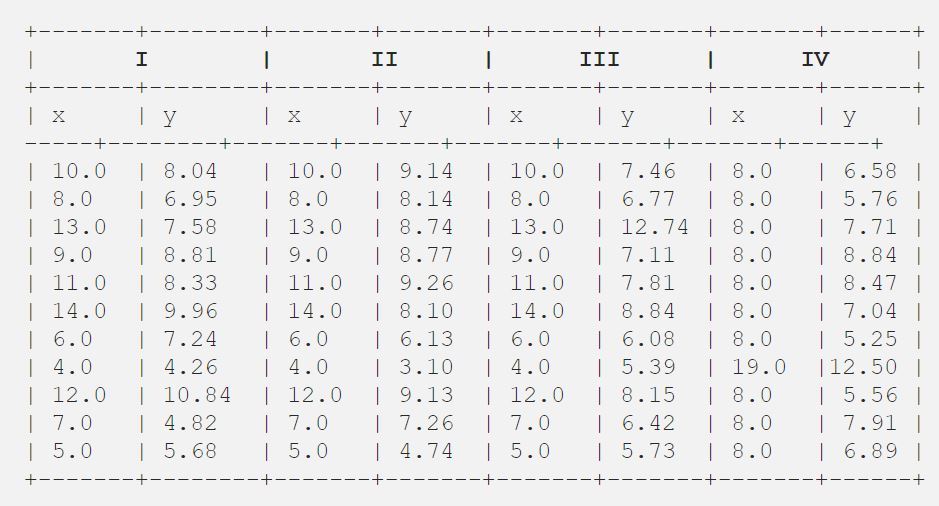
Após isso, o conselho os analisou utilizando apenas a estatística descritiva e encontrou a média, desvio padrão e correlação entre x e y.
Por favor, baixe o arquivo csv aqui.
Código: Programa Python para encontrar a média, o desvio padrão, e a correlação entre x e y
import pandas as pd import statistics from scipy.stats import pearsonr df = pd.read_csv("anscombe.csv") list1 = df list2 = df print('%.1f' % statistics.mean(list1)) print('%.2f' % statistics.stdev(list1)) print('%.1f' % statistics.mean(list2)) print('%.2f' % statistics.stdev(list2)) corr, _ = pearsonr(list1, list2) print('%.3f' % corr) Saída:
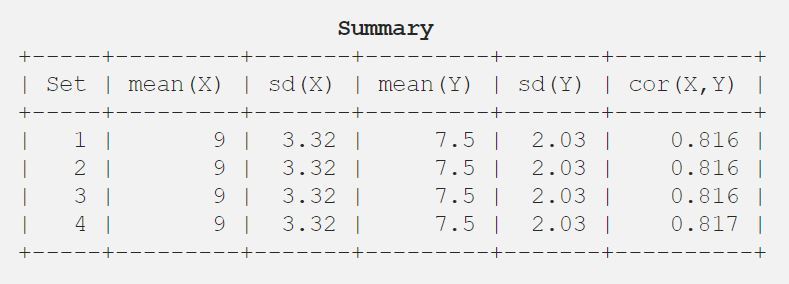
9.03.327.52.030.816
Então deixe-me mostrar-lhe o resultado de uma forma tabular para melhor compreensão.
Code: Programa Python para plotar gráfico de dispersão
from matplotlib import pyplot as plt import pandas as pd df = pd.read_csv("anscombe.csv") list1 = df list2 = df plt.scatter(list1, list2) plt.show() Para a linha de regressão consulte isto.
Output:
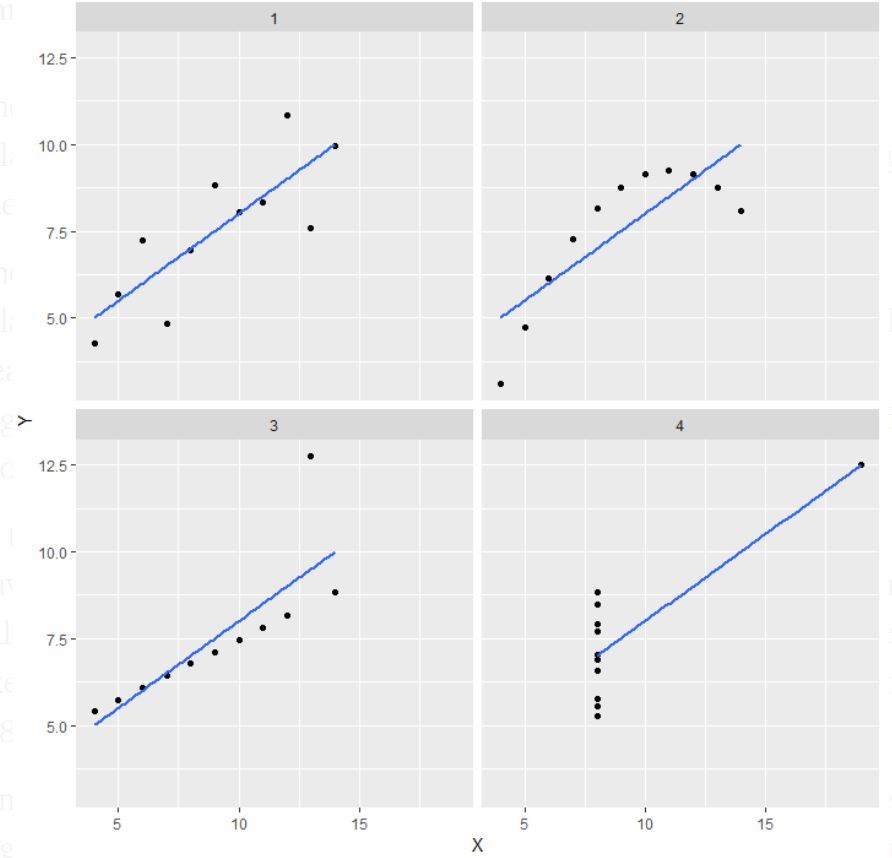
Note: É mencionado na definição que o quarteto de Anscombe é composto por quatro conjuntos de dados que têm propriedades estatísticas simples e quase idênticas, mas que parecem muito diferentes quando agarrados.
Explicação desta saída:
- No primeiro(superior esquerdo) se olhar para o gráfico de dispersão verá que parece existir uma relação linear entre x e y.
- No segundo(superior direito) se olhar para esta figura pode concluir que existe uma relação não linear entre x e y.
- No terceiro(inferior esquerdo) pode dizer quando existe uma relação linear perfeita para todos os pontos de dados excepto um que parece ser um outlier que está indicado estar muito longe dessa linha.
- Finalmente, o quarto(inferior direito) mostra um exemplo quando um ponto de alta média é suficiente para produzir um alto coeficiente de correlação.
Aplicação:
O quarteto ainda é usado com frequência para ilustrar a importância de olhar graficamente para um conjunto de dados antes de começar a analisar de acordo com um tipo particular de relação, e a inadequação das propriedades estatísticas básicas para descrever conjuntos de dados realistas.