I det här kapitlet kommer vi att diskutera cache-koherensprotokoll för att hantera problem med inkonsekvenser i multicache.
Cache Coherence Problem
I ett multiprocessorsystem kan datainkonsistens uppstå mellan angränsande nivåer eller inom samma nivå i minneshierarkin. Till exempel kan cacheminnet och huvudminnet ha inkonsekventa kopior av samma objekt.
Då flera processorer arbetar parallellt, och oberoende av varandra flera cacheminnen kan ha olika kopior av samma minnesblock, skapar detta problem med cachekoherens. Cachekoherenssystem hjälper till att undvika detta problem genom att upprätthålla ett enhetligt tillstånd för varje cacheblock av data.
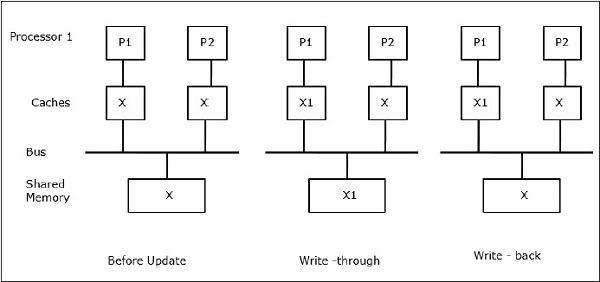
Låt X vara ett element av delade data som har refererats av två processorer, P1 och P2. I början är tre kopior av X konsekventa. Om processorn P1 skriver in en ny data X1 i cacheminnet med hjälp av skrivpolicyn kommer samma kopia att skrivas in omedelbart i det delade minnet. I detta fall uppstår inkonsekvens mellan cacheminnet och huvudminnet. När en policy för återskrivning används kommer huvudminnet att uppdateras när de ändrade uppgifterna i cacheminnet ersätts eller ogiltigförklaras.
I allmänhet finns det tre källor till inkonsekvensproblem –
- Delning av skrivbara data
- Processmigrering
- I/O-aktivitet
Snoopy Bus Protocols
Snoopy-protokoll uppnår datakonsistens mellan cacheminnet och det delade minnet genom ett bussbaserat minnessystem. Skrivinvalidering och skrivuppdatering används för att upprätthålla cachekonsistens.
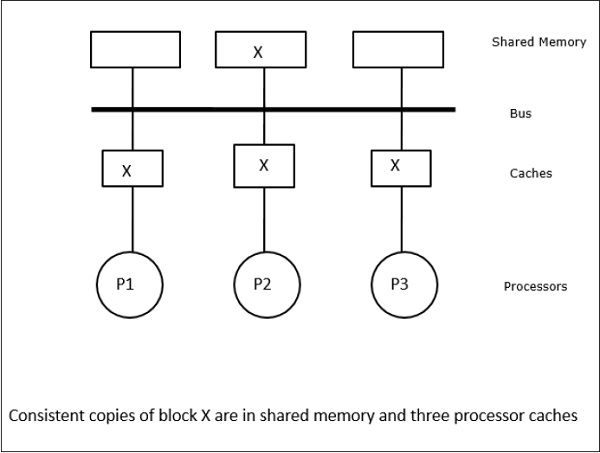
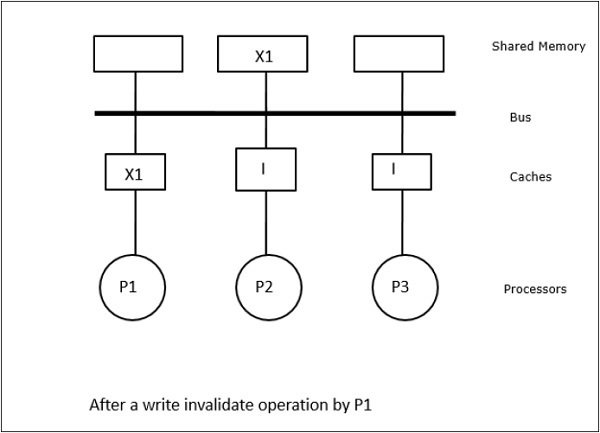
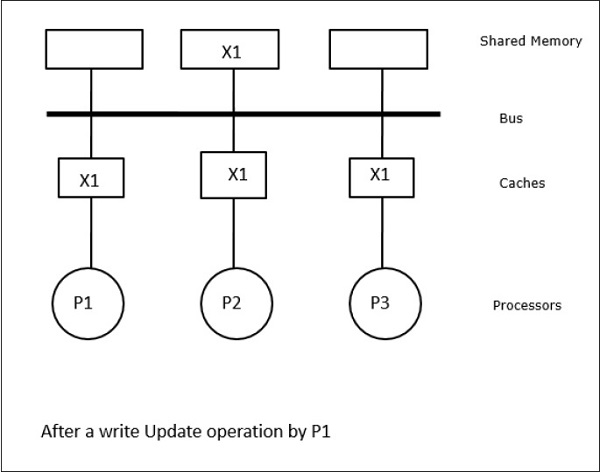
I det här fallet har vi tre processorer P1, P2 och P3 som har en konsistent kopia av dataelementet ”X” i sitt lokala cacheminne och i det delade minnet (figur-a). Processor P1 skriver X1 i sitt cacheminne med hjälp av protokollet write-invalidate. Alla andra kopior ogiltigförklaras alltså via bussen. Den betecknas med ”I” (figur b). Invaliderade block kallas också för smutsiga, dvs. de bör inte användas. Protokollet write-update uppdaterar alla cachekopior via bussen. Genom att använda write back cache uppdateras även minneskopian (figur-c).
Cache Events and Actions
Följande händelser och åtgärder inträffar vid utförandet av kommandon för minnesåtkomst och invalidering –
-
Read-miss – När en processor vill läsa ett block och det inte finns i cacheminnet, inträffar en read-miss. Detta initierar en bussläsningsoperation. Om det inte finns någon smutsig kopia, levererar huvudminnet, som har en konsekvent kopia, en kopia till det begärande cacheminnet. Om det finns en smutsig kopia i ett avlägset cacheminne kommer det cacheminnet att hålla tillbaka huvudminnet och skicka en kopia till det begärande cacheminnet. I båda fallen kommer cachekopian att gå in i det giltiga tillståndet efter en missad läsning.
-
Write-hit – Om kopian är i smutsigt eller reserverat tillstånd, skrivs det lokalt och det nya tillståndet är smutsigt. Om det nya tillståndet är giltigt sänds kommandot write-invalidate till alla cacheminnen och deras kopior blir ogiltiga. När det delade minnet skrivs igenom är det resulterande tillståndet reserverat efter denna första skrivning.
-
Write-miss – Om en processor misslyckas med att skriva i det lokala cacheminnet måste kopian komma antingen från huvudminnet eller från ett fjärrcacheminne med ett smutsigt block. Detta görs genom att skicka ett read-invalidate-kommando som ogiltigförklarar alla cachekopior. Därefter uppdateras den lokala kopian med smutsigt tillstånd.
-
Read-hit – Read-hit utförs alltid i det lokala cacheminnet utan att orsaka en tillståndsövergång eller använda snoopy-bussen för invalidering.
-
Blockersättning – När en kopia är smutsig ska den skrivas tillbaka till huvudminnet med blockersättningsmetoden. När kopian är antingen i giltigt, reserverat eller ogiltigt tillstånd sker dock ingen ersättning.
Adressbaserade protokoll
Vid användning av ett flerstegsnätverk för att bygga en stor multiprocessor med hundratals processorer måste snoopy-cacheprotokollen ändras för att passa nätverkets kapacitet. Eftersom Broadcasting är mycket dyrt att utföra i ett flerstegsnätverk skickas konsistenskommandona endast till de cacheminnen som har en kopia av blocket. Detta är anledningen till utvecklingen av katalogbaserade protokoll för nätverksanslutna multiprocessorer.
I ett katalogbaserat protokollsystem placeras data som skall delas i en gemensam katalog som upprätthåller samstämmigheten mellan cacheminnena. Här fungerar katalogen som ett filter där processorerna ber om tillstånd att ladda en post från primärminnet till sitt cacheminne. Om en post ändras uppdaterar katalogen antingen den eller ogiltigförklarar de andra cacheminnena med den posten.
Hårdvarusynkroniseringsmekanismer
Synkronisering är en speciell form av kommunikation där information istället för datakontroll utbyts mellan kommunicerande processer som befinner sig i samma eller olika processorer.
Multiprocessorsystem använder sig av hårdvarumekanismer för att genomföra synkroniseringsoperationer på låg nivå. De flesta multiprocessorer har hårdvarumekanismer för att införa atomära operationer, t.ex. läsning, skrivning eller läsning, ändring och skrivning av minnet, för att genomföra vissa synkroniseringsprimitiver. Förutom atomära minnesoperationer används även vissa avbrott mellan processorer för synkroniseringsändamål.
Cachekoherens i maskiner med delat minne
Hållandet av cachekoherens är ett problem i multiprocessorsystem när processorerna innehåller lokalt cacheminne. Datainkonsistens mellan olika cacheminnen uppstår lätt i detta system.
De viktigaste problemområdena är –
- Delning av skrivbara data
- Processmigrering
- I/O-aktivitet
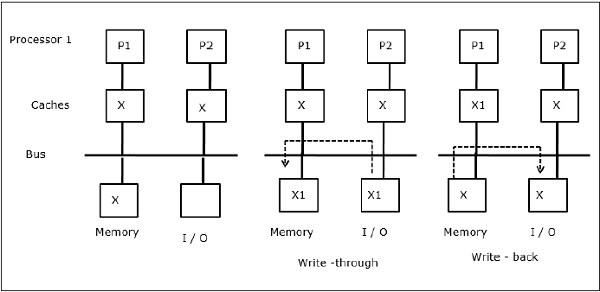
Delning av skrivbara data
När två processorer (P1 och P2) har samma dataelement (X) i sina lokala cache-minnen och en process (P1) skriver till dataelementet (X), Eftersom cacheminnena skrivs genom P1:s lokala cache, uppdateras även huvudminnet. När P2 nu försöker läsa dataelementet (X) hittar den inte X eftersom dataelementet i P2:s cache har blivit inaktuellt.
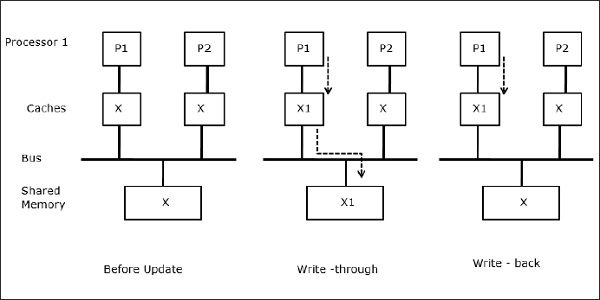
Processmigrering
I det första steget har P1:s cache dataelementet X, medan P2 inte har något. En process på P2 skriver först på X och flyttar sedan till P1. Nu börjar processen läsa dataelement X, men eftersom processorn P1 har föråldrade data kan processen inte läsa dem. Så en process på P1 skriver till dataelementet X och flyttar sedan till P2. Efter migreringen börjar en process på P2 läsa dataelementet X, men den hittar en föråldrad version av X i huvudminnet.
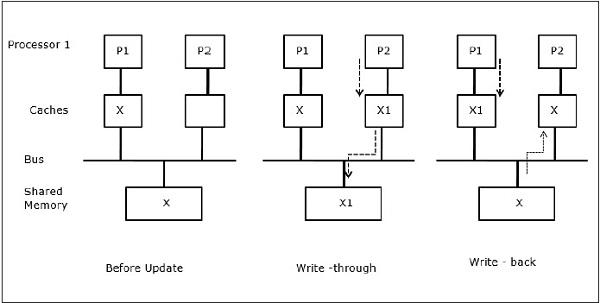
I/O-aktivitet
Som illustreras i figuren läggs en I/O-enhet till bussen i en flerprocessorarkitektur med två processorer. I början innehåller båda cacheminnena dataelementet X. När I/O-enheten tar emot ett nytt element X lagrar den det nya elementet direkt i huvudminnet. När nu antingen P1 eller P2 (anta att P1) försöker läsa element X får den en föråldrad kopia. Så P1 skriver till element X. Om I/O-enheten nu försöker överföra X får den en föråldrad kopia.
Uniform Memory Access (UMA)
En arkitektur med enhetlig minnesåtkomst (UMA) innebär att det delade minnet är detsamma för alla processorer i systemet. Populära klasser av UMA-maskiner, som vanligen används för (fil-) servrar, är de så kallade symmetriska multiprocessorerna (SMP). I en SMP är alla systemresurser som minne, diskar, andra I/O-enheter etc. tillgängliga för processorerna på ett enhetligt sätt.
Non-Uniform Memory Access (NUMA)
I NUMA-arkitekturen finns det flera SMP-kluster som har ett internt indirekt/delat nätverk, som är anslutna i ett skalbart nätverk för meddelandeöverföring. NUMA-arkitekturen är alltså en logiskt delad, fysiskt distribuerad minnesarkitektur.
I en NUMA-maskin avgör processorns cachekontroller om en minnesreferens är lokal i SMP:s minne eller om den är avlägsen. För att minska antalet fjärrminnesåtkomster tillämpar NUMA-arkitekturer vanligen cachingprocessorer som kan cacha fjärrdata. Men när cacheminnen är inblandade måste cachekoherensen upprätthållas. Därför kallas dessa system också för CC-NUMA (Cache Coherent NUMA).
Cache Only Memory Architecture (COMA)
COMA-maskiner liknar NUMA-maskiner, med den enda skillnaden att COMA-maskinernas huvudminnen fungerar som direktmappade eller set-associativa cacheminnen. Datablocken hashas till en plats i DRAM-cachen i enlighet med deras adresser. Data som hämtas på distans lagras faktiskt i det lokala huvudminnet. Dessutom har datablock inte någon fast hemort, utan kan röra sig fritt i hela systemet.
COMA-arkitekturer har för det mesta ett hierarkiskt meddelandeöverföringsnätverk. En växel i ett sådant träd innehåller en katalog med dataelement som sitt underträd. Eftersom data inte har någon hemort måste de sökas explicit. Detta innebär att en fjärråtkomst kräver en genomgång längs växlarna i trädet för att söka i deras kataloger efter de nödvändiga uppgifterna. Om en växel i nätverket får flera förfrågningar från sitt underträd om samma data, kombinerar den dem till en enda förfrågan som skickas till växelns överordnade. När de begärda uppgifterna återkommer skickar växeln flera kopior av dem ner i sitt underträd.
COMA kontra CC-NUMA
Nedan följer skillnaderna mellan COMA och CC-NUMA.
-
COMA tenderar att vara mer flexibelt än CC-NUMA eftersom COMA på ett transparent sätt stöder migrering och replikering av uppgifter utan att operativsystemet behöver användas.
-
COMA-maskiner är dyra och komplexa att bygga eftersom de behöver icke-standardiserad minneshanteringshårdvara och koherensprotokollet är svårare att genomföra.
-
Fjärrååtkomster i COMA är ofta långsammare än i CC-NUMA eftersom trädnätverket måste genomkorsas för att hitta data.
.