Enligt Wikipedias definition består Anscombes kvartett av fyra datamängder som har nästan identiska enkla statistiska egenskaper, men som ser väldigt olika ut när de visas i diagram. Varje dataset består av elva (x,y) punkter. De konstruerades 1973 av statistikern Francis Anscombe för att visa både vikten av att grafera data innan man analyserar dem och effekten av outliers på statistiska egenskaper.
Enklare förståelse:
En gång fann Francis John ”Frank” Anscombe, som var en välrenommerad statistiker, fyra uppsättningar av elva datapunkter i sin dröm och bad rådet som sin sista önskan att rita dessa punkter. Dessa 4 uppsättningar av 11 datapunkter finns nedan.
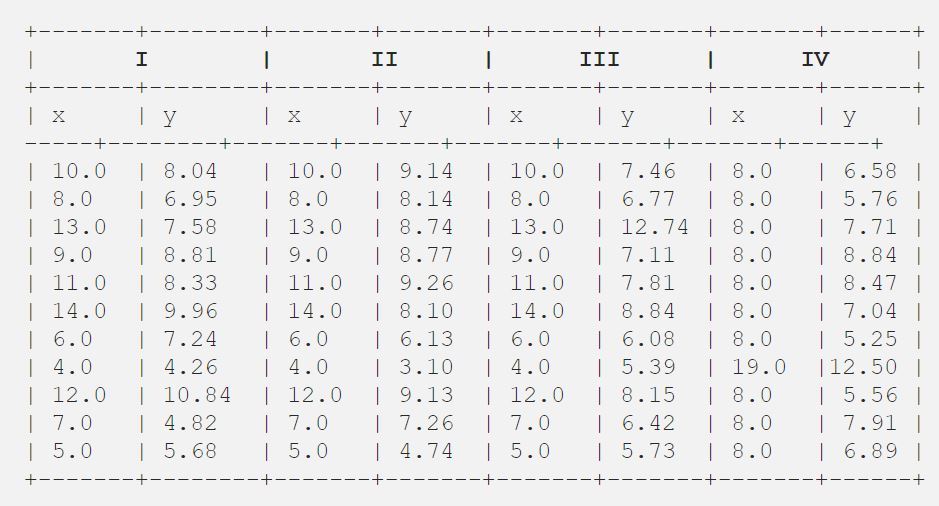
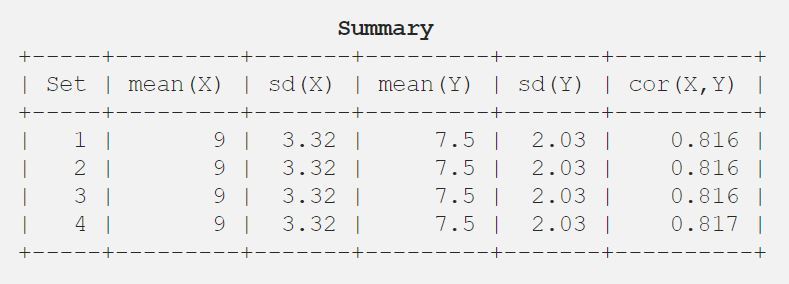
Därefter analyserade rådet dem med hjälp av enbart deskriptiv statistik och fann medelvärde, standardavvikelse och korrelation mellan x och y.
Du kan ladda ner csv-filen här.
Kod: Pythonprogram för att hitta medelvärde, standardavvikelse, och korrelationen mellan x och y
import pandas as pd import statistics from scipy.stats import pearsonr df = pd.read_csv("anscombe.csv") list1 = df list2 = df print('%.1f' % statistics.mean(list1)) print('%.2f' % statistics.stdev(list1)) print('%.1f' % statistics.mean(list2)) print('%.2f' % statistics.stdev(list2)) corr, _ = pearsonr(list1, list2) print('%.3f' % corr) Output:
9.03.327.52.030.816
För en bättre förståelse vill jag visa resultatet i en tabell.
Code: Pythonprogram för att plotta spridningsdiagram
from matplotlib import pyplot as plt import pandas as pd df = pd.read_csv("anscombe.csv") list1 = df list2 = df plt.scatter(list1, list2) plt.show() För regressionslinje hänvisas till detta.
Output:
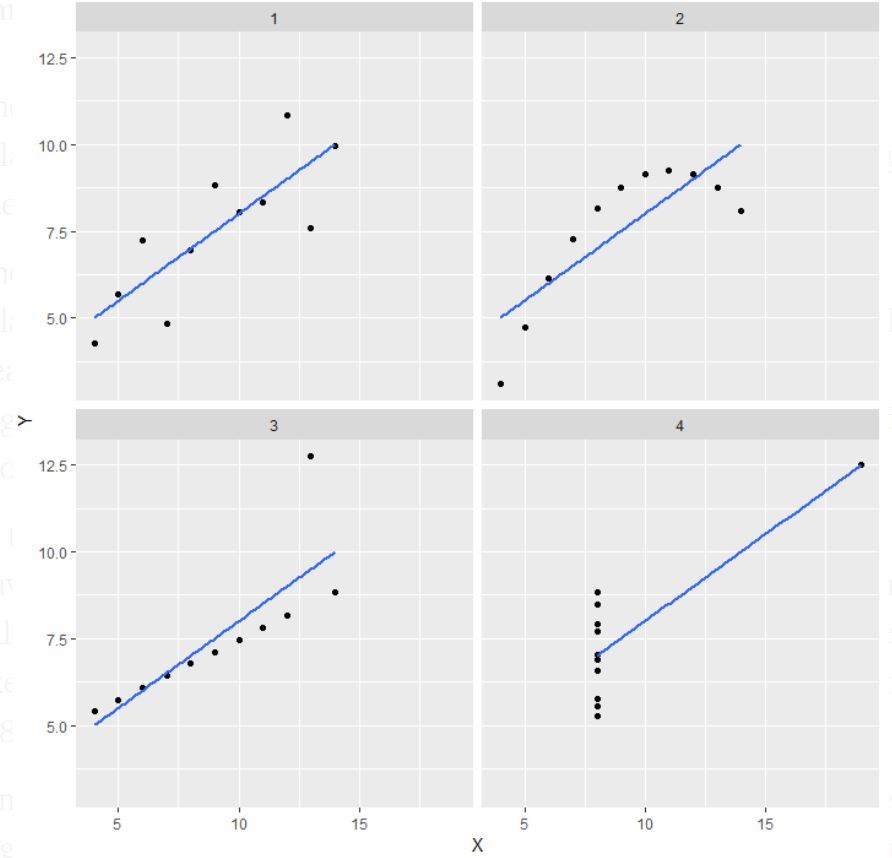
Note: Det nämns i definitionen att Anscombes kvartett omfattar fyra dataset som har nästan identiska enkla statistiska egenskaper, men som ändå ser mycket olika ut när de grafiskt visas.
Förklaring av detta resultat:
- I den första (uppe till vänster) om du tittar på spridningsdiagrammet ser du att det verkar finnas ett linjärt samband mellan x och y.
- I den andra (uppe till höger) om du tittar på den här figuren kan du dra slutsatsen att det finns ett icke-linjärt samband mellan x och y.
- I den tredje figuren (längst ner till vänster) kan man säga att det finns ett perfekt linjärt samband för alla datapunkter utom en som verkar vara en outlier och som anges vara långt ifrån den linjen.
- Slutligt visar den fjärde (längst ner till höger) ett exempel på när en punkt med hög hävstångseffekt räcker för att ge en hög korrelationskoefficient.
Användning:
Kvartetten används fortfarande ofta för att illustrera vikten av att titta på en uppsättning data grafiskt innan man börjar analysera enligt en viss typ av relation, samt att grundläggande statistiska egenskaper inte räcker till för att beskriva realistiska datamängder.