När man skriver enkelsidiga applikationer är det lätt och naturligt att fastna i att försöka skapa den ideala upplevelsen för den vanligaste typen av användare – andra människor som vi själva. Detta aggressiva fokus på en typ av besökare på vår webbplats kan ofta lämna en annan viktig grupp i sticket – de crawlers och botar som används av sökmotorer som Google. Den här guiden kommer att visa hur några lättimplementerade bästa metoder och en övergång till server-side rendering kan ge din applikation det bästa av två världar när det gäller SPA-användarupplevelse och SEO.
Förutsättningar
En fungerande kunskap om Angular 5+ förutsätts. Vissa delar av guiden behandlar Angular 6 men kunskap om det är inte ett strikt krav.
En stor del av de oavsiktliga SEO-misstag vi gör kommer från tankesättet att vi bygger webbapplikationer och inte webbplatser. Vad är skillnaden? Det är en subjektiv distinktion, men jag skulle säga utifrån en fokusering av ansträngningarna:
- Webbapplikationer fokuserar på naturliga och intuitiva interaktioner för användarna
- Webbsidor fokuserar på att göra information allmänt tillgänglig
Men dessa två koncept behöver inte utesluta varandra! Genom att helt enkelt återgå till de ursprungliga reglerna för utveckling av webbplatser kan vi bibehålla SPA:s eleganta utseende och känsla och placera information på rätt ställen för att skapa en idealisk webbplats för crawlers.
Dölj inte innehåll bakom interaktioner
En princip som man bör tänka på när man utformar komponenter är att crawlers är ganska dumma. De kommer att klicka på dina ankare, men de kommer inte att slumpmässigt svepa över element eller klicka på en div bara för att det står ”Läs mer” på innehållet. Detta är inte helt oväntat i Angular, där en vanlig metod för att dölja information är att ”*ngif it out”. Och många gånger är detta vettigt! Vi använder denna praxis för att förbättra applikationsprestanda genom att inte ha potentiellt tunga komponenter som bara sitter i en icke synlig del av sidan.
Det betyder dock att om du döljer innehåll på din sida genom smarta interaktioner är chansen stor att en crawler aldrig kommer att se det innehållet. Du kan mildra detta genom att helt enkelt använda CSS i stället för *ngif för att dölja den här typen av innehåll. Naturligtvis kommer smarta crawlers att märka att texten är dold och den kommer sannolikt att viktas som mindre viktig än synlig text. Men detta är ett bättre resultat än att texten inte alls är tillgänglig i DOM. Ett exempel på detta tillvägagångssätt ser ut så här:
Skapa inte ”virtuella ankare”
Komponenten nedan visar ett anti-mönster som jag ser mycket i Angular-applikationer och som jag kallar för ett ”virtuellt ankare”:
Det som händer är att en klickhanterare är kopplad till något som en <knapp> eller <div>-tagg, och den hanteraren utför en viss logik och använder sedan den importerade Angular Router för att navigera till en annan sida. Detta är problematiskt av två skäl:
- Crawlers kommer troligen inte att klicka på den här typen av element, och även om de gör det kommer de inte att upprätta en länk mellan käll- och målsidan.
- Detta förhindrar den mycket bekväma ”Öppna i ny flik”-funktionen som webbläsare tillhandahåller nativt för faktiska ankartaggar.
Istället för att använda virtuella ankare kan du använda en riktig <a>-tagg med routerlinkdirektivet. Om du behöver utföra extra logik innan du navigerar kan du fortfarande lägga till en klickhanterare till ankartaggen.
Glöm inte bort rubriker
En av principerna för god SEO är att fastställa den relativa betydelsen av olika texter på en sida. Ett viktigt verktyg för detta i webbutvecklarens kit är rubriker. Det är vanligt att man helt glömmer bort rubriker när man utformar komponenthierarkin i en Angular-applikation; om de finns med eller inte gör ingen visuell skillnad i slutprodukten. Men detta är något du måste tänka på för att se till att crawlers fokuserar på rätt delar av din information. Så överväg att använda rubriktaggar där det är meningsfullt. Se dock till att komponenter som innehåller rubriktaggar inte kan arrangeras på ett sådant sätt att en <h1> visas inuti en <h2>.
Gör ”Sökresultatssidor” länkbara
För att återgå till principen om hur crawlers är dumma – tänk på en söksida för ett företag som tillverkar widgetar. En crawler kommer inte att se en textinmatning på ett formulär och skriva in något som ”Toronto widgets”. För att göra sökresultat tillgängliga för crawlers måste följande göras:
- En söksida måste inrättas som accepterar sökparametrar genom sökvägen och/eller sökfrågan.
- Länkar till specifika sökningar som du tror att crawlern kan finna intressanta måste läggas till i webbplatskartan eller som ankarlänkar på andra sidor på webbplatsen.
Strategin kring punkt 2 ligger utanför den här artikelns räckvidd (Några användbara resurser är https://yoast.com/internal-linking-for-seo-why-and-how/ och https://moz.com/learn/seo/internal-link). Det viktiga är att sökkomponenter och sidor bör utformas med punkt #1 i åtanke så att du har flexibiliteten att skapa en länk till vilken typ av sökning som helst, så att den kan injiceras var du vill. Detta innebär att du importerar ActivatedRoute och reagerar på dess ändringar i sökväg och frågeparametrar för att styra sökresultaten på din sida, i stället för att enbart förlita dig på dina fråge- och filtreringskomponenter på sidan.
Gör paginering länkbar
När vi ändå är inne på ämnet söksidor är det viktigt att se till att paginering hanteras på rätt sätt, så att crawlers kan få tillgång till varje enskild sida av dina sökresultat om de så önskar. Det finns ett par bästa metoder som du kan följa för att säkerställa detta.
För att upprepa tidigare punkter: använd inte ”virtuella ankare” för dina länkar för ”nästa”, ”föregående” och ”sidnummer”. Om en crawler inte kan se dessa som ankare, kanske den aldrig tittar på något efter din första sida. Använd riktiga <a>-taggar med RouterLink för dessa. Inkludera även paginering som en valfri del av dina länkbara sök-URL:er – detta sker ofta i form av en page=-frågeparameter.
Du kan ge ytterligare ledtrådar till crawlers om paginering av din webbplats genom att lägga till relativa ”prev”/”next” <link>-taggar. En förklaring till varför dessa kan vara användbara finns på följande webbplats: https://webmasters.googleblog.com/2011/09/pagination-with-relnext-and-relprev.html. Här är ett exempel på en tjänst som automatiskt kan hantera dessa <link>-taggar på ett Angular-vänligt sätt:
Inkludera dynamisk metadata
En av de första sakerna vi gör i en ny Angular-applikation är att göra justeringar i indexet.html-filen – vi ställer in favicon, lägger till responsiva metataggar och ställer sannolikt in innehållet i <title> och <meta name=”description”>-taggarna till några förnuftiga standardvärden för din applikation. Men om du bryr dig om hur dina sidor visas i sökresultaten kan du inte stanna där. På varje rutt för ditt program bör du dynamiskt ställa in taggarna title och description så att de matchar sidans innehåll. Detta kommer inte bara att hjälpa crawlers, utan även användarna eftersom de kommer att kunna se informativa titlar för webbläsarflikar, bokmärken och förhandsgranskningsinformation när de delar en länk på sociala medier. Snippet nedan visar hur du kan uppdatera dessa på ett Angular-vänligt sätt med hjälp av klasserna Meta och Title:
Test för crawlers som bryter din kod
Vissa tredjepartsbibliotek eller SDK:er stängs antingen ner eller kan inte laddas från sin webbhotell när användaragenter som tillhör sökmotorkräftor upptäcks. Om någon del av din funktionalitet är beroende av dessa beroenden bör du tillhandahålla en fallback för beroenden som inte tillåter crawlers. Åtminstone bör ditt program försämras på ett elegant sätt i dessa fall, i stället för att krascha klientens renderingsprocess. Ett bra verktyg för att testa kodens interaktion med crawlers är Google Mobile Friendly-testsidan: https://search.google.com/test/mobile-friendly. Håll utkik efter utdata som detta som innebär att en crawler blockeras för tillgång till en SDK:

Reduktion av buntstorlek med Angular 6
Bundelstorlek i Angular-tillämpningar är ett välkänt problem, men det finns många optimeringar som en utvecklare kan göra för att mildra det, bland annat genom att använda AOT-builds och vara konservativ när det gäller att inkludera bibliotek från tredje part. För att få så små Angular-bundlar som möjligt idag krävs dock att man uppgraderar till Angular 6. Anledningen till detta är den nödvändiga parallella uppgraderingen till RXJS 6, som erbjuder betydande förbättringar av dess förmåga att skaka träd. För att faktiskt få denna förbättring finns det några hårda krav för din applikation:
- För att ta bort biblioteket rxjs-compat (som läggs till som standard i uppgraderingsprocessen för Angular 6) – detta bibliotek gör din kod bakåtkompatibel med RXJS 5 men motverkar förbättringarna av trädskakningen.
- Säkerställ att alla beroenden hänvisar till Angular 6 och inte använder biblioteket rxjs-compat.
- Importera RXJS-operatörer en i taget i stället för i grossistledet för att säkerställa att tree shaking kan göra sitt jobb. Se https://github.com/ReactiveX/rxjs/blob/master/docs_app/content/guide/v6/migration.md för en fullständig guide om migrering.
Server Rendering
Även efter att ha följt alla de föregående bästa metoderna kan det hända att din Angular-webbplats inte rankas så högt som du skulle vilja. En möjlig orsak till detta är en av de grundläggande bristerna med SPA-ramverk i SEO-sammanhang – de förlitar sig på Javascript för att rendera sidan. Det här problemet kan visa sig på två sätt:
- Och Googlebot kan utföra Javascript, men inte alla crawler gör det. För dem som inte gör det kommer alla dina sidor att se i princip tomma ut för dem.
- För att en sida ska visa användbart innehåll måste crawlern vänta på att Javascriptpaket laddas ner, att motorn analyserar dem, att koden körs och att eventuella externa XHR:er returneras – sedan kommer det att finnas innehåll i DOM. Jämfört med mer traditionella serverrenderade språk där information finns tillgänglig i DOM så snart dokumentet når webbläsaren, kommer en SPA sannolikt att straffas något här.
Troligtvis har Angular en lösning på det här problemet som gör det möjligt att servera ett program i en serverrenderad form: Angular Universal (https://github.com/angular/universal). En typisk implementering som använder den här lösningen ser ut så här:
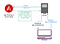
- En klient gör en förfrågan om en viss webbadress till din applikationsserver.
- Servern proxyar förfrågan till en renderingstjänst, som är din Angular-applikation som körs i en Node.js container. Denna tjänst kan (men behöver inte nödvändigtvis) finnas på samma maskin som programservern.
- Serverversionen av programmet render fullständig HTML och CSS för sökvägen och den begärda frågan, inklusive <script>-taggar för att ladda ner klientens Angular-applikation.
- Browsern tar emot sidan och kan visa innehållet omedelbart. Klientapplikationen laddas asynkront och när den är klar återskapar den den aktuella sidan och ersätter den statiska HTML som servern återgav. Nu beter sig webbplatsen som en SPA för all interaktion framöver. Denna process bör vara sömlös för en användare som surfar på webbplatsen.
Denna magi är dock inte gratis. Ett par gånger i den här guiden har jag nämnt hur man gör saker på ett ”Angular-vänligt” sätt. Vad jag egentligen menade var ”Angular server-rendering-vänlig”. Alla de bästa metoderna som du läser om Angular, som att inte röra DOM direkt eller begränsa användningen av setTimeout, kommer att komma tillbaka för att bita dig om du inte har följt dem – i form av långsam laddning eller till och med helt trasiga sidor. En omfattande lista över de universella ”gotchas” finns på följande webbplats: https://github.com/angular/universal/blob/master/docs/gotchas.md
Hello Server
Det finns ett par olika alternativ för att få igång ett projekt med Universal:
- För Angular 5-projekt kan du köra följande kommando i ett befintligt projekt:
ng generate universal server - För Angular 6-projekt finns det ännu inte något officiellt CLI-kommando för att skapa ett fungerande Universal-projekt med en klient och server. Du kan köra följande tredjepartskommando i ett befintligt projekt:
ng add @ng-toolkit/universal - Du kan också klona detta arkiv för att använda det som utgångspunkt för ditt projekt eller för att slå ihop det med ett befintligt projekt: https://github.com/angular/universal-starter
Dependency injection is your (server’s) friend
I en typisk Angular Universal-uppsättning kommer du att ha tre olika programmoduler – en modul endast för webbläsare, en modul endast för server och en delad modul. Vi kan använda detta till vår fördel genom att skapa abstrakta tjänster som våra komponenter injicerar och tillhandahålla klient- och serverspecifika implementationer i varje modul. Ta det här exemplet på en tjänst som kan sätta fokus på ett element: vi definierar en abstrakt tjänst, klient- och serverimplementationer, tillhandahåller dem i sina respektive moduler och importerar den abstrakta tjänsten i komponenterna.
Rättande av serverfientliga beroenden
Alla tredjepartskomponenter som inte följer Angulars bästa praxis (dvs. använder document eller window) kommer att krascha serverrenderingen av alla sidor som använder den komponenten. Det bästa alternativet är att hitta ett Universal-kompatibelt alternativ till biblioteket. Ibland är detta inte möjligt, eller så förhindrar tidsbrist att byta ut beroendet. I dessa fall finns det två huvudalternativ för att förhindra att biblioteket stör.
Du kan *ngIf ut felande komponenter på servern. Ett enkelt sätt att göra detta är att skapa ett direktiv som kan avgöra om ett element ska renderas beroende på den aktuella plattformen:
Vissa bibliotek är mer problematiska; själva importen av koden kan mycket väl försöka använda beroenden som endast finns i webbläsaren och som kommer att krascha serverrenderingen. Ett exempel är alla bibliotek som importerar jquery som ett npm-beroende, i stället för att förvänta sig att konsumenten har jquery tillgängligt i global räckvidd. För att se till att dessa bibliotek inte bryter ner servern måste vi både *ngIf-utföra den felande komponenten och ta bort det beroende biblioteket från webpack. Om vi antar att biblioteket som importerar jquery heter ”jquery-funpicker” kan vi skriva en webpack-regel som den nedan för att ta bort det från serverbygget:
Detta kräver också att du placerar en fil med innehållet {} på webpack/empty.json i din projektstruktur. Resultatet blir att biblioteket får en tom implementering för importförklaringen ”jquery-funpicker”, men det spelar ingen roll eftersom vi har tagit bort den komponenten överallt i serverapplikationen med vårt nya direktiv.
Förbättra webbläsarens prestanda – upprepa inte dina XHRs
En del av utformningen av Universal är att klientversionen av applikationen kommer att köra om all logik som kördes på servern för att skapa klientvyn – inklusive att göra samma XHR-anrop till din backend som serverns rendering redan gjort! Detta skapar en extra belastning på din backend och ger en känsla för crawlers att sidan fortfarande laddar innehåll, även om den troligen kommer att visa samma information efter att XHR-avdragen har återvänt. Om det inte finns någon oro för att data inte kan lagras bör du förhindra att klientprogrammet duplicerar XHR:er som servern redan har gjort. TransferHttpCacheModulen från Angular är en praktisk modul som kan hjälpa till med detta: https://github.com/angular/universal/blob/master/docs/transfer-http.md
Under huven använder TransferHttpCacheModule klassen TransferState som kan användas för all slags tillståndsöverföring för allmänna ändamål från server till klient:
Pre render to move time-to-first-byte against zero
En sak att tänka på när man använder Universal (eller till och med en tredjepartsrenderingstjänst som https://prerender.io/) är att en serverrenderad sida kommer att ha längre tid innan den första byten når webbläsaren än en klientrenderad sida. Detta borde vara logiskt när man betänker att för att en server skall kunna leverera en klientrenderad sida behöver den i princip bara leverera en statisk index.html-sida. Universal kommer inte att slutföra en rendering förrän programmet anses vara ”stabilt”. Stabilitet i samband med Angular är komplicerat, men de två största bidragen till fördröjningen av stabiliteten kommer sannolikt att vara:
- Outstanding XHRs
- Outstanding setTimeout calls
Om du inte har något sätt att optimera ovanstående ytterligare, är ett alternativ för att minska tiden till första byte helt enkelt genom att förrendera några eller alla sidor i din applikation och servera dem från en cache. Angular Universal starter repo som länkades tidigare i den här guiden innehåller en implementering för pre-rendering. När du väl har dina förrenderade sidor kan en cachinglösning, beroende på din arkitektur, vara något som Varnish, Redis, en CDN eller en kombination av olika tekniker. Genom att ta bort renderingstiden från svarsvägen från server till klient kan du ge extremt snabba första sidladdningar till crawlers och de mänskliga användarna av din applikation.
Slutsats
Många av teknikerna i den här artikeln är inte bara bra för crawlers i sökmotorer, utan skapar också en mer bekant webbplatsupplevelse för dina användare. Något så enkelt som att ha informativa tabbtitlar för olika sidor gör stor skillnad för en relativt låg implementeringskostnad. Genom att anamma server-side rendering kommer du inte att drabbas av oväntade produktionsluckor, till exempel när folk försöker dela din webbplats på sociala medier och får en tom miniatyrbild.
I takt med att webben utvecklas hoppas jag att vi kommer att få se en dag då crawlers och skärmbildsservrar interagerar med webbplatser på ett sätt som är mer i linje med hur användarna interagerar på sina enheter – och som skiljer webbapplikationer från de gamla webbplatserna som de tvingas emulera. Men för tillfället måste vi som utvecklare fortsätta att stödja den gamla världen.
