V této kapitole se budeme zabývat protokoly koherence mezipaměti, které se vyrovnávají s problémy nekonzistence více mezipamětí.
Problém koherence mezipaměti
Ve víceprocesorovém systému může dojít k nekonzistenci dat mezi sousedními úrovněmi nebo v rámci stejné úrovně paměťové hierarchie. Například mezipaměť a hlavní paměť mohou mít nekonzistentní kopie téhož objektu.
Jelikož více procesorů pracuje paralelně a nezávisle na sobě může mít více mezipamětí různé kopie téhož paměťového bloku, vzniká problém s koherencí mezipaměti. Schémata koherence mezipaměti pomáhají tomuto problému předcházet tím, že udržují jednotný stav pro každý blok dat v mezipaměti.
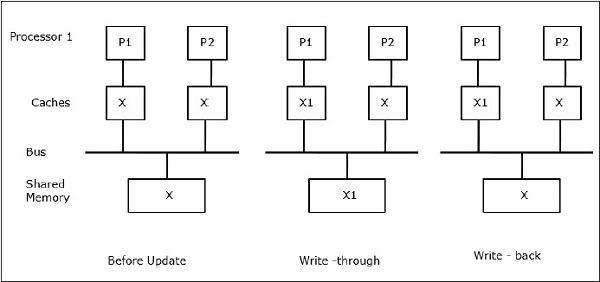
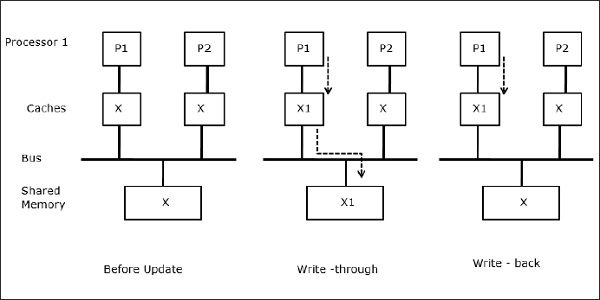
Nechť X je prvek sdílených dat, na který se odkazují dva procesory, P1 a P2. Na začátku jsou tři kopie X konzistentní. Pokud procesor P1 zapíše do mezipaměti nová data X1, bude při použití politiky průchozího zápisu stejná kopie okamžitě zapsána do sdílené paměti. V tomto případě vzniká nekonzistence mezi pamětí cache a hlavní pamětí. Při použití zásady zpětného zápisu se hlavní paměť aktualizuje, když jsou změněná data v cache nahrazena nebo zneplatněna.
Obecně existují tři zdroje problému nekonzistence –
- Sdílení zapisovatelných dat
- Migrace procesů
- I/O aktivity
Snoopy Bus protokoly
Snoopy protokoly dosahují konzistence dat mezi pamětí cache a sdílenou pamětí prostřednictvím sběrnicového paměťového systému. Pro udržení konzistence mezipaměti se používají zásady write-invalidate a write-update.
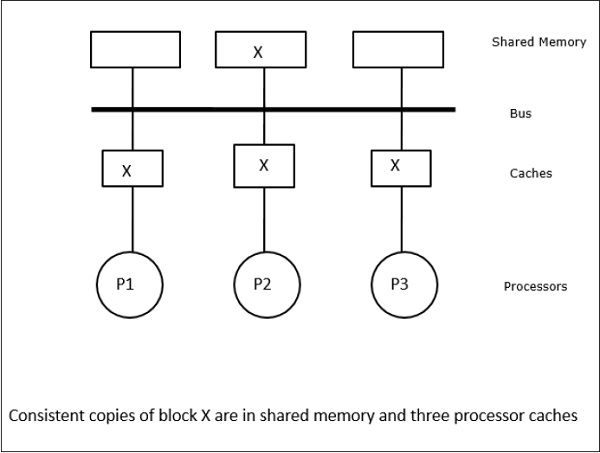
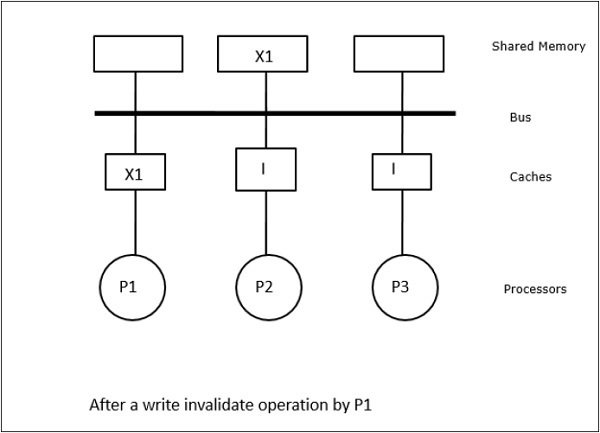
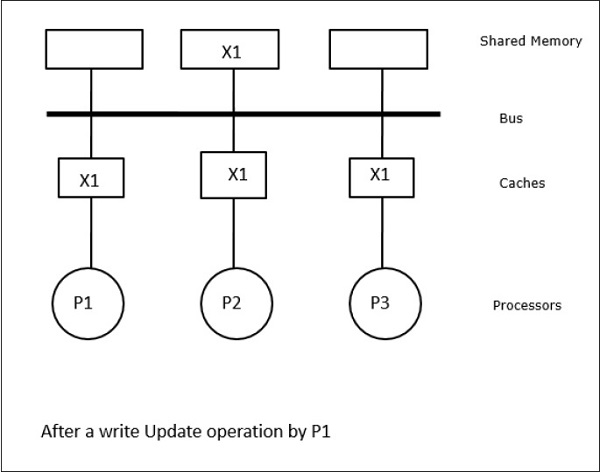
V tomto případě máme tři procesory P1, P2 a P3, které mají konzistentní kopii datového prvku „X“ ve své lokální paměti cache a ve sdílené paměti (obrázek-a). Procesor P1 zapíše X1 do své paměti cache pomocí protokolu write-invalidate. Všechny ostatní kopie jsou tedy zneplatněny prostřednictvím sběrnice. Označuje se „I“ (obrázek-b). Zneplatněné bloky se také označují jako špinavé, tj. neměly by se používat. Protokol write-update aktualizuje všechny kopie cache prostřednictvím sběrnice. Pomocí protokolu write back cache se aktualizuje i kopie paměti (obrázek-c).
Děje a akce ve vyrovnávací paměti
Při provádění příkazů pro přístup do paměti a zneplatnění dochází k následujícím událostem a akcím –
-
Read-miss – Když chce procesor přečíst blok a ten není ve vyrovnávací paměti, dojde k read-miss. Tím je iniciována operace čtení ze sběrnice. Pokud neexistuje žádná špinavá kopie, pak hlavní paměť, která má konzistentní kopii, dodá kopii do paměti cache, která o ni požádala. Pokud existuje špinavá kopie ve vzdálené paměti cache, tato paměť cache omezí hlavní paměť a pošle kopii do paměti cache žádající o kopii. V obou případech se kopie mezipaměti po chybě čtení dostane do platného stavu.
-
Zápis-hit – Pokud je kopie ve špinavém nebo rezervovaném stavu, provede se lokální zápis a nový stav je špinavý. Pokud je nový stav platný, je příkaz write-invalidate vyslán do všech cache a zneplatní jejich kopie. Při zápisu přes sdílenou paměť je výsledný stav po tomto prvním zápisu rezervován.
-
Write-miss – Pokud se procesoru nepodaří zapsat do lokální paměti cache, musí kopie pocházet buď z hlavní paměti, nebo ze vzdálené paměti cache se špinavým blokem. To se provede odesláním příkazu read-invalidate, který zneplatní všechny kopie cache. Pak se místní kopie aktualizuje se špinavým stavem.
-
Čtení-zásah – Čtení-zásah se vždy provádí v místní paměti cache, aniž by došlo k přechodu stavu nebo použití sběrnice snoopy pro zneplatnění.
-
Záměna bloku – Když je kopie špinavá, má se zapsat zpět do hlavní paměti metodou výměny bloku. Když je však kopie buď v platném, nebo rezervovaném či neplatném stavu, k výměně nedojde.
Protokoly založené na adresáři
Při použití vícestupňové sítě pro sestavení velkého multiprocesoru se stovkami procesorů je třeba upravit protokoly snoopy cache tak, aby vyhovovaly možnostem sítě. Protože vysílání je ve vícestupňové síti velmi nákladné, příkazy konzistence se posílají pouze do těch mezipamětí, které uchovávají kopii bloku. To je důvodem pro vývoj adresářových protokolů pro síťově propojené víceprocesory.
V systému adresářových protokolů jsou data, která mají být sdílena, umístěna do společného adresáře, který udržuje koherenci mezi cache. Adresář zde funguje jako filtr, kde procesory žádají o povolení načíst záznam z primární paměti do své paměti cache. Pokud je položka změněna, adresář ji buď aktualizuje, nebo zneplatní ostatní mezipaměti s touto položkou.
Hardwarové synchronizační mechanismy
Synchronizace je zvláštní forma komunikace, kdy se místo řízení dat vyměňují informace mezi komunikujícími procesy sídlícími ve stejných nebo různých procesorech.
Víceprocesorové systémy používají hardwarové mechanismy pro implementaci synchronizačních operací na nízké úrovni. Většina multiprocesorů má hardwarové mechanismy pro zavedení atomických operací, jako je čtení z paměti, zápis nebo operace čtení-změna-zápis, pro implementaci některých synchronizačních primitiv. Kromě atomických operací s pamětí se pro účely synchronizace používají také některá meziprocesorová přerušení.
Koherence mezipaměti ve strojích se sdílenou pamětí
Zachování koherence mezipaměti je ve víceprocesorovém systému problém, pokud procesory obsahují lokální paměť cache. V tomto systému snadno dochází k nekonzistenci dat mezi různými cache.
Hlavní problémové oblasti jsou –
- Sdílení zapisovatelných dat
- Migrace procesů
- I/O aktivity
Sdílení zapisovatelných dat
Když dva procesory (P1 a P2) mají ve svých lokálních cache stejný datový prvek (X) a jeden proces (P1) zapisuje do datového prvku (X), protože mezipaměti jsou zapisovací lokální mezipaměti P1, je aktualizována i hlavní paměť. Když se nyní P2 pokusí přečíst datový prvek (X), nenajde X, protože datový prvek v mezipaměti P2 zastaral.
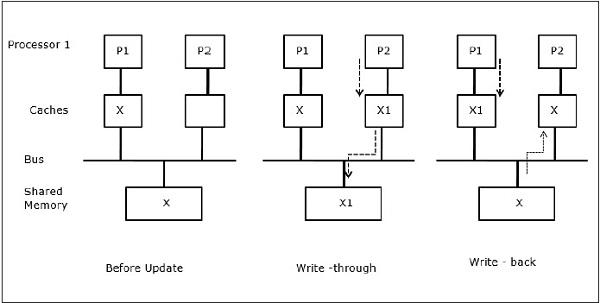
Migrace procesů
V první fázi má mezipaměť P1 datový prvek X, zatímco P2 nemá nic. Proces na P2 nejprve zapisuje na X a poté migruje na P1. Nyní proces začne číst datový prvek X, ale protože procesor P1 má zastaralá data, proces je nemůže číst. Proces na P1 tedy zapisuje do datového prvku X a poté migruje na P2. Po migraci začne proces na P2 číst datový prvek X, ale v hlavní paměti najde zastaralou verzi X.
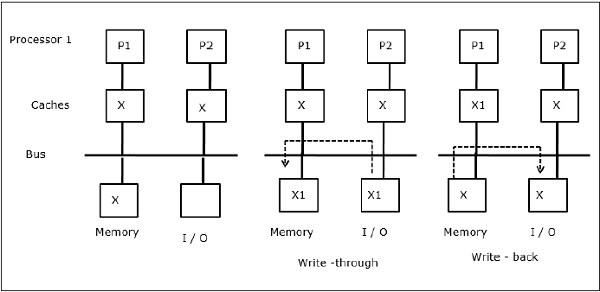
I/O činnost
Jak je znázorněno na obrázku, ve dvouprocesorové víceprocesorové architektuře je na sběrnici přidáno I/O zařízení. Na začátku obsahují obě mezipaměti datový prvek X. Když I/O zařízení obdrží nový prvek X, uloží jej přímo do hlavní paměti. Když se nyní P1 nebo P2 (předpokládejme, že P1) pokusí přečíst prvek X, získá zastaralou kopii. P1 tedy zapisuje do prvku X. Nyní, když se I/O zařízení pokusí přenést X, získá neaktuální kopii.
Jednotný přístup do paměti (UMA)
Architektura jednotného přístupu do paměti (UMA) znamená, že sdílená paměť je stejná pro všechny procesory v systému. Oblíbenou třídou strojů UMA, které se běžně používají pro (souborové) servery, jsou takzvané symetrické víceprocesory (SMP). V SMP jsou všechny systémové prostředky, jako je paměť, disky, další vstupně-výstupní zařízení atd. přístupné procesorům jednotným způsobem.
Non-Uniform Memory Access (NUMA)
V architektuře NUMA existuje více clusterů SMP, které mají vnitřní nepřímou/sdílenou síť a jsou propojeny škálovatelnou sítí pro předávání zpráv. Architektura NUMA je tedy logicky sdílená fyzicky distribuovaná paměťová architektura.
V počítači NUMA určuje řadič mezipaměti procesoru, zda je odkaz na paměť lokální nebo vzdálený. Pro snížení počtu vzdálených přístupů do paměti se v architektuře NUMA obvykle používají procesory s mezipamětí, které mohou vzdálená data ukládat do mezipaměti. Při použití mezipaměti je však třeba zachovat koherenci mezipaměti. Proto se tyto systémy označují také jako CC-NUMA (Cache Coherent NUMA).
Architektura COMA (Cache Only Memory Architecture)
Stroje COMA jsou podobné strojům NUMA, pouze s tím rozdílem, že hlavní paměti strojů COMA fungují jako přímo mapované nebo set-asociativní cache. Datové bloky jsou hashovány na místo v DRAM cache podle svých adres. Data, která jsou načítána vzdáleně, jsou ve skutečnosti uložena v místní hlavní paměti. Datové bloky navíc nemají pevné domovské umístění, mohou se volně pohybovat po celém systému.
Architektury COMA mají většinou hierarchickou síť pro předávání zpráv. Přepínač v takovém stromu obsahuje adresář s datovými prvky jako svůj podstrom. Protože data nemají domovské umístění, je třeba je explicitně vyhledávat. To znamená, že vzdálený přístup vyžaduje procházení podél přepínačů ve stromu, aby se v jejich adresářích vyhledala požadovaná data. Pokud tedy přepínač v síti obdrží od svého podstromu více požadavků na stejná data, spojí je do jediného požadavku, který je odeslán nadřízenému přepínači. Když se požadovaná data vrátí, přepínač odešle několik jejich kopií dolů do svého podstromu.
COMA versus CC-NUMA
Následují rozdíly mezi COMA a CC-NUMA.
-
COMA bývá flexibilnější než CC-NUMA, protože COMA transparentně podporuje migraci a replikaci dat bez potřeby operačního systému.
-
StrojeCOMA jsou drahé a složité na sestavení, protože potřebují nestandardní hardware pro správu paměti a protokol koherence je obtížněji implementovatelný.
-
Vzdálené přístupy v COMA jsou často pomalejší než v CC-NUMA, protože k nalezení dat je třeba projít stromovou síť.
.