Při psaní jednostránkových aplikací je snadné a přirozené nechat se strhnout snahou vytvořit ideální prostředí pro nejběžnější typ uživatelů – jiné lidi, jako jsme my sami. Toto agresivní zaměření na jeden typ návštěvníků našich stránek může často nechat stranou jinou důležitou skupinu – crawlery a roboty používané vyhledávači, jako je Google. Tento průvodce vám ukáže, jak některé snadno implementovatelné osvědčené postupy a přechod na vykreslování na straně serveru mohou vaší aplikaci poskytnout to nejlepší z obou světů, pokud jde o uživatelské prostředí SPA a SEO.
Předpoklady
Předpokládá se pracovní znalost jazyka Angular 5+. Některé části příručky se zabývají Angular 6, ale jeho znalost není striktně vyžadována.
Mnoho neúmyslných chyb SEO, kterých se dopouštíme, pochází z myšlení, že vytváříme webové aplikace, nikoli webové stránky. Jaký je v tom rozdíl? Je to subjektivní rozdíl, ale řekl bych, že z hlediska zaměření úsilí:
- Webové aplikace se zaměřují na přirozené a intuitivní interakce pro uživatele
- Webové stránky se zaměřují na všeobecné zpřístupňování informací
Ale tyto dva koncepty se nemusí vzájemně vylučovat! Jednoduchým návratem ke kořenům pravidel tvorby webových stránek můžeme zachovat uhlazený vzhled SPA a umístit informace na ta správná místa, aby byl web ideální pro crawlery.
Neskrývejte obsah za interakce
Jednou ze zásad, na kterou je třeba myslet při návrhu komponent, je, že crawlery jsou tak trochu hloupé. Budou klikat na vaše kotvy, ale nebudou náhodně přejíždět po prvcích nebo klikat na div jen proto, že je v jeho obsahu napsáno „Přečtěte si více“. To se dostává do rozporu s jazykem Angular, kde je běžnou praxí skrývání informací „*ngif it out“. A v mnoha případech to dává smysl! Tuto praxi používáme, abychom zlepšili výkon aplikace tím, že potenciálně těžké komponenty nebudou jen tak sedět v neviditelné části stránky.
To však znamená, že pokud obsah na stránce skryjete pomocí chytrých interakcí, je pravděpodobné, že se s tímto obsahem crawler nikdy nesetká. Tento problém můžete zmírnit tím, že k ukrytí tohoto druhu obsahu jednoduše použijete CSS, nikoli *ngif. Chytré vyhledávače si samozřejmě všimnou, že je text skrytý, a pravděpodobně jej budou považovat za méně důležitý než viditelný text. Je to však lepší výsledek, než kdyby text nebyl v DOM vůbec přístupný. Příklad tohoto přístupu vypadá takto:
Nevytvářejte „virtuální kotvy“
Následující komponenta ukazuje anti-vzor, který často vídám v aplikacích Angular a kterému říkám „virtuální kotva“:
V podstatě jde o to, že obsluha kliknutí je připojena k něčemu, jako je značka <button> nebo <div>, a tato obsluha provede nějakou logiku a pak použije importovaný směrovač Angular Router pro přechod na jinou stránku. To je problematické ze dvou důvodů:
- Prohlížeči na tyto typy prvků pravděpodobně neklepnou, a i kdyby, nevytvoří odkaz mezi zdrojovou a cílovou stránkou.
- Brání to velmi pohodlné funkci „Otevřít v nové kartě“, kterou prohlížeče nativně poskytují skutečným značkám kotvy.
Namísto použití virtuálních kotev použijte skutečnou značku <a> se směrnicí routerlink. Pokud potřebujete před navigací provést dodatečnou logiku, můžete ke značce kotvy ještě přidat obsluhu kliknutí.
Nezapomínejte na nadpisy
Jednou ze zásad dobré SEO optimalizace je stanovení relativní důležitosti různých textů na stránce. Důležitým nástrojem ve výbavě tvůrce webu jsou k tomu nadpisy. Často se stává, že při návrhu hierarchie komponent aplikace Angular se na nadpisy úplně zapomíná; to, zda jsou, nebo nejsou obsaženy, neznamená ve výsledném produktu žádný vizuální rozdíl. Je to však něco, co je třeba vzít v úvahu, aby se prohlížeče zaměřily na správné části informací. Zvažte proto použití značek nadpisů tam, kde to dává smysl. Dbejte však na to, aby komponenty, které obsahují značky nadpisů, nemohly být uspořádány tak, že se <h1> objeví uvnitř <h2>.
Udělejte „Stránky s výsledky vyhledávání“ propojitelné
Vrátíme-li se k principu toho, jak jsou crawlery hloupé – vezměme si stránku s vyhledáváním pro společnost vyrábějící widgety. Crawler neuvidí textový vstup ve formuláři a nezadá něco jako „Toronto widgets“. Z koncepčního hlediska je pro zpřístupnění výsledků vyhledávání pro crawlery třeba udělat následující:
- Je třeba nastavit vyhledávací stránku, která přijímá parametry vyhledávání prostřednictvím cesty a/nebo dotazu.
- Odkazy na konkrétní vyhledávání, o kterých si myslíte, že by mohly být pro crawler zajímavé, je třeba přidat do mapy webu nebo jako kotevní odkazy na jiných stránkách webu.
Strategie kolem bodu č. 2 je mimo rozsah tohoto článku (Některé užitečné zdroje jsou https://yoast.com/internal-linking-for-seo-why-and-how/ a https://moz.com/learn/seo/internal-link). Důležité je, že komponenty a stránky pro vyhledávání by měly být navrženy s ohledem na bod č. 1, abyste mohli flexibilně vytvořit odkaz na jakýkoli možný druh vyhledávání a umožnit jeho vložení kamkoli chcete. To znamená importovat ActivatedRoute a reagovat na její změny v cestě a parametrech dotazu, abyste mohli řídit výsledky vyhledávání na své stránce, místo abyste se spoléhali pouze na své komponenty dotazu a filtrování na stránce.
Zajistěte, aby stránkování bylo propojitelné
Když už jsme u stránek s vyhledáváním, je důležité zajistit, aby stránkování bylo správně zpracováno tak, aby se prohledávače mohly dostat na každou jednotlivou stránku výsledků vyhledávání, pokud se tak rozhodnou. Existuje několik osvědčených postupů, kterými se můžete řídit, abyste to zajistili.
Pro zopakování předchozích bodů: nepoužívejte „virtuální kotvy“ pro odkazy „další“, „předchozí“ a „číslo stránky“. Pokud je crawler nevidí jako kotvy, může se stát, že se nikdy nepodívá na nic jiného než na vaši první stránku. Používejte pro ně skutečné značky <a> se značkou RouterLink. Také zahrňte stránkování jako volitelnou součást odkazovaných adres URL pro vyhledávání – často to bývá ve formě parametru dotazu page=.
Další nápovědu pro crawlery o stránkování webu můžete poskytnout přidáním relativních značek „prev“/“next“ <link>. Vysvětlení, proč mohou být užitečné, najdete na adrese: https://webmasters.googleblog.com/2011/09/pagination-with-relnext-and-relprev.html. Zde je příklad služby, která dokáže automaticky spravovat tyto značky <odkaz> způsobem přívětivým pro systém Angular:
Vložit dynamická metadata
Jednou z prvních věcí, které v nové aplikaci Angular provedeme, je úprava indexu.html souboru – nastavení favikony, přidání responzivních metaznaček a s největší pravděpodobností nastavení obsahu značek <title> a <meta name=“description“> na nějaké rozumné výchozí hodnoty pro vaši aplikaci. Pokud vám však záleží na tom, jak se vaše stránky zobrazují ve výsledcích vyhledávání, nemůžete u toho skončit. Na každé cestě pro vaši aplikaci byste měli dynamicky nastavit značky title a description tak, aby odpovídaly obsahu stránky. Pomůže to nejen vyhledávačům, ale i uživatelům, protože při sdílení odkazu na sociálních sítích se jim zobrazí informativní názvy karet prohlížeče, záložek a informace o náhledu. Níže uvedený úryvek ukazuje, jak je můžete aktualizovat způsobem přívětivým pro systém Angular pomocí tříd Meta a Title:
Test, zda crawlery neporušují váš kód
Některé knihovny nebo sady SDK třetích stran se buď vypnou, nebo je nelze načíst od jejich poskytovatele hostingu, pokud jsou zjištěni uživatelští agenti, kteří patří mezi crawlery vyhledávačů. Pokud některá část vaší funkčnosti závisí na těchto závislostech, měli byste poskytnout nouzové řešení pro závislosti, které znemožňují použití crawlerů. Vaše aplikace by se v těchto případech měla přinejmenším elegantně degradovat, nikoli zhroutit proces vykreslování klienta. Skvělým nástrojem pro testování interakce vašeho kódu s crawlery je testovací stránka Google Mobile Friendly: https://search.google.com/test/mobile-friendly. Hledejte výstup, jako je tento, který znamená, že je crawleru zablokován přístup k SDK:

Snížení velikosti balíčků v aplikaci Angular 6
Velikost balíčků v aplikacích Angular je známý problém, ale existuje mnoho optimalizací, které může vývojář provést, aby jej zmírnil, včetně používání sestavení AOT a konzervativního přístupu k zahrnutí knihoven třetích stran. Nicméně pro získání co nejmenších svazků Angular dnes vyžaduje upgrade na Angular 6. Důvodem je nutný souběžný upgrade na RXJS 6, který nabízí výrazné vylepšení schopnosti třepání stromu. Abyste toto vylepšení skutečně získali, je třeba splnit několik tvrdých požadavků na vaši aplikaci:
- Odstraňte knihovnu rxjs-compat (která je ve výchozím nastavení přidána v procesu upgradu na Angular 6) – tato knihovna zajistí zpětnou kompatibilitu vašeho kódu s RXJS 5, ale znemožní vylepšení třesení stromů.
- Zajistěte, aby všechny závislosti odkazovaly na Angular 6 a nepoužívaly knihovnu rxjs-compat.
- Importujte operátory RXJS po jednom místo ve velkém, abyste zajistili, že třesení stromů může dělat svou práci. Úplný návod k migraci najdete v části https://github.com/ReactiveX/rxjs/blob/master/docs_app/content/guide/v6/migration.md.
Renderování serveru
I po dodržení všech předchozích osvědčených postupů můžete zjistit, že váš web s rozhraním Angular není hodnocen tak vysoko, jak byste chtěli. Jedním z možných důvodů je jeden ze základních nedostatků rámců SPA v kontextu SEO – při vykreslování stránky se spoléhají na Javascript. Tento problém se může projevit dvěma způsoby:
- Ačkoli robot Google dokáže spustit Javascript, ne každý procházecí robot to dokáže. Těm, které to nedělají, budou všechny vaše stránky připadat v podstatě prázdné.
- Aby se na stránce zobrazil užitečný obsah, bude muset crawler počkat, než se stáhnou balíčky Javascriptů, než je engine rozebere, než se spustí kód a než se vrátí případné externí XHR – pak se v DOM objeví obsah. Ve srovnání s tradičnějšími jazyky vykreslovanými na serveru, kde jsou informace v DOM k dispozici ihned po vstupu dokumentu do prohlížeče, zde bude SPA pravděpodobně poněkud penalizován.
Naštěstí má Angular řešení tohoto problému, které umožňuje servírovat aplikaci v podobě vykreslené na serveru: Angular Universal (https://github.com/angular/universal). Typická implementace využívající toto řešení vypadá takto:
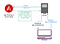
- Klient zadá požadavek na určitou url adresu vašemu aplikačnímu serveru.
- Server požadavek proxuje vykreslovací službě, kterou je vaše aplikace Angular běžící v kontejneru Node.js. Tato služba může být (ale nemusí) na stejném počítači jako aplikační server.
- Serverová verze aplikace vykreslí kompletní HTML a CSS pro požadovanou cestu a dotaz, včetně značek <script> pro stažení klientské aplikace Angular.
- Prohlížeč obdrží stránku a může okamžitě zobrazit obsah. Klientská aplikace se načítá asynchronně, a jakmile je připravena, znovu zobrazí aktuální stránku a nahradí statické HTML, které vykreslil server. Nyní se webová stránka chová jako SPA pro jakoukoli interakci do budoucna. Tento proces by měl být pro uživatele procházejícího web bezproblémový.
Tato kouzla však nejsou zadarmo. Několikrát jsem se v této příručce zmínil o tom, jak dělat věci „Angular-friendly“ způsobem. Ve skutečnosti jsem měl na mysli ‚Angular-rendering-friendly‘. Všechny osvědčené postupy, které jste si o Angularu přečetli, jako například nedotýkat se přímo DOM nebo omezit používání setTimeout, se vám vrátí, pokud jste je nedodrželi – v podobě pomalého načítání nebo dokonce zcela nefunkčních stránek. Rozsáhlý seznam univerzálních „gotchas“ najdete na adrese: https://github.com/angular/universal/blob/master/docs/gotchas.md
Hello Server
Existuje několik různých možností, jak zprovoznit projekt s aplikací Universal:
- Pro projekty Angular 5 můžete v existujícím projektu spustit následující příkaz:
ng generate universal server - Pro projekty Angular 6 zatím neexistuje oficiální příkaz CLI pro vytvoření funkčního projektu Universal s klientem a serverem. V existujícím projektu můžete spustit následující příkaz třetí strany:
ng add @ng-toolkit/universal - Tento repozitář můžete také naklonovat a použít jako výchozí bod pro svůj projekt nebo jej sloučit do existujícího projektu: https://github.com/angular/universal-starter
Dependency injection is your (server’s) friend
V typickém nastavení Angular Universal budete mít tři různé moduly aplikace – modul pouze pro prohlížeč, modul pouze pro server a sdílený modul. Toho můžeme využít ve svůj prospěch tak, že vytvoříme abstraktní služby, které naše komponenty injektují, a v každém modulu poskytneme implementace specifické pro klienta a server. Uvažujme tento příklad služby, která dokáže nastavit fokus na prvek: definujeme abstraktní službu, implementace pro klienta a server, poskytneme je v příslušných modulech a abstraktní službu importujeme do komponent.
Oprava závislostí nepřátelských serveru
Každá komponenta třetí strany, která nedodržuje osvědčené postupy systému Angular (tj. používá dokument nebo okno), způsobí pád serverového vykreslování jakékoli stránky, která tuto komponentu používá. Nejlepší možností je najít alternativu knihovny kompatibilní se systémem Universal. Někdy to však není možné nebo nahrazení závislosti brání časové omezení. V těchto případech existují dvě hlavní možnosti, jak zabránit rušení knihovny.
Na serveru můžete *ngIf vyřadit rušivé komponenty. Jednoduchým způsobem je vytvoření směrnice, která může rozhodnout, zda bude prvek vykreslen v závislosti na aktuální platformě:
Některé knihovny jsou problematičtější; samotný akt importu kódu se může pokusit použít závislosti pouze pro prohlížeč, což způsobí pád vykreslování na serveru. Příkladem je jakákoli knihovna, která importuje jquery jako závislost npm, místo aby očekávala, že spotřebitel bude mít jquery k dispozici v globálním rozsahu. Abychom se ujistili, že tyto knihovny nerozbijí server, musíme jednak *ngIf vyřadit provinilou komponentu, jednak vyřadit závislou knihovnu z WebPacku. Předpokládáme-li, že knihovna, která importuje jquery, se jmenuje ‚jquery-funpicker‘, můžeme napsat pravidlo webpack, jako je to níže, které ji vyřadí ze sestavení serveru:
To také vyžaduje umístění souboru s obsahem {} na adrese webpack/empty.json do struktury projektu. Výsledkem bude, že knihovna získá prázdnou implementaci pro svůj příkaz ‚jquery-funpicker‘ import, ale to nevadí, protože jsme tuto komponentu odstranili všude v serverové aplikaci pomocí naší nové směrnice.
Zlepšete výkon prohlížeče – neopakujte XHR
Součástí návrhu aplikace Universal je, že klientská verze aplikace znovu spustí veškerou logiku, která byla spuštěna na serveru pro vytvoření klientského zobrazení – včetně provedení stejných volání XHR na váš backend, které již provedlo vykreslení serveru! To způsobuje dodatečné zatížení vašeho backendu a dojem procházení, že stránka stále načítá obsah, i když po návratu těchto XHR bude pravděpodobně zobrazovat stejné informace. Pokud neexistuje obava ze stagnace dat, měli byste zabránit tomu, aby klientská aplikace duplikovala XHR, které již server provedl. Šikovným modulem, který s tím může pomoci, je TransferHttpCacheModule ze systému Angular: https://github.com/angular/universal/blob/master/docs/transfer-http.md
Pod kapotou modul TransferHttpCacheModule používá třídu TransferState, kterou lze použít pro jakýkoli přenos stavu ze serveru na klienta pro obecné účely:
Před vykreslením posunout čas do prvního bajtu k nule
Jednou věcí, kterou je třeba vzít v úvahu při použití služby Universal (nebo dokonce vykreslovací služby třetí strany, jako je https://prerender.io/), je, že stránka vykreslená serverem bude mít delší dobu, než první bajt dorazí do prohlížeče, než stránka vykreslená klientem. To by mělo dávat smysl, když uvážíte, že aby server doručil stránku vykreslenou klientem, musí v podstatě doručit pouze statickou stránku index.html. Universal nedokončí vykreslování, dokud není aplikace považována za „stabilní“. Stabilita v kontextu Angularu je komplikovaná, ale dva největší přispěvatelé ke zpoždění stability budou pravděpodobně:
- Outstanding XHRs
- Outstanding setTimeout calls
Pokud nemáte možnost výše uvedené dále optimalizovat, možností, jak zkrátit čas do prvního bajtu, je jednoduše předrenderovat některé nebo všechny stránky vaší aplikace a servírovat je z mezipaměti. Repo Angular Universal starter, na které je odkazováno dříve v této příručce, obsahuje implementaci pro pre-rendering. Jakmile máte předrenderované stránky, může být v závislosti na vaší architektuře řešením pro ukládání do mezipaměti něco jako Varnish, Redis, CDN nebo kombinace technologií. Odstraněním doby vykreslování z cesty odezvy ze serveru ke klientovi můžete poskytnout extrémně rychlé počáteční načítání stránek pro vyhledávače a lidské uživatele vaší aplikace.
Závěr
Mnoho technik uvedených v tomto článku není dobrých jen pro vyhledávače, ale vytváří také důvěrnější prostředí webových stránek pro vaše uživatele. Něco tak jednoduchého, jako jsou informativní názvy záložek pro různé stránky, znamená velký rozdíl za relativně nízké náklady na implementaci. Pokud přijmete vykreslování na straně serveru, nebudete se setkávat s neočekávanými produkčními nedostatky, například když se lidé pokusí sdílet váš web na sociálních sítích a zobrazí se jim prázdná miniatura.
Doufám, že se s vývojem webu dočkáme dne, kdy budou vyhledávače a servery pro snímání obrazovky komunikovat s webovými stránkami způsobem, který bude více odpovídat tomu, jak uživatelé komunikují na svých zařízeních – tím se webové aplikace odliší od starých webových stránek, které jsou nuceny napodobovat. Prozatím však musíme jako vývojáři nadále podporovat starý svět.

.