Secondo la definizione data in Wikipedia, il quartetto di Anscombe comprende quattro serie di dati che hanno proprietà statistiche semplici quasi identiche, ma che appaiono molto diverse quando vengono graficate. Ogni set di dati consiste di undici punti (x,y). Sono stati costruiti nel 1973 dallo statistico Francis Anscombe per dimostrare sia l’importanza di graficare i dati prima di analizzarli sia l’effetto degli outlier sulle proprietà statistiche.
Semplice comprensione:
Una volta Francis John “Frank” Anscombe, che era uno statistico di grande fama, trovò 4 serie di 11 punti di dati nel suo sogno e chiese al consiglio, come suo ultimo desiderio, di tracciare quei punti. Queste 4 serie di 11 punti dati sono riportate qui sotto.
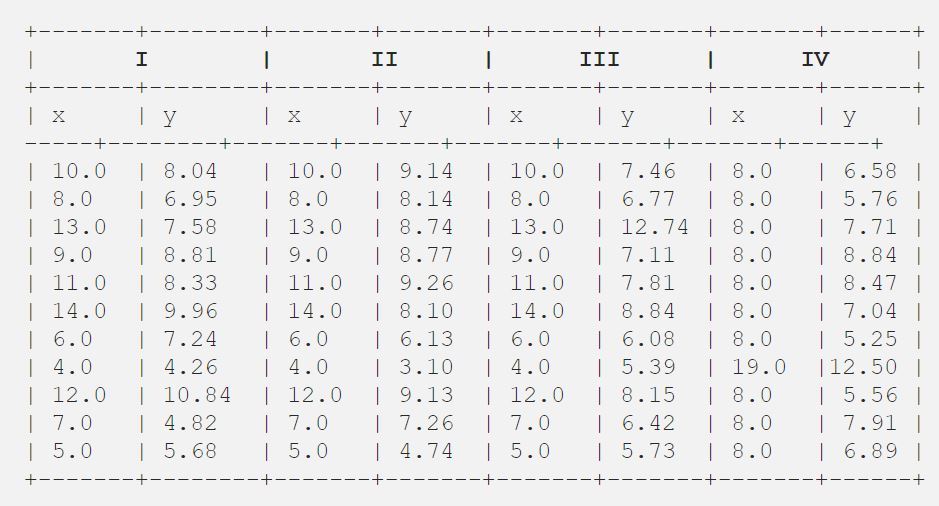
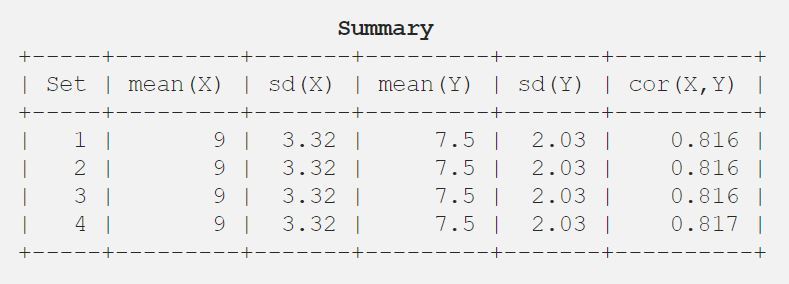
Dopo di che, il consiglio li ha analizzati usando solo statistiche descrittive e ha trovato la media, la deviazione standard e la correlazione tra x e y.
Scaricate il file csv qui.
Codice: Programma Python per trovare la media, la deviazione standard, e la correlazione tra x e y
import pandas as pd import statistics scipy.stats import pearsonr df = pd.read_csv("anscombe.csv") list1 = df list2 = df print('%.1f' % statistics.mean(list1)) print('%.2f' % statistics.stdev(list1)) print('%.1f' % statistics.mean(list2)) print('%.2f' % statistics.stdev(list2)) corr, _ = pearsonr(list1, list2) print('%.3f' % corr) Output:
9.03.327.52.030.816
Vi mostro il risultato in forma tabellare per una migliore comprensione.
Code: Programma Python per tracciare un grafico a dispersione
from matplotlib import pyplot as plt import pandas as pd df = pd.read_csv("anscombe.csv") list1 = df list2 = df plt.scatter(list1, list2) plt.show() Per la linea di regressione fare riferimento a questo.
Output:
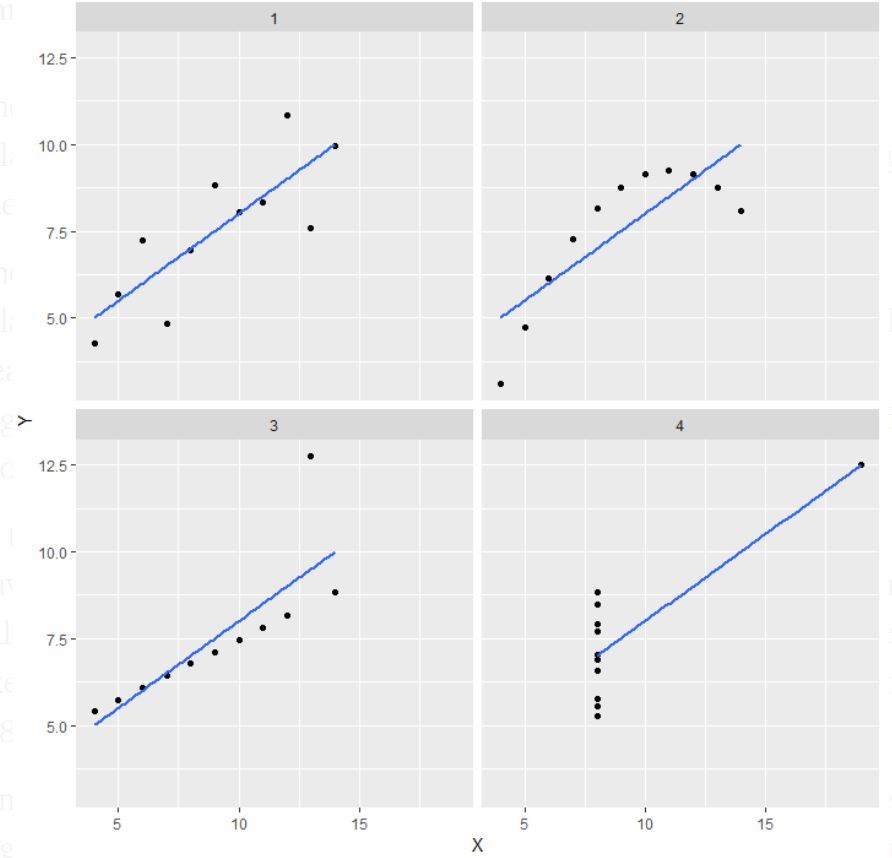
Nota: è menzionato nella definizione che il quartetto di Anscombe comprende quattro insiemi di dati che hanno proprietà statistiche semplici quasi identiche, ma che appaiono molto diversi quando vengono graficati.
Spiegazione di questo risultato:
- Nel primo (in alto a sinistra) se si guarda lo scatter plot si vedrà che sembra esserci una relazione lineare tra x e y.
- Nel secondo (in alto a destra) se si guarda questa figura si può concludere che esiste una relazione non lineare tra x e y.
- Nella terza (in basso a sinistra) si può dire che c’è una perfetta relazione lineare per tutti i punti dei dati tranne uno che sembra essere un outlier che è indicato essere molto lontano da quella linea.
- Infine, il quarto (in basso a destra) mostra un esempio in cui un punto ad alta leva è sufficiente per produrre un alto coefficiente di correlazione.
Applicazione:
Il quartetto è ancora spesso usato per illustrare l’importanza di guardare un insieme di dati graficamente prima di iniziare ad analizzare secondo un particolare tipo di relazione, e l’inadeguatezza delle proprietà statistiche di base per descrivere serie di dati realistici.