この章では、マルチキャッシュ不整合問題に対処するキャッシュコヒーレンスプロトコルを説明する。
キャッシュコヒーレンス問題
マルチプロセッサシステムでは、メモリ階層の隣接レベル間または同一レベル内でデータの不整合が発生することがある。 たとえば、キャッシュとメイン メモリが同じオブジェクトの矛盾したコピーを持つことがあります。
複数のプロセッサが並列に動作し、独立して複数のキャッシュが同じメモリ ブロックの異なるコピーを所有することがあるので、キャッシュ コヒーレンス問題が発生します。
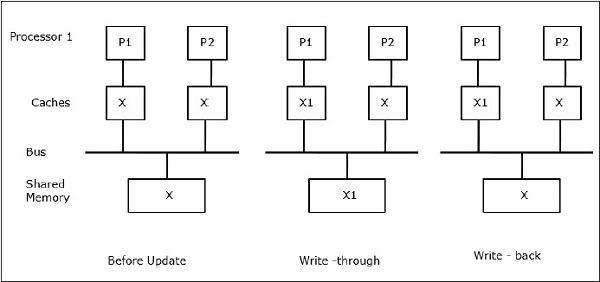
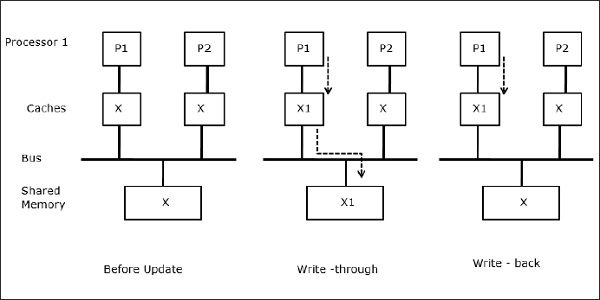
2 つのプロセッサ P1 と P2 によって参照されている共有データの要素を X とする。 はじめは、Xの3つのコピーが整合している。 プロセッサP1が新しいデータX1をキャッシュに書き込むと、ライトスルーポリシーにより、同じコピーが即座に共有メモリに書き込まれることになる。 この場合、キャッシュメモリと主記憶の間で不整合が発生する。 ライトバックポリシーを使用する場合、キャッシュ内の変更されたデータが置換または無効化されると、メインメモリが更新される。
一般に、不整合問題の原因は次の3つである –
- 書き込み可能なデータの共有
- プロセスの移行
- I/O 活動
Snoopyバスプロトコル
Snoopyプロトコルによりバスベースのメモリシステムを通してキャッシュ・メモリと共有メモリ間のデータ整合性が達成される。 キャッシュの一貫性を維持するために、Write-invalidateおよびWrite-updateポリシーが用いられる。
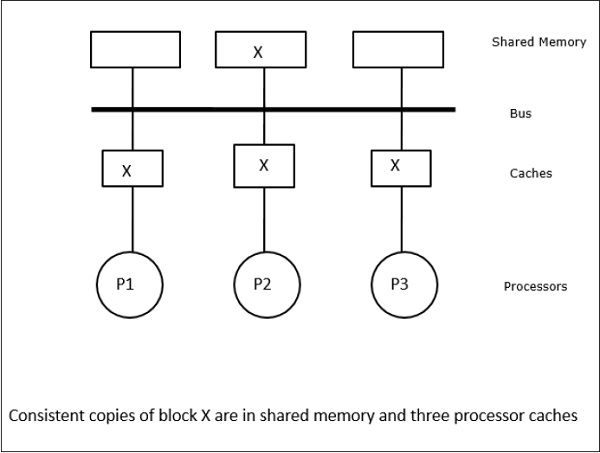
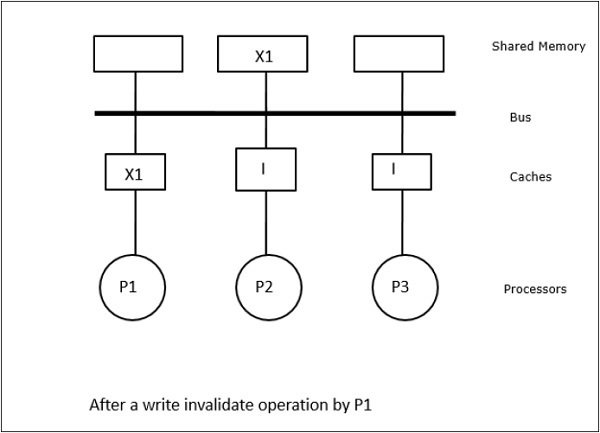
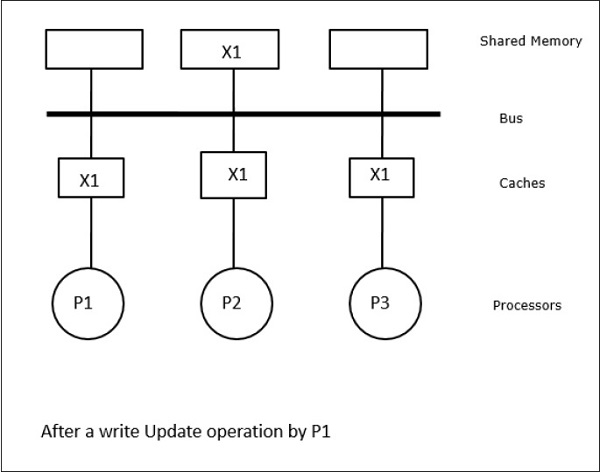
この場合、データ要素「X」のローカルキャッシュ・メモリ内と共有メモリ内の一貫したコピーを有する3つのプロセッサP1、P2、P3を持っている(図-a)。 プロセッサP1は、write-invalidateプロトコルを用いてX1をそのキャッシュメモリに書き込む。 そのため、他のすべてのコピーはバスを介して無効化される。 これは「I」で示される(図-b)。 無効化されたブロックは、ダーティとも呼ばれ、すなわち、使用されてはならない。 書き込み更新プロトコルは、バスを介してすべてのキャッシュコピーを更新する。 ライトバックキャッシュを使用することにより、メモリコピーも更新される(図-c)。
Cache Events and Actions
メモリアクセスおよび無効化コマンドの実行時に以下のイベントおよびアクションが生じる –
-
Read-miss -プロセッサがブロックを読み取りたいときにそれがキャッシュにない場合、読み取り失敗が発生する。 これにより、バスリード動作が開始されます。 ダーティ コピーが存在しない場合、一貫したコピーを持っているメイン メモリは、要求しているキャッシュ メモリにコピーを供給します。 ダーティコピーがリモートキャッシュメモリに存在する場合、そのキャッシュはメインメモリを拘束し、要求元のキャッシュメモリにコピーを送信する。 どちらの場合も、キャッシュ コピーは読み取りミスの後に有効状態になります。
-
Write-hit – コピーがダーティまたは予約状態の場合、書き込みがローカルで行われ、新しい状態はダーティになります。 新しい状態が有効な場合、write-invalidateコマンドがすべてのキャッシュにブロードキャストされ、そのコピーが無効になります。 共有メモリが書き込まれると、この最初の書き込みの後、結果の状態は予約されます。
-
Write-miss – プロセッサがローカルキャッシュメモリへの書き込みに失敗した場合、コピーはメインメモリから、またはダーティブロックでリモートキャッシュメモリから来る必要があります。 これは、read-invalidateコマンドを送信することにより、すべてのキャッシュ・コピーを無効にすることで行われます。
-
Read-hit – リードヒットは常にローカルキャッシュメモリで行われ、状態の遷移を引き起こしたり、無効化のためにスヌーピーバスを使用したりしません。
-
Block replacement – コピーがダーティな場合、ブロック置換法によってメインメモリにライトバックすることになっています。 しかし、コピーが有効状態か予約状態か無効状態のときは、置換は行われない。
ディレクトリベースのプロトコル
数百個のプロセッサからなる大規模マルチプロセッサの構築に多段ネットワークを用いることにより、snoopyキャッシュプロトコルもネットワーク機能に合わせて修正する必要がある。 ブロードキャストは多段ネットワークで実行するには非常に高価であるため、一貫性コマンドはブロックのコピーを保持しているキャッシュにのみ送信されます。
ディレクトリベースのプロトコルシステムでは、共有されるデータは、キャッシュ間の一貫性を維持する共通のディレクトリに配置される。 ここで、ディレクトリは、プロセッサが一次メモリからそのキャッシュ・メモリにエントリをロードする許可を求めるフィルタとして機能する。
ハードウェア同期メカニズム
同期は、データ制御の代わりに、同じまたは異なるプロセッサに存在する通信プロセス間で情報が交換される通信の特殊な形態である。 ほとんどのマルチプロセッサは、いくつかの同期プリミティブを実装するために、メモリの読み取り、書き込み、または読み取り-変更-書き込み操作などのアトミック操作を課すハードウェア機構を備えている。 アトミックなメモリ操作のほかに、いくつかのプロセッサ間割り込みも同期の目的で使用されます。
Cache Coherency in Shared Memory Machines
Maintaining cache coherency is a problem in multiprocessor system when the processors contain local cache memory. このシステムでは、異なるキャッシュ間のデータの不整合が容易に発生する。
主な懸念事項は以下のとおりです。
- Sharing of writable data
- Process migration
- I/O activity
Sharing of writable data
2 つのプロセッサ (P1 と P2) で同じデータ要素 (X) がそれらのローカルキャッシュにある場合、一方のプロセス (P1) でそのデータ要素 (X) に書き込みが行われているとする。 P1のキャッシュはライトスルーローカルキャッシュであるため、メインメモリも更新されます。
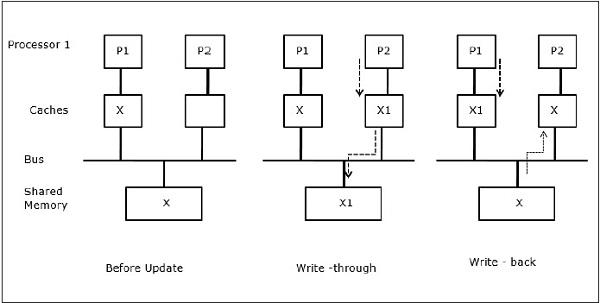
Process migration
最初の段階では、P1 のキャッシュにはデータ要素 X がありますが、P2 には何もありません。 P2上のプロセスはまずXに書き込み、その後P1へ移行する。 ここで、プロセスはデータ要素Xの読み取りを開始しますが、プロセッサP1には古いデータがあるため、プロセスはそれを読み取ることができません。 そこで、P1上のプロセスはデータエレメントXに書き込みを行い、P2へ移行する。
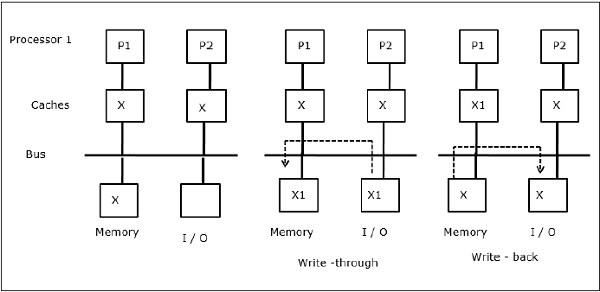
I/O活動
図に示すように、2プロセッサのマルチプロセッサアーキテクチャにおいて、I/Oデバイスがバスに追加される。 当初、両方のキャッシュはデータ要素Xを含んでおり、I/Oデバイスが新しい要素Xを受信すると、新しい要素をメインメモリに直接格納する。 ここで、P1またはP2(P1とする)が要素Xを読み取ろうとすると、古いコピーを取得する。 そこで、P1 は要素 X に書き込みます。今、I/O デバイスが X を送信しようとすると、古いコピーを取得します。
Uniform Memory Access (UMA)
Uniform Memory Access (UMA) architecture とは、システム内のすべてのプロセッサに対して同じ共有メモリを持つということです。 一般的に (ファイル) サーバーに使用される UMA マシンは、いわゆる対称型マルチプロセッサ (SMP) と呼ばれるクラスです。 SMP では、メモリ、ディスク、その他の I/O デバイスなどのすべてのシステム リソースは、プロセッサによって統一された方法でアクセスできます。
Non-Uniform Memory Access (NUMA)
NUMA アーキテクチャでは、内部間接/共有ネットワークを持つ複数の SMP クラスタがあり、それらは拡張可能なメッセージ パッシング ネットワークで接続されています。 NUMAマシンでは、プロセッサのキャッシュ・コントローラが、メモリ参照がSMPのメモリにローカルかリモートかを判断する。 リモート メモリ アクセスの数を減らすために、NUMA アーキテクチャは通常、リモート データをキャッシュできるキャッシング プロセッサを適用します。 しかし、キャッシュが絡むと、キャッシュコヒーレンシを維持する必要がある。 そのため、これらのシステムは CC-NUMA (Cache Coherent NUMA) とも呼ばれます。
Cache Only Memory Architecture (COMA)
COMA マシンは NUMA マシンに似ていますが、COMA マシンのメイン メモリが直接マッピングまたはセット アソシアティブ キャッシュとして機能するという唯一の相違点があります。 データ ブロックは、そのアドレスに従って DRAM キャッシュ内の場所にハッシュ化されます。 リモートでフェッチされたデータは、実際にはローカルのメインメモリに格納される。 さらに、データブロックは固定されたホームロケーションを持たず、システム中を自由に移動できる。
COMA アーキテクチャは、ほとんどが階層的なメッセージパッシングネットワークを備えている。 このようなツリーのスイッチは、データ要素を持つディレクトリをそのサブツリーとして含んでいる。 データはホームロケーションを持たないので、明示的に検索する必要があります。 つまり、リモートアクセスには、ツリー内のスイッチを走査して、必要なデータのディレクトリを検索する必要がある。 そのため、ネットワーク上のあるスイッチが、そのサブツリーから同じデータに対する複数のリクエストを受け取った場合、それらを1つのリクエストにまとめ、そのスイッチの親に送信する。
COMA vs CC-NUMA
以下は、COMAとCC-NUMAの違いです。
-
COMA では OS なしでデータの移行とレプリケーションを透過的にサポートするので、CC-NUMA より柔軟性が高い傾向があります。
-
COMA マシンは、非標準のメモリ管理ハードウェアを必要とし、コヒーレンシ プロトコルの実装が困難なため、構築するには高価で複雑なものとなっています。
-
COMA のリモート アクセスは、データを見つけるためにツリー ネットワークをトラバースする必要があるため、CC-NUMA のリモート アクセスよりもしばしば遅くなる。