Wikipediaの定義によると、Anscombeの四重奏は、ほぼ同一の単純な統計的特性を持ちながら、グラフにすると非常に異なって見える4つのデータセットで構成されています。 各データセットは11個の(x,y)点からなる。 統計学者フランシス・アンスコムが、データを分析する前にグラフ化することの重要性と、外れ値が統計的性質に及ぼす影響の両方を実証するために、1973年に作成したものである
単純な理解。
あるとき、偉大な統計学者であったFrancis John “Frank” Anscombeが、夢の中で4組の11点のデータポイントを見つけ、最後の願いとしてそれらのポイントをプロットするように評議会に依頼しました。
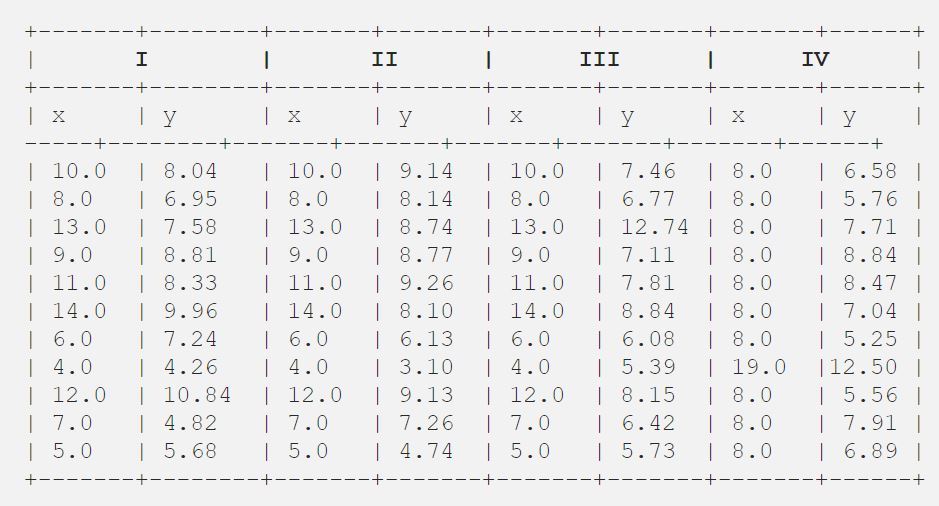
その後、評議会は記述統計のみを使って分析し、平均、標準偏差、xとyの相関を求めました。 平均値、標準偏差を求めるPythonプログラム。 とxとyの相関関係
import pandas as pd import statistics from scipy.stats import pearsonr df = pd.read_csv("anscombe.csv") list1 = df list2 = df print('%.1f' % statistics.mean(list1)) print('%.2f' % statistics.stdev(list1)) print('%.1f' % statistics.mean(list2)) print('%.2f' % statistics.stdev(list2)) corr, _ = pearsonr(list1, list2) print('%.3f' % corr) 出力されます。
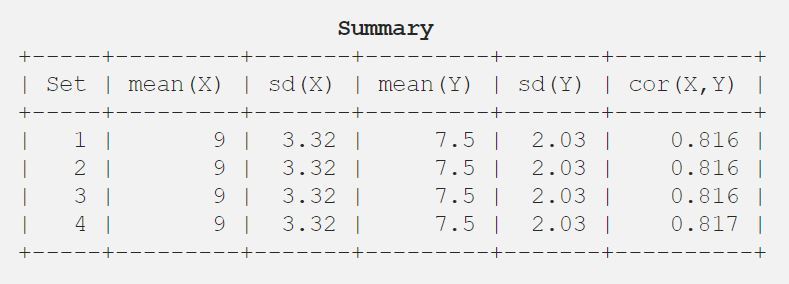
9.03.327.52.030.816
それでは、わかりやすいように表形式で結果をお見せしましょう。
Code: 散布図を描くPythonプログラム
from matplotlib import pyplot as plt import pandas as pd df = pd.read_csv("anscombe.csv") list1 = df list2 = df plt.scatter(list1, list2) plt.show() 回帰直線はこちらをご参照ください。
出力:
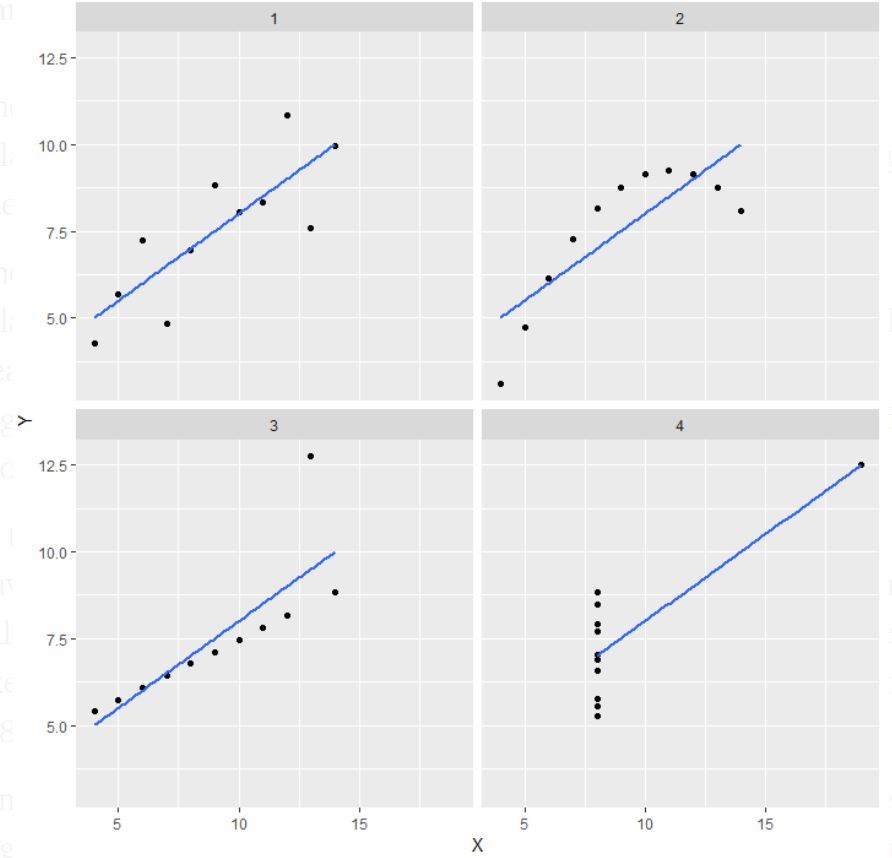
注:Anscombeのカルテットは、ほぼ同一の単純統計的特性を持ちながら、グラフにすると非常に異なって見える4つのデータセットからなることが定義で言及されています。
この出力の説明:
- 最初のもの(左上)で散布図を見ると、xとyの間に線形関係があるように見えます。
- 2番目のもの(右上)でこの図を見ると、xとyの間に非線形関係があると結論付けることができます。
- 3つ目の図(左下)では、直線から大きく離れている異常値と思われる1点を除いて、すべてのデータ点に完全な直線関係があると言えるでしょう。
- 最後に、4つ目(右下)は、高い相関係数を生み出すには、1つの高いレバレッジポイントがあれば十分だという例です。
応用:
四重奏は、特定のタイプの関係に従って分析を始める前にデータのセットをグラフで見ることの重要性と、現実的なデータセットを記述するための基本統計量の不十分さを説明するために今でもよく使われています。