Când scriem aplicații cu o singură pagină, este ușor și natural să ne lăsăm prinși în încercarea de a crea experiența ideală pentru cel mai comun tip de utilizatori – alți oameni ca noi. Această concentrare agresivă asupra unui singur tip de vizitator al site-ului nostru poate lăsa adesea pe dinafară un alt grup important – crawlerele și roboții utilizați de motoarele de căutare, cum ar fi Google. Acest ghid va arăta modul în care unele bune practici ușor de implementat și o mișcare către redarea pe partea serverului pot oferi aplicației dvs. cele mai bune din ambele lumi atunci când vine vorba de experiența utilizatorului SPA și SEO.
Precondiții
Se presupune o cunoaștere practică a Angular 5+. Unele părți ale ghidului se ocupă de Angular 6, dar cunoașterea acestuia nu este strict necesară.
Multe dintre greșelile SEO involuntare pe care le facem provin din mentalitatea că noi construim aplicații web, nu site-uri web. Care este diferența? Este o distincție subiectivă, dar aș spune că din punctul de vedere al focalizării efortului:
- Aplicațiile web se concentrează pe interacțiuni naturale și intuitive pentru utilizatori
- Site-urile web se concentrează pe punerea la dispoziție a informațiilor în general
Dar aceste două concepte nu trebuie să se excludă reciproc! Prin simpla reîntoarcere la rădăcinile regulilor de dezvoltare a site-urilor web, putem menține aspectul elegant al SPA-urilor și să punem informația în toate locurile potrivite pentru a realiza un site web ideal pentru crawlere.
Nu ascundeți conținutul în spatele interacțiunilor
Un principiu la care trebuie să ne gândim atunci când proiectăm componente este că crawlerele sunt oarecum proaste. Ei vor da clic pe ancorele dumneavoastră, dar nu vor trece la întâmplare peste elemente sau vor da clic pe un div doar pentru că în conținutul său scrie „Read More”. Acest lucru vine în contradicție cu Angular, unde o practică obișnuită pentru a ascunde informații este „*ngif it out”. Și de multe ori acest lucru are sens! Folosim această practică pentru a îmbunătăți performanța aplicației prin faptul că nu avem componente potențial grele care stau pur și simplu într-o parte nevizibilă a paginii.
Cu toate acestea, acest lucru înseamnă că, dacă ascundeți conținutul paginii dvs. prin interacțiuni inteligente, sunt șanse ca un crawler să nu vadă niciodată acel conținut. Puteți atenua acest lucru prin simpla utilizare a CSS în loc de *ngif pentru a ascunde acest tip de conținut. Desigur, crawlerele inteligente vor observa că textul este ascuns și va fi probabil ponderat ca fiind mai puțin important decât textul vizibil. Dar acesta este un rezultat mai bun decât ca textul să nu fie deloc accesibil în DOM. Un exemplu al acestei abordări arată astfel:
Nu creați „Ancore virtuale”
Componenta de mai jos arată un anti-pattern pe care îl văd foarte des în aplicațiile Angular și pe care îl numesc „ancoră virtuală”:
În principiu, ceea ce se întâmplă este că un manipulator de clic este atașat la ceva de genul unui tag <buton> sau <div> și acel manipulator va efectua o anumită logică, apoi va folosi Routerul Angular importat pentru a naviga către o altă pagină. Acest lucru este problematic din două motive:
- Crawlerii probabil că nu vor face clic pe aceste tipuri de elemente și, chiar dacă o fac, nu vor stabili o legătură între pagina sursă și pagina de destinație.
- Acest lucru împiedică funcția foarte convenabilă „Open in new tab” (Deschidere în tab nou) pe care browserele o oferă în mod nativ pentru etichetele de ancorare reale.
În loc să folosiți ancore virtuale, folosiți o etichetă reală <a> cu directiva routerlink. Dacă trebuie să efectuați o logică suplimentară înainte de navigare, puteți adăuga în continuare un gestionar de clic la eticheta de ancorare.
Nu uitați de titluri
Unul dintre principiile unui bun SEO este stabilirea importanței relative a diferitelor texte de pe o pagină. Un instrument important pentru acest lucru în trusa dezvoltatorului web sunt titlurile. Este obișnuit să se uite complet de titluri atunci când se proiectează ierarhia componentelor unei aplicații Angular; faptul că sunt sau nu incluse nu face nicio diferență vizuală în produsul final. Dar acesta este un aspect pe care trebuie să îl luați în considerare pentru a vă asigura că crawlerele se concentrează pe părțile corecte ale informațiilor dumneavoastră. Așadar, luați în considerare utilizarea etichetelor de titlu acolo unde are sens. Cu toate acestea, asigurați-vă că componentele care includ etichete de titlu nu pot fi aranjate în așa fel încât un <h1> să apară în interiorul unui <h2>.
Faceți ca „Search Result Pages” să poată fi legate
Returnând la principiul modului în care crawlerele sunt proaste – luați în considerare o pagină de căutare pentru o companie de widgeturi. Un crawler nu va vedea o intrare de text pe un formular și va tasta ceva de genul „Toronto widgets”. Din punct de vedere conceptual, pentru ca rezultatele căutării să fie disponibile pentru crawlere trebuie să se facă următoarele:
- Este necesară configurarea unei pagini de căutare care să accepte parametrii de căutare prin intermediul căii și/sau al interogării.
- Legături către căutări specifice pe care credeți că crawlerul le-ar putea găsi interesante trebuie adăugate la sitemap sau ca legături de ancorare pe alte pagini ale site-ului.
Strategia în jurul punctului 2 este în afara scopului acestui articol (Câteva resurse utile sunt https://yoast.com/internal-linking-for-seo-why-and-how/ și https://moz.com/learn/seo/internal-link). Ceea ce este important este că componentele și paginile de căutare ar trebui să fie proiectate ținând cont de punctul #1, astfel încât să aveți flexibilitatea de a crea o legătură către orice tip de căutare posibilă, permițând ca aceasta să fie injectată oriunde doriți. Acest lucru înseamnă să importați ActivatedRoute și să reacționați la modificările acesteia în calea și parametrii de interogare pentru a conduce rezultatele căutării pe pagina dumneavoastră, în loc să vă bazați doar pe componentele de interogare și filtrare de pe pagină.
Faceți ca paginarea să poată fi legată
În timp ce vorbim despre paginile de căutare, este important să vă asigurați că paginarea este gestionată corect, astfel încât crawlerele să poată accesa fiecare pagină a rezultatelor căutării dumneavoastră, dacă doresc acest lucru. Există câteva bune practici pe care le puteți urma pentru a vă asigura de acest lucru.
Pentru a reitera punctele anterioare: nu folosiți „Ancore virtuale” pentru legăturile „următor”, „anterior” și „numărul paginii”. Dacă un crawler nu le poate vedea ca fiind ancore, este posibil să nu se uite niciodată la nimic dincolo de prima dvs. pagină. Folosiți pentru acestea etichete reale <a> cu RouterLink. De asemenea, includeți paginarea ca parte opțională a URL-urilor dvs. de căutare cu link-uri – aceasta vine adesea sub forma unui parametru de interogare page=.
Puteți oferi indicii suplimentare crawlerelor despre paginarea site-ului dvs. prin adăugarea de tag-uri relative „prev”/”next” <link>. O explicație cu privire la motivul pentru care acestea pot fi utile poate fi găsită la: https://webmasters.googleblog.com/2011/09/pagination-with-relnext-and-relprev.html. Iată un exemplu de serviciu care poate gestiona automat aceste tag-uri <link> într-un mod prietenos pentru Angular:
Includeți metadate dinamice
Unul dintre primele lucruri pe care le facem la o nouă aplicație Angular este să facem ajustări la index.fișierul html – setarea faviconului, adăugarea de metaetichete responsive și, cel mai probabil, setarea conținutului etichetelor <title> și <meta name=”description”> la niște valori implicite sensibile pentru aplicația dumneavoastră. Dar dacă vă interesează cum apar paginile dvs. în rezultatele căutării, nu vă puteți opri aici. Pe fiecare traseu pentru aplicația dvs. ar trebui să setați în mod dinamic etichetele title și description pentru a se potrivi cu conținutul paginii. Acest lucru nu numai că va ajuta crawlerele, dar va ajuta și utilizatorii, deoarece aceștia vor putea să vadă titlurile informative ale filelor din browser, marcajele și informațiile de previzualizare atunci când partajează un link pe rețelele sociale. Fragmentul de mai jos arată cum puteți actualiza acestea într-un mod prietenos pentru Angular folosind clasele Meta și Title:
Test pentru crawlere care vă sparg codul
Câteva biblioteci terțe sau SDK-uri fie se închid, fie nu pot fi încărcate de la furnizorul lor de găzduire atunci când sunt detectați agenți de utilizator care aparțin crawlerelor motoarelor de căutare. Dacă o parte din funcționalitatea dvs. se bazează pe aceste dependențe, ar trebui să furnizați o soluție de rezervă pentru dependențele care nu permit crawlerele. Cel puțin, aplicația dvs. ar trebui să se degradeze în mod grațios în aceste cazuri, mai degrabă decât să prăbușească procesul de redare a clientului. Un instrument excelent pentru a testa interacțiunea codului dvs. cu crawlerele este pagina de testare Google Mobile Friendly: https://search.google.com/test/mobile-friendly. Căutați o ieșire ca aceasta care semnifică faptul că crawlerului i se blochează accesul la un SDK:

Reducerea dimensiunii pachetului cu Angular 6
Dimensiunea pachetului în aplicațiile Angular este o problemă bine-cunoscută, dar există multe optimizări pe care un dezvoltator le poate face pentru a o atenua, inclusiv prin utilizarea construcțiilor AOT și prin faptul că este conservator în ceea ce privește includerea de biblioteci terțe. Cu toate acestea, pentru a obține cele mai mici pachete Angular posibile în prezent, este necesară actualizarea la Angular 6. Motivul pentru aceasta este actualizarea paralelă necesară la RXJS 6, care oferă îmbunătățiri semnificative în ceea ce privește capacitatea de scuturare a arborelui. Pentru a obține efectiv această îmbunătățire, există câteva cerințe dificile pentru aplicația dvs.:
- Îndepărtați biblioteca rxjs-compat (care este adăugată în mod implicit în procesul de actualizare la Angular 6) – această bibliotecă face ca codul dvs. să fie compatibil cu RXJS 5, dar înfrânge îmbunătățirile de tree-shaking.
- Asigurați-vă că toate dependențele fac referire la Angular 6 și nu folosesc biblioteca rxjs-compat.
- Importați operatorii RXJS unul câte unul în loc să importați en-gros pentru a vă asigura că tree shaking își poate face treaba. Consultați https://github.com/ReactiveX/rxjs/blob/master/docs_app/content/guide/v6/migration.md pentru un ghid complet privind migrarea.
Rendare pe server
Chiar și după ce ați urmat toate cele mai bune practici precedente, este posibil să constatați că site-ul dvs. web Angular nu este clasat atât de sus pe cât v-ați dori să fie. Un posibil motiv pentru acest lucru este unul dintre defectele fundamentale ale cadrelor SPA în contextul SEO – acestea se bazează pe Javascript pentru a reda pagina. Această problemă se poate manifesta în două moduri:
- În timp ce Googlebot poate executa Javascript, nu orice crawler o va face. Pentru cei care nu o fac, toate paginile dvs. vor părea în esență goale pentru ei.
- Pentru ca o pagină să afișeze conținut util, crawlerul va trebui să aștepte ca pachetele Javascript să se descarce, motorul să le analizeze, codul să ruleze și orice XHR-uri externe să se întoarcă – apoi va exista conținut în DOM. În comparație cu limbajele mai tradiționale redate pe server, în care informațiile sunt disponibile în DOM imediat ce documentul ajunge în browser, un SPA este probabil să fie oarecum penalizat aici.
Din fericire, Angular are o soluție la această problemă care permite servirea unei aplicații într-o formă redată pe server: Angular Universal (https://github.com/angular/universal). O implementare tipică care utilizează această soluție arată astfel:
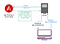
- Un client face o cerere pentru o anumită adresă URL către serverul dvs. de aplicații.
- Serverele proxyizează cererea către un serviciu de redare care este aplicația dvs. Angular care rulează într-un container Node.js. Acest serviciu ar putea fi (dar nu este neapărat) pe aceeași mașină ca și serverul de aplicații.
- Versiunea server a aplicației redă complet HTML și CSS pentru calea și interogarea solicitată, inclusiv tag-urile <script> pentru a descărca aplicația Angular a clientului.
- Browserul primește pagina și poate afișa conținutul imediat. Aplicația client se încarcă în mod asincron și, odată ce este gata, redevine pagina curentă și înlocuiește HTML-ul static pe care l-a redat serverul. Acum, site-ul web se comportă ca un SPA pentru orice interacțiune care merge mai departe. Acest proces ar trebui să fie fără cusur pentru un utilizator care navighează pe site.
Această magie nu este însă gratuită. De câteva ori în acest ghid am menționat cum să fac lucrurile într-un mod „Angular-friendly”. Ceea ce am vrut să spun de fapt a fost ‘Angular server-rendering-friendly’. Toate cele mai bune practici pe care le citiți despre Angular, cum ar fi să nu atingeți direct DOM-ul sau să limitați utilizarea setTimeout, se vor întoarce împotriva dvs. dacă nu le-ați urmat – sub forma unei încărcări lente sau chiar a unor pagini complet rupte. O listă extinsă de „gotchas” universale poate fi găsită la: https://github.com/angular/universal/blob/master/docs/gotchas.md
Hello Server
Există câteva opțiuni diferite pentru a face un proiect să funcționeze cu Universal:
- Pentru proiectele Angular 5 puteți rula următoarea comandă într-un proiect existent:
ng generate universal server - Pentru proiectele Angular 6 nu există încă o comandă CLI oficială pentru a crea un proiect Universal funcțional cu un client și un server. Puteți rula următoarea comandă terță parte într-un proiect existent:
ng add @ng-toolkit/universal - Puteți, de asemenea, clona acest depozit pentru a-l folosi ca punct de plecare pentru proiectul dvs. sau pentru a-l îmbina într-unul existent: https://github.com/angular/universal-starter
Injecția de dependență este prietenul tău (al serverului)
Într-o configurație tipică Angular Universal veți avea trei module de aplicație diferite – un modul doar pentru browser, un modul doar pentru server și un modul partajat. Putem folosi acest lucru în avantajul nostru, creând servicii abstracte pe care componentele noastre le injectează și furnizând implementări specifice clientului și serverului în fiecare modul. Luați în considerare acest exemplu de serviciu care poate seta focusul pe un element: definim un serviciu abstract, implementări pentru client și server, le furnizăm în modulele lor respective și importăm serviciul abstract în componente.
Fixarea dependențelor ostile serverului
Care componentă terță parte care nu respectă cele mai bune practici Angular (de exemplu, utilizează document sau fereastră) va bloca redarea pe server a oricărei pagini care utilizează acea componentă. Cea mai bună opțiune este să găsiți o alternativă compatibilă cu Universal la bibliotecă. Uneori, acest lucru nu este posibil sau constrângerile de timp împiedică înlocuirea dependenței. În aceste cazuri, există două opțiuni principale pentru a împiedica biblioteca să interfereze.
Puteți *ngIf out componentele incriminate de pe server. O modalitate ușoară de a face acest lucru este de a crea o directivă care poate decide dacă un element va fi redat în funcție de platforma curentă:
Câteva biblioteci sunt mai problematice; simplul act de import al codului poate foarte bine să încerce să folosească dependențe doar pentru browser care vor bloca redarea pe server. Un exemplu este orice bibliotecă care importă jquery ca o dependență npm, în loc să se aștepte ca consumatorul să aibă jquery disponibil în domeniul global. Pentru a ne asigura că aceste biblioteci nu strică serverul, trebuie atât să *ngIf eliminăm componenta incriminată, cât și să eliminăm biblioteca dependentă din webpack. Presupunând că biblioteca care importă jquery se numește „jquery-funpicker”, putem scrie o regulă webpack ca cea de mai jos pentru a o scoate din compilarea serverului:
Aceasta necesită, de asemenea, plasarea unui fișier cu conținutul {} la webpack/empty.json în structura proiectului dvs. Rezultatul va fi că biblioteca va primi o implementare goală pentru declarația de import „jquery-funpicker”, dar nu contează, deoarece am eliminat această componentă de peste tot din aplicația server cu noua noastră directivă.
Îmbunătățiți performanța browserului – nu repetați XHR-urile
O parte din designul Universal este că versiunea client a aplicației va rula din nou toată logica care a fost executată pe server pentru a crea vizualizarea clientului – inclusiv efectuarea acelorași apeluri XHR către back-end-ul dvs. pe care randarea serverului le-a făcut deja! Acest lucru creează o sarcină suplimentară pentru back-end-ul dvs. și o percepție pentru crawlere că pagina încă încarcă conținut, chiar dacă va afișa probabil aceleași informații după ce se vor întoarce acele XHR-uri. Cu excepția cazului în care există un motiv de îngrijorare în ceea ce privește lipsa de stabilitate a datelor, ar trebui să împiedicați aplicația client să duplice XHR-urile deja efectuate de server. TransferHttpCacheModule de la Angular este un modul la îndemână care vă poate ajuta în acest sens: https://github.com/angular/universal/blob/master/docs/transfer-http.md
Dincolo de capotă, TransferHttpCacheModule folosește clasa TransferState care poate fi utilizată pentru orice transfer de stare cu scop general de la server la client:
Pre renderizare pentru a muta timpul până la primul octet spre zero
Un lucru care trebuie luat în considerare atunci când se utilizează Universal (sau chiar un serviciu de redare terță parte, cum ar fi https://prerender.io/) este că o pagină redată de server va avea un timp mai lung înainte ca primul octet să ajungă la browser decât o pagină redată de client. Acest lucru ar trebui să aibă sens dacă vă gândiți că, pentru ca un server să livreze o pagină randată de client, în esență trebuie doar să livreze o pagină index.html statică. Universal nu va finaliza o redare până când aplicația nu este considerată „stabilă”. Stabilitatea în contextul Angular este complicată, dar cei mai mari doi factori care contribuie la întârzierea stabilității vor fi probabil:
- XHR-uri nerezolvate
- Apeluri setTimeout nerezolvate
Dacă nu aveți nicio modalitate de a optimiza mai mult cele de mai sus, o opțiune pentru a reduce timpul până la primul octet este prin simpla preredare a unora sau a tuturor paginilor aplicației dvs. și servirea lor dintr-un cache. Repo-ul Angular Universal starter repo legat mai devreme în acest ghid vine cu o implementare pentru pre-rendering. Odată ce aveți paginile pre-redresate, în funcție de arhitectura dvs., o soluție de cache ar putea fi ceva precum Varnish, Redis, un CDN sau o combinație de tehnologii. Prin eliminarea timpului de randare din calea de răspuns de la server la client, puteți oferi încărcări inițiale de pagină extrem de rapide pentru crawlere și pentru utilizatorii umani ai aplicației dumneavoastră.
Concluzie
Multe dintre tehnicile din acest articol nu sunt bune doar pentru crawlerele motoarelor de căutare, ci creează o experiență mai familiară a site-ului web și pentru utilizatorii dumneavoastră. Ceva la fel de simplu ca și faptul de a avea titluri de file informative pentru diferite pagini face o lume de diferență pentru un cost de implementare relativ scăzut. Adoptând redarea pe partea serverului, nu vă veți lovi de lacune de producție neașteptate, cum ar fi oamenii care încearcă să partajeze site-ul dvs. pe rețelele de socializare și primesc o miniatură goală.
Pe măsură ce web-ul evoluează, sper că vom vedea o zi în care crawlerele și serverele de captură de ecran interacționează cu site-urile web într-un mod mai apropiat de modul în care utilizatorii interacționează pe dispozitivele lor – diferențiind aplicațiile web de site-urile web de odinioară pe care sunt forțate să le imite. Deocamdată însă, în calitate de dezvoltatori, trebuie să continuăm să susținem lumea veche.

.