În acest capitol, vom discuta protocoalele de coerență a cache-ului pentru a face față problemelor de inconsistență multicache.
Problema coerenței cache-ului
Într-un sistem multiprocesor, inconsecvența datelor poate apărea între nivelurile adiacente sau în cadrul aceluiași nivel al ierarhiei de memorie. De exemplu, memoria cache și memoria principală pot avea copii inconsecvente ale aceluiași obiect.
Cum mai multe procesoare funcționează în paralel și, în mod independent, mai multe memorii cache pot deține copii diferite ale aceluiași bloc de memorie, se creează problema coerenței cache. Schemele de coerență a cache-ului ajută la evitarea acestei probleme prin menținerea unei stări uniforme pentru fiecare bloc de date din memoria cache.
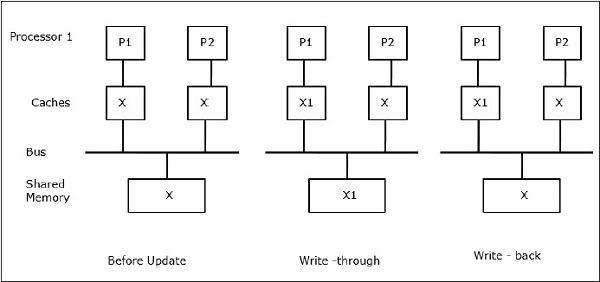
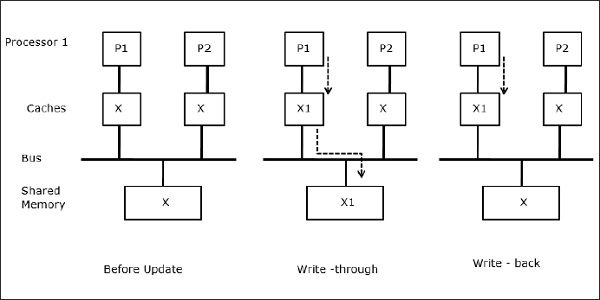
Să fie X un element de date partajate care a fost referit de două procesoare, P1 și P2. La început, trei copii ale lui X sunt consistente. În cazul în care procesorul P1 scrie o nouă dată X1 în memoria cache, prin utilizarea politicii write-through, aceeași copie va fi scrisă imediat în memoria partajată. În acest caz, apare o neconcordanță între memoria cache și memoria principală. În cazul în care se utilizează o politică de scriere înapoi, memoria principală va fi actualizată atunci când datele modificate din memoria cache sunt înlocuite sau invalidate.
În general, există trei surse de probleme de inconsistență –
- Împărtășirea datelor inscriptibile
- Migrația proceselor
- Activitatea de intrare/ieșire
Protocoale de bus noopy
Protocoalele noopy realizează consistența datelor între memoria cache și memoria partajată prin intermediul unui sistem de memorie bazat pe bus. Politicile de invalidare a scrierii și de actualizare a scrierii sunt utilizate pentru menținerea consistenței memoriei cache.
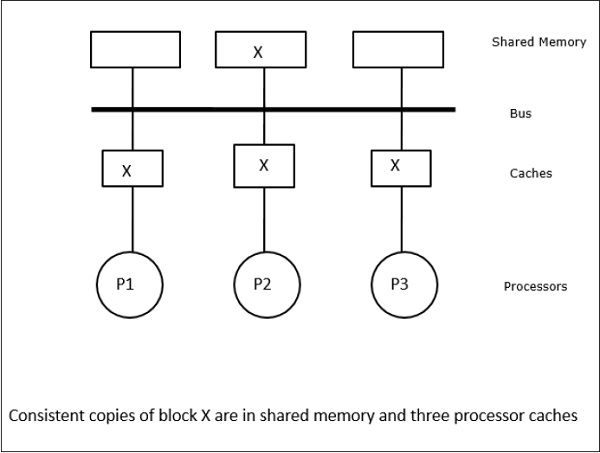
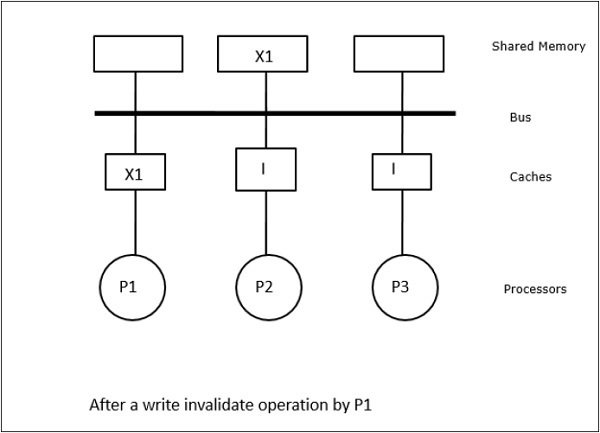
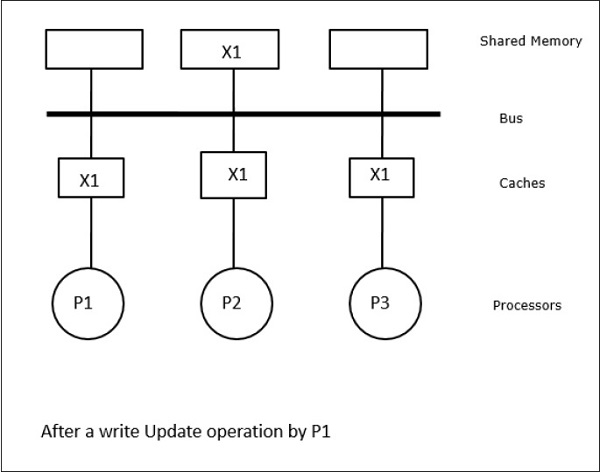
În acest caz, avem trei procesoare P1, P2 și P3 care au o copie consistentă a elementului de date „X” în memoria cache locală și în memoria partajată (figura-a). Procesorul P1 scrie X1 în memoria sa cache folosind protocolul write-invalidate. Astfel, toate celelalte copii sunt invalidate prin intermediul magistralei. Aceasta este notată cu „I” (figura-b). Blocurile invalidate sunt, de asemenea, cunoscute ca fiind murdare, adică nu trebuie utilizate. Protocolul de actualizare a scrierii actualizează toate copiile cache-ului prin intermediul magistralei. Prin utilizarea memoriei cache de scriere înapoi, copia de memorie este, de asemenea, actualizată (Figura-c).
Evenimente și acțiuni ale memoriei cache
La executarea comenzilor de accesare și invalidare a memoriei au loc următoarele evenimente și acțiuni –
-
Read-miss – Atunci când un procesor dorește să citească un bloc și acesta nu se află în memoria cache, are loc un read-miss. Aceasta inițiază o operațiune de citire pe magistrală. Dacă nu există o copie murdară, atunci memoria principală care are o copie consistentă, furnizează o copie către memoria cache solicitantă. În cazul în care există o copie murdară într-o memorie cache la distanță, acea memorie cache va reține memoria principală și va trimite o copie către memoria cache solicitantă. În ambele cazuri, copia cache va intra în stare validă după o citire ratată.
-
Scriere ratată – Dacă copia este în stare murdară sau rezervată, scrierea se face local, iar noua stare este murdară. Dacă noua stare este validă, comanda write-invalidate este transmisă către toate cache-urile, invalidând copiile acestora. Când se scrie în memoria partajată, starea rezultată este rezervată după această primă scriere.
-
Write-miss – Dacă un procesor nu reușește să scrie în memoria cache locală, copia trebuie să provină fie din memoria principală, fie dintr-o memorie cache la distanță cu un bloc murdar. Acest lucru se realizează prin trimiterea unei comenzi de citire-invalidare, care va invalida toate copiile din memoria cache. Apoi, copia locală este actualizată cu starea murdară.
-
Read-hit – Read-hit se efectuează întotdeauna în memoria cache locală fără a provoca o tranziție de stare sau a utiliza busul snoopy pentru invalidare.
-
Înlocuirea blocului – Atunci când o copie este murdară, aceasta trebuie să fie scrisă înapoi în memoria principală prin metoda de înlocuire a blocului. Cu toate acestea, atunci când copia este fie în stare validă, fie în stare rezervată sau invalidă, nu va avea loc nici o înlocuire.
Protocoale bazate pe directoare
Prin utilizarea unei rețele cu mai multe etape pentru construirea unui multiprocesor mare cu sute de procesoare, protocoalele cache-ului snoopy trebuie să fie modificate pentru a se adapta la capacitățile rețelei. Difuzarea fiind foarte costisitoare pentru a fi realizată într-o rețea multietajată, comenzile de coerență sunt trimise numai acelor cache-uri care păstrează o copie a blocului. Acesta este motivul pentru dezvoltarea protocoalelor bazate pe directoare pentru multiprocesoarele conectate în rețea.
Într-un sistem de protocoale bazate pe directoare, datele care urmează să fie partajate sunt plasate într-un director comun care menține coerența între ancorele. Aici, directorul acționează ca un filtru în care procesoarele cer permisiunea de a încărca o intrare din memoria primară în memoria sa cache. Dacă o intrare este modificată, directorul fie o actualizează, fie invalidează celelalte memorii cache cu acea intrare.
Mecanisme de sincronizare hardware
Sincronizarea este o formă specială de comunicare în care, în loc de control al datelor, se face schimb de informații între procesele care comunică și care rezidă în același procesor sau în procesoare diferite.
Sistemele multiprocesor folosesc mecanisme hardware pentru a implementa operații de sincronizare de nivel scăzut. Majoritatea multiprocesoarelor au mecanisme hardware pentru a impune operații atomice cum ar fi operațiile de citire, scriere în memorie sau de citire-modificare-scriere pentru a implementa unele primitive de sincronizare. În afară de operațiile atomice de memorie, unele întreruperi între procesoare sunt, de asemenea, utilizate în scopuri de sincronizare.
Coerența cache-ului în mașinile cu memorie partajată
Menținerea coerenței cache-ului este o problemă în sistemul multiprocesor atunci când procesoarele conțin memorie cache locală. Inconsecvența datelor între diferite memorii cache apare cu ușurință în acest sistem.
Principalele domenii de preocupare sunt –
- Sharing of writable data
- Process migration
- I/O activity
Sharing of writable data
Când două procesoare (P1 și P2) au același element de date (X) în memoria cache locală și un proces (P1) scrie în elementul de date (X), deoarece cache-urile sunt scrise prin cache-ul local al lui P1, memoria principală este, de asemenea, actualizată. Acum, când P2 încearcă să citească elementul de date (X), nu-l găsește pe X deoarece elementul de date din memoria cache a lui P2 a devenit depășit.
Migrarea proceselor
În prima etapă, memoria cache a lui P1 are elementul de date X, în timp ce P2 nu are nimic. Un proces de pe P2 scrie mai întâi pe X și apoi migrează către P1. Acum, procesul începe să citească elementul de date X, dar cum procesorul P1 are date învechite, procesul nu le poate citi. Astfel, un proces de pe P1 scrie pe elementul de date X și apoi migrează la P2. După migrare, un proces de pe P2 începe să citească elementul de date X, dar găsește o versiune neactualizată a lui X în memoria principală.
Migrarea proceselor
Activitatea I/O
După migrarea proceselor
Activitatea I/O
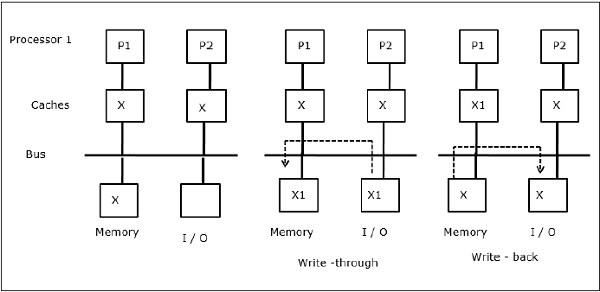
După cum este ilustrat în figură, un dispozitiv I/O este adăugat la magistrală într-o arhitectură multiprocesor cu două procesoare. La început, ambele memorii cache conțin elementul de date X. Atunci când dispozitivul I/O primește un nou element X, acesta stochează noul element direct în memoria principală. Acum, când P1 sau P2 (presupunem că P1) încearcă să citească elementul X, primește o copie depășită. Deci, P1 scrie în elementul X. Acum, dacă dispozitivul I/O încearcă să transmită X, primește o copie neactualizată.
Acces uniform la memorie (UMA)
Arhitectura UMA (Uniform Memory Access) înseamnă că memoria partajată este aceeași pentru toate procesoarele din sistem. Clasele populare de mașini UMA, care sunt utilizate în mod obișnuit pentru servere (de fișiere), sunt așa-numitele multiprocesoare simetrice (SMP). Într-un SMP, toate resursele sistemului, cum ar fi memoria, discurile, alte dispozitive de intrare/ieșire etc., sunt accesibile procesoarelor într-o manieră uniformă.
Non-Uniform Memory Access (NUMA)
În arhitectura NUMA, există mai multe clustere SMP care au o rețea internă indirectă/partajată, care sunt conectate într-o rețea scalabilă de trecere a mesajelor. Astfel, arhitectura NUMA este o arhitectură de memorie distribuită fizic partajată din punct de vedere logic.
Într-o mașină NUMA, controlerul cache al unui procesor determină dacă o referință de memorie este locală în memoria SMP sau este la distanță. Pentru a reduce numărul de accesări ale memoriei la distanță, arhitecturile NUMA aplică de obicei procesoare de cache care pot pune în cache datele la distanță. Dar atunci când sunt implicate memorii cache, trebuie menținută coerența cache-ului. Astfel, aceste sisteme sunt cunoscute și sub numele de CC-NUMA (Cache Coherent NUMA).
Arhitectura de memorie numai cu memorie cache (COMA)
Mașinile COMA sunt similare cu cele NUMA, cu singura diferență că memoriile principale ale mașinilor COMA acționează ca și memorii cache cu mapare directă sau cu asociație de seturi. Blocurile de date sunt hașurate la o locație din memoria cache DRAM în funcție de adresele lor. Datele care sunt preluate de la distanță sunt de fapt stocate în memoria principală locală. Mai mult, blocurile de date nu au o locație de origine fixă, ele se pot deplasa liber în tot sistemul.
Arhitecturile COMA au în cea mai mare parte o rețea ierarhică de trecere a mesajelor. Un comutator dintr-un astfel de arbore conține ca subarbore un director cu elemente de date. Deoarece datele nu au o locație de origine, ele trebuie să fie căutate în mod explicit. Acest lucru înseamnă că o accesare la distanță necesită o traversare de-a lungul comutatoarelor din arbore pentru a căuta în directoarele acestora datele necesare. Astfel, în cazul în care un comutator din rețea primește mai multe cereri de la subarborele său pentru aceleași date, acesta le combină într-o singură cerere, care este trimisă către părintele comutatorului. Când datele solicitate se întorc, comutatorul trimite mai multe copii ale acestora în josul subarborelui său.
COMA versus CC-NUMA
În continuare sunt prezentate diferențele dintre COMA și CC-NUMA.
-
COMA tinde să fie mai flexibil decât CC-NUMA deoarece COMA suportă în mod transparent migrarea și replicarea datelor fără a fi nevoie de sistemul de operare.
-
MașinileCOMA sunt costisitoare și complexe de construit deoarece au nevoie de hardware de gestionare a memoriei non-standard și protocolul de coerență este mai greu de implementat.
-
Accesele la distanță în COMA sunt adesea mai lente decât cele în CC-NUMA deoarece trebuie parcursă rețeaua arborescentă pentru a găsi datele.
.